互斥锁#
本节导读#
此前两节中,我们分别介绍了用户态和内核态的线程管理。相比进程模型,它们可以更加高效方便的进行协作。比如同进程下的线程共享进程的地址空间,它们可以直接通过读写内存中的共享变量来进行通信而不必进行繁琐且低效的进程间通信。然而,在方便的同时,这种做法也会产生一些问题。本节就让我们从一个简单的多线程计数器的例子入手来看看我们会遇到什么问题以及如何解决。
引子:多线程计数器#
我们知道,同进程下的线程共享进程的地址空间,因此它们均可以读写程序内的全局/静态数据。通过这种方式,线程可以非常方便的相互协作完成一项任务。下面是一个简单的例子,同学可以在 Linux/Windows 等系统上运行这段代码:
1// adder.rs
2
3static mut A: usize = 0;
4const THREAD_COUNT: usize = 4;
5const PER_THREAD: usize = 10000;
6fn main() {
7 let mut v = Vec::new();
8 for _ in 0..THREAD_COUNT {
9 v.push(std::thread::spawn(|| {
10 unsafe {
11 for _ in 0..PER_THREAD {
12 A = A + 1;
13 }
14 }
15 }));
16 }
17 for handle in v {
18 handle.join().unwrap();
19 }
20 println!("{}", unsafe { A });
21}
前一节中我们已经熟悉了多线程应用的编程方法。因此我们很容易看出这个程序开了 THREAD_COUNT 个线程,每个线程都将一个全局变量 A 加 1 ,次数为 PER_THREAD 次。从中可以看出多线程协作确实比较方便,因为我们只需将单线程上的代码(即第 11~13 行的主循环)提交给多个线程就从单线程得到了多线程版本。然而,这样确实能够达到我们预期的效果吗?
全局变量 A 的初始值为 0 ,而 THREAD_COUNT 个线程每个将其加 1 重复 PER_THREAD 次,因此当所有的线程均完成任务之后,我们预期 A 的值应该是二者的乘积即 40000 。让我们尝试运行一下这个程序,可以看到类似下面的结果:
$ rustc adder.rs
$ ./adder
40000
$ ./adder
17444
$ ./adder
36364
$ ./adder
39552
$ ./adder
21397
可以看到只有其中一次的结果是正确的,其他的情况下结果都比较小且各不相同,这是为什么呢?我们可以尝试分析一下哪些因素会影响到代码的执行结果,使得结果与我们的预期不同。
编译器在将源代码编译为汇编代码或者机器码的时候会进行一些优化。
操作系统在执行程序的时候会进行调度。
CPU 在执行指令的时候会进行一些调度或优化。
那么按照顺序首先来检查第一步,即编译器生成的汇编代码是否正确。可以用如下命令反汇编可执行文件 adder 生成汇编代码 adder.asm :
$ rustup component add llvm-tools-preview
$ rust-objdump -D adder > adder.asm
在 adder.asm 中找到传给每个线程的闭包函数(这部分是我们自己写的,更容易出错)的汇编代码:
1# adder.asm
2000000000000bce0 <_ZN5adder4main28_$u7b$$u7b$closure$u7d$$u7d$17hfcc06370a766a1c4E>:
3 bce0: subq $56, %rsp
4 bce4: movq $0, 8(%rsp)
5 bced: movq $10000, 16(%rsp) # imm = 0x2710
6 bcf6: movq 8(%rsp), %rdi
7 bcfb: movq 16(%rsp), %rsi
8 bd00: callq 0xb570 <_ZN63_$LT$I$u20$as$u20$core..iter..traits..collect..IntoIterator$GT$9into_iter17h0e9595229a318c79E>
9 bd05: movq %rax, 24(%rsp)
10 bd0a: movq %rdx, 32(%rsp)
11 bd0f: leaq 24(%rsp), %rdi
12 bd14: callq 0xb560 <_ZN4core4iter5range101_$LT$impl$u20$core..iter..traits..iterator..Iterator$u20$for$u20$core..ops..range..Range$LT$A$GT$$GT$4next17h703752eeba5b7a01E>
13 bd19: movq %rdx, 48(%rsp)
14 bd1e: movq %rax, 40(%rsp)
15 bd23: cmpq $0, 40(%rsp)
16 bd29: jne 0xbd30 <_ZN5adder4main28_$u7b$$u7b$closure$u7d$$u7d$17hfcc06370a766a1c4E+0x50>
17 bd2b: addq $56, %rsp
18 bd2f: retq
19 bd30: movq 328457(%rip), %rax # 0x5c040 <_ZN5adder1A17hce2f3c024bd1f707E>
20 bd37: addq $1, %rax
21 bd3b: movq %rax, (%rsp)
22 bd3f: setb %al
23 bd42: testb $1, %al
24 bd44: jne 0xbd53 <_ZN5adder4main28_$u7b$$u7b$closure$u7d$$u7d$17hfcc06370a766a1c4E+0x73>
25 bd46: movq (%rsp), %rax
26 bd4a: movq %rax, 328431(%rip) # 0x5c040 <_ZN5adder1A17hce2f3c024bd1f707E>
27 bd51: jmp 0xbd0f <_ZN5adder4main28_$u7b$$u7b$closure$u7d$$u7d$17hfcc06370a766a1c4E+0x2f>
28 bd53: leaq 242854(%rip), %rdi # 0x47200 <str.0>
29 bd5a: leaq 315511(%rip), %rdx # 0x58dd8 <writev@GLIBC_2.2.5+0x58dd8>
30 bd61: leaq -15080(%rip), %rax # 0x8280 <_ZN4core9panicking5panic17h73f802489c27713bE>
31 bd68: movl $28, %esi
32 bd6d: callq *%rax
33 bd6f: ud2
34 bd71: nopw %cs:(%rax,%rax)
35 bd7b: nopl (%rax,%rax)
虽然函数名经过了一些混淆,还是能看出这是程序 adder 的 main 函数中的一个闭包(Closure)。我们现在基于 x86_64 而不是 RISC-V 架构,因此会有一些不同:
指令的目标寄存器后置而不是像 RISC-V 一样放在最前面;
使用
%rax,%rdx,%rsi,%rdi作为 64 位通用寄存器,观察代码可以发现%rsi和%rdi用来传参,%rax和%rdx用来保存返回值;%rsp是 64 位栈指针,功能与 RISC-V 中的sp相同;%rip是 64 位指令指针,指向当前指令的下一条指令的地址,等同于我们之前介绍的 PC 寄存器。callq为函数调用,retq则为函数返回。
在了解了这些知识之后,我们可以尝试读一读代码:
第 3 行是在分配栈帧;
第 4~8 行准备参数,并调用标准库实现的
IntoIteratortrait 的into_iter方法将 Range 0..10000 转化为一个迭代器;第 9 行的
24(%rsp)应该保存的是生成的迭代器的地址;第 11 行开始进入主循环。第 11 行加载
24(%rsp)到%rdi作为参数并在第 12 行调用Iterator::next函数,返回值在%rdx和%rax中并被保存在栈上。我们知道Iterator::next返回的是一个Option<T>。观察第 15-16 行,当%rax里面的值不为 0 的时候就跳转到 0xbd30 ,否则就向下执行到第 17-18 行回收栈帧并退出。这意味着%rax如果为 0 的话说明返回的是None,这时迭代器已经用尽,就可以退出函数了。于是,主循环的次数为 10000 次就定下来了。0xbd30 (第 19 行)开始才真正进入
A=A+1的部分。第 19 行从虚拟地址 0x5c040(这就是全局变量A的地址)加载一个 usize 到寄存器%rax中;第 20 行将%rax加一;第 26 行将寄存器%rax的值写回到虚拟地址 0x5c040 中。也就是说A=A+1是通过这三条指令达成。第 27 行无条件跳转到 0xbd0f 也就是第 11 行,进入下一轮循环。
注解
Rust Tips: Rust 的无符号溢出是不可恢复错误
有兴趣的同学可以读一读第 21~24 行代码,它可以判断在将 %rax 加一的时候是否出现溢出(注意其中复用了 %rax ,因此有一次额外的保存/恢复)。如果出现溢出的话则会跳转到 0xbd53(第 28 行)直接 panic 。
从中我们可以看出,相比 C/C++ 来说 Rust 的确会生成更多的代码来针对算术溢出、数组越界的情况进行判断,但是这并不意味着在现代 CPU 上就会有很大的性能损失。如果可以确保不会出现溢出的情况,可以考虑使用 unsafe 的 usize::unchecked_add 来避免生成相关的判断代码并提高性能。
我们可以得出结论:编译器生成的汇编代码是符合我们的预期的。那么接下来进行第二步,操作系统的调度是否会影响结果的正确性呢?在具体分析之前,我们先对汇编代码进行简化,只保留直接与结果相关的部分。那么,可以看成每个线程进行 PER_THREAD 次操作,每次操作按顺序进行下面三个步骤:
使用访存指令,从全局变量
A的地址 addr 加载A当前的值到寄存器 reg;使用算术指令将寄存器 reg 的值加一;
使用访存指令,将 reg 的值写回到全局变量
A的地址 addr,至此A的值成功加一。
这是一个可以认为与具体指令集架构无关的过程。因为对于传统的计算机架构而言,在 ALU 上进行的算术指令需要以寄存器为载体,而不能直接在 RAM 上进行操作。在此基础上,我们可以建立简化版的线程执行模型,如下图所示:
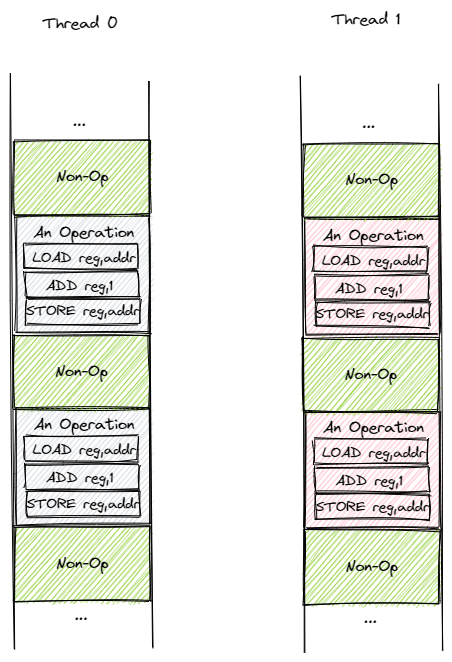
目前有两个线程 T0 和 T1 ,二者都是从上到下顺序执行。我们将 A=A+1 的操作打包成包含三条指令的一个块,剩下的绿色区域则表示与操作无关的那些指令。每个线程都会有一种幻觉就是它能够从头到尾独占 CPU 执行,但实际上操作系统会通过抢占式调度划分时间片使它们 交错 (Interleave) 运行。注意时钟中断可能在执行任意一条指令之后触发,因此时间片之间的边界可能是任意一条指令。下图是一种可能的时间片划分方式:
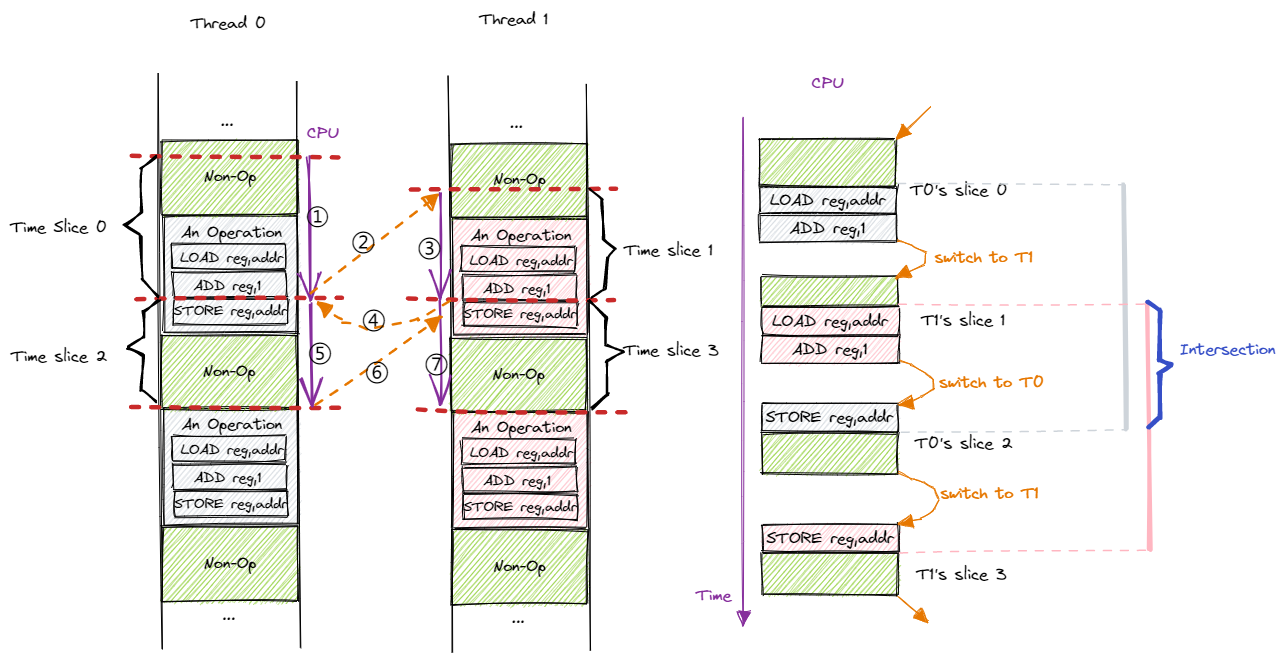
我们暂时只考虑单 CPU 的简单情况。按照时间顺序,CPU 依次执行 T0 的时间片 0、T1 的时间片 1、T0 的时间片 2 和 T1 的时间片 3,在相邻两个时间片之间会进行一次线程切换。注意到在这种划分方式中,两个线程各有一个操作块被划分到多个时间片完成。图片的右侧展示了 CPU 视角的指令执行过程,我们仅关注操作块中的指令,并尝试模拟一下:
动作 |
所属线程 |
寄存器 reg 的值(动作后) |
addr 处的值(动作后) |
|---|---|---|---|
切换到 T0 |
T0 |
v |
|
LOAD reg, addr |
T0 |
v |
v |
ADD reg, 1 |
T0 |
v+1 |
v |
T0 切换到 T1 |
T1 |
v |
|
LOAD reg, addr |
T1 |
v |
v |
ADD reg, 1 |
T1 |
v+1 |
v |
T1 切换到 T0 |
T0 |
v+1 |
v |
STORE reg, addr |
T0 |
v+1 |
v+1 |
T0 切换到 T1 |
T1 |
v+1 |
v+1 |
STORE reg, addr |
T1 |
v+1 |
v+1 |
T1 切换出去 |
v+1 |
假设开始之前全局变量 A 的值为 v ,而在这来自两个线程的四个时间片中包含了完整的两个 A=A+1 的操作块,那么结束之后 A 的值应该变成 v+2 。然而我们模拟下来的结果却是 v+1 ,这是为什么呢?首先需要说明的是,尽管两个线程都使用寄存器 reg 中转,但是它们之间并不会产生冲突,因为在线程切换的时候会对线程上下文进行保存与恢复,其中也包括寄存器 reg 。因此我们可以认为两个线程均有一份自己独占的寄存器。言归正传,我们从结果入手进行分析, A 最终的值来源于我们在这段时间对它进行的最后一次写入,这次写入由 T1 进行,但是为什么 T1 会写入 v+1 而不是 v+2 呢?从 T1 的视角来看,首先要读取 A 的值到 reg ,发现是 v ,这一点就很奇怪,好像此前 T0 什么都没做一样。而后 T1 将 reg 的值加一变成 v+1 ,于是最后写入的也是这个值。所以,问题的关键在于 T0 将自己的 reg 更新为 v+1 之后,还没来得及写回到 A ,就被操作系统切换到 T1 ,因此 T1 会看到 v 而不是 v+1 。等再切换回 T0 将 v+1 写入到 A 的时候已经为时已晚,因为已经过了关键的 T1 读取 A 的时间点了,于是这次写入无法对 T1 产生任何影响,也无法影响到最终的结果了。因此,在这种情况下,由于操作系统的抢占式调度,可以看到 T0 的 A=A+1 操作完全在做无用功,于是最终结果比期望少 1 。
从上个例子可以看出,操作系统的调度有可能使得两个线程上的操作块 交错 出现,也就是说两个操作块从开始到结束的时间区间存在交集。一旦出现这种情况,便会导致结果出现偏差。最终的结果取决于这种交错的情况出现多少次,如果完全没有出现则结果正确;否则出现次数越多,结果偏差越大。这就能够解释为什么我们每次运行 adder.rs 会得到不同的结果。这种运行结果 不确定 (Indeterminate),且取决于像是操作系统的调度顺序这种无法控制的外部事件的情况被称为 竞态条件 (Race Condition) 。在 adder.rs 中,竞态条件导致了我们预料之外的结果,因此它应当被认为是一个 bug 。
我们尝试更加形象的说明为什么操作块交错出现就会有问题。在写程序的时候,我们需要做的是通过软件控制一些资源,这些资源可能是软件资源或者硬件资源。软件资源可能包括保存在内存中的一些数据结构,硬件资源可能是内存的一部分或者某些 I/O 设备。在资源被初始化之后,资源处于一种合法(Valid)状态,这里的合法状态是指资源符合一些特定的约束条件从而具有该种资源所应该具有的特征。以我们耳熟能详的链表数据结构为例,一个合法的链表应该满足每个节点的 next 指针均为空指针或者指向合法的内存区域。同时,next 指针不能形成环。当然,实际上还有更多的约束条件,我们使用自然语言很难完全表述它们。总之,只有满足所有的约束条件,我们才说这是一个合法的链表。
每种资源可能都有多种不同的控制方式,每种控制方式称为对这种资源的一种操作。比如说,如果将链表看成一种资源,那么链表的插入和删除就是两种对链表的操作。每一种操作仅在资源处于合法状态时才能进行,且在操作完成之后保证资源仍旧处于合法状态。设想我们要实现链表的插入操作,这必须在待操作的数据结构是一个合法的链表这一前提下才能进行,不然我们的操作将完全没有意义。我们还需要保证插入之后链表依然合法,才称得上是正确的实现。但是资源并非任意时刻均处于合法状态。因为一般来说操作都比较复杂,会分成多个阶段多条指令完成。通常,处于合法状态的资源在操作时会变成不合法的 中间状态 (Intermediate State),待操作结束之后再重回合法状态。以我们的多线程计数器 adder.rs 为例,状态转移过程如下:
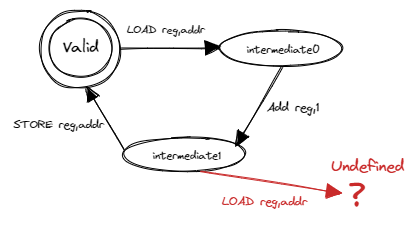
这里我们将全局变量 A 视为一种资源,操作 A=A+1 为一个三阶段操作。我们可以用有限状态自动机来描述资源 A 和操作 A=A+1 :状态机中一共有 3 种状态,一个合法状态和两个不合法的中间状态 0 和 1。对于每次操作,第一条指令 A 从合法状态转移到中间状态 0;第二条指令 A 从中间状态 0 转移到中间状态 1;第三条指令 A 从中间状态 1 转移回合法状态。将操作块交错的情况代入到状态机中,最开始切换到 T0 之前 A 处于合法状态,接下来切换到 T0 执行了第一、二条指令之后 A 转移到中间状态 1,而此时操作系统切换到 T1 , T1 又开始执行第一条指令。问题来了:我们发现中间状态 1 并没有定义此时再执行第一条指令应该如何转移。如果去执行的话,就会产生未定义行为并可能永远无法使 A 回到合法状态。不过,由于 adder.rs 中 A 只是一个整数,我们会发现 A 仍能回到合法状态,只是结果不对。如果换成一种复杂的数据结构,就会产生极其微妙且难以调试的结果。
我们可以发现多线程对共享资源的访问天然需求某种互斥性:当一个线程在对共享资源进行操作的时候,共享资源处在不合法的中间状态,如果此时其他线程开始操作会产生未定义行为。只有当操作完成,共享资源重新回到合法状态之后,之前操作的线程或者其他线程才能开始下一次操作。只有满足这种互斥性,才能保证多线程对共享资源的访问符合我们的预期。下面,我们换用操作系统中的术语进行表述:
共享资源 (Shared Resources) 是指多个线程均能够访问的资源。线程对于共享资源进行操作的那部分代码被称为 临界区 (Critical Section)。在多线程并发访问某种共享资源的时候,为了正确性,必须要满足 互斥 (Mutual Exclusion) 访问要求,即同一时间最多只能有一个线程在这种共享资源的临界区之内。这样才能保证当一个线程开始操作时,共享资源总是处于合法状态,这保证了操作是有意义的。如果能够做到互斥访问的话,我们 adder.rs 出现 bug 的根源————即对于 A 的操作可能交错出现的情况便能够被避免。
从 adder.rs 中可以看出,如果任由操作系统进行时间片切分和线程调度而不加任何特殊处理,是很难满足互斥访问要求的。那么应该如何实现互斥访问呢?接下来,我们将会尝试构建一组称之为 互斥锁 (Mutex,源于 Mut ual Ex clusion,简称为 锁 Lock) 的通用互斥原语来对临界区进行保护,从而在一般意义上保证互斥访问要求。这将是本节接下来的主要内容。
如果仅仅考虑 adder.rs 的话,其实不借助锁机制也能够解决问题。这是因为其中的共享资源为一个 64 位无符号整型,是一个十分简单的类型。对于这种原生类型,现代指令集架构额外提供一组 原子指令 (Atomic Instruction) ,在某些架构上只需一条原子指令就能完成包括访存、算术运算在内的一系列功能。这就是说 adder.rs 中的 A=A+1 操作其实只需一条原子指令就能完成。如果这样做的话,我们相当于 将临界区缩小为一条原子指令 ,这已经是处理器执行指令和时间片切分的最小单位,因此我们不使用任何保护手段也能满足互斥要求。修改之后的代码如下:
1// adder_fixed.rs
2
3use std::sync::atomic::{AtomicUsize, Ordering};
4static A: AtomicUsize = AtomicUsize::new(0);
5const THREAD_COUNT: usize = 4;
6const PER_THREAD: usize = 10000;
7fn main() {
8 let mut v = Vec::new();
9 for _ in 0..THREAD_COUNT {
10 v.push(std::thread::spawn(|| {
11 for _ in 0..PER_THREAD {
12 A.fetch_add(1, Ordering::Relaxed);
13 }
14 }));
15 }
16 for handle in v {
17 handle.join().unwrap();
18 }
19 println!("{}", A.load(Ordering::Relaxed));
20}
Rust 核心库在 core::sync::atomic 中提供了很多原子类型,比如我们这里可以使用 usize 对应的原子类型 AtomicUsize ,它支持很多原子操作。比如,第 12 行 fetch_add 的功能是将 A 的值加一并返回 A 之前的值,这其中涉及到读取内存、算术运算和写回内存,但是却只需要这一个操作就能同时完成。这种原子操作基于硬件提供的原子指令,硬件可以保证其 原子性 (Atomicity),含义是该操作的一系列功能要么全部完成,要么都不完成,而不会出现有些完成有些未完成的情况。原子性中的“原子”是为了强调操作中的各种功能作为一个整体不可分割的属性。这种由硬件提供的 原子指令是整个计算机系统中最根本的原子性和互斥性的来源 。无论软件执行了哪些指令,也无论 CPU 执行指令的时候出现了哪些中断/异常,又或者多个 CPU 同时访问内存中同一个位置这种情形,都不能破坏原子指令的原子性。
可惜的是,原子指令虽然强大,其应用范围却比较有限,通常它只能用来保护 单内存位置 上的简单操作,比如 A=A+1 这种操作。当资源是比较复杂的数据结构的时候它就无能为力了。当然,我们也不会指望硬件提供一条“原子地完成红黑树插入/删除”这种指令,毕竟这样的数据结构有无数种,硬件总不可能对每种可能的数据结构和每种可能的操作都提供一条指令,这样的硬件是不存在的。即使如此我们也没有必要担心,只要我们能够灵活使用原子指令来根据实际需求限制多线程对共享资源的并发访问,比如基于原子指令实现通用的锁机制来保证互斥访问,所有的并发访问问题就一定能够迎刃而解。
需要注意的是, adder.rs 的错误结果是多种因素共同导致的,这里我们深入分析的操作系统调度带来的影响只不过是其中之一,其实 CPU 的指令执行也会有影响。
注解
原子性
原子性的说法最常见于数据库领域的原子 事务 (Transaction) ,表示对于数据库的一次修改要么全部完成,要么没有任何影响,而不存在任何中间状态。事务模型可以保证数据库能够在出错时顺利恢复以及高并发访问的正确性。但其实原子性这个概念在很多不同领域均有应用且有不同内涵。
注解
Rust Tips: static mut 和 unsafe 的消失
TODO:
锁的简介#
锁机制的形态与功能#
我们提到为了保证多线程能够正确并发访问共享资源,可以使用一种叫做 锁 的通用机制来对线程操作共享资源的 临界区 进行保护。这里的锁和现实生活中的含义很接近。回想一下我们如何使用常见于理发店或者游泳馆更衣室的公共储物柜:首先需要找到一个没有上锁的柜子并将物品存放进去。接着我们锁上柜子并拔出插在锁孔上的钥匙妥善保管。最后,当我们想取出物品时,我们使用钥匙打开存放物品的柜子并将钥匙留在锁孔上以便他人使用。至此,完整的使用流程结束。
那么,如何使用类似的思路用锁机制保护临界区呢?锁是附加在一种共享资源上的一种标记,最简单的情况下它只需有两种状态:上锁和空闲。上锁状态表示此时已经有某个线程在该种共享资源的临界区中,故而为了正确性其他线程不能进入临界区。相反的,空闲状态则表示线程可以进入临界区。显然,线程成功进入临界区之后锁也需要从空闲转为上锁状态。锁的两个基本操作是 上锁 和 解锁 ,在线程进入临界区之前和退出临界区之后分别需要成功上锁和解锁。通过这种方式,我们就可以保证临界区的互斥性。在引入锁机制之后,线程访问共享资源的流程如下:
第一步上锁:线程进入临界区之前检查共享资源是否已经上锁。如果已经上锁的话,则需要 等待 持有钥匙的线程归还钥匙并解锁。接下来,线程尝试“抢”到钥匙,如果成功的话,线程将资源上锁,此时我们说该线程 获取到了锁 (或者说 持有锁或拿到了锁 )。最后线程拿走钥匙并进入临界区。此时资源进入上锁状态,其他线程不能进入临界区。
第二步在临界区内访问共享资源。只有持有共享资源锁的线程能够进入临界区,这就能够保证临界区的互斥性。
第三步解锁:线程离开临界区之后将资源解锁并归还钥匙,我们说线程 释放了锁 。此时资源回到空闲状态。
锁的使用方法#
Rust 在标准库中提供了互斥锁 std::sync::Mutex<T> ,它可以包裹一个类型为 T 的共享资源为它提供互斥访问。线程可以调用 Mutex<T>::lock 来获取锁,注意线程不一定立即就能拿到锁,所以它会等待持有锁的线程释放锁且自身抢到锁之后才会返回。其返回值为 std::sync::MutexGuard<T> (篇幅所限省略掉外层的 Result ),可以理解为前面描述中的一把钥匙,拿到它的线程也就拿到了锁,于是有资格独占共享资源并进入临界区。 MutexGuard<T> 提供内部可变性,可以看做可变引用 &mut T ,用来修改共享资源。它的另一种功能是用来开锁,它也是 RAII 风格的,在它被 drop 之后会将锁自动释放。
让我们看看如何使用 Mutex<T> 来更正 adder.rs :
1// adder_mutex0.rs
2
3use std::sync::Mutex;
4const THREAD_COUNT: usize = 4;
5const PER_THREAD: usize = 10000;
6static A: Mutex<usize> = Mutex::new(0);
7fn main() {
8 let mut v = Vec::new();
9 for _ in 0..THREAD_COUNT {
10 v.push(std::thread::spawn(|| {
11 for _ in 0..PER_THREAD {
12 let mut a_guard = A.lock().unwrap();
13 *a_guard = *a_guard + 1;
14 }
15 }));
16 }
17 for handle in v {
18 handle.join().unwrap();
19 }
20 println!("{}", *A.lock().unwrap());
21}
第 6 行我们将共享资源用 A 使用 Mutex<T> 包裹。第 12~14 行构成一次完整的受锁保护的临界区访问:第 12 行获取锁;第 13 行是临界区;第 14 行循环的一次迭代结束,第 12 行的 MutexGuard<T> 退出作用域,于是它被 drop 之后自动解锁。
在上面的做法中,锁以及被锁保护的共享资源被整合到一个数据结构中,这也是最为常见的做法。但在某些情况下,它们之间可以相互分离,参考下面的代码:
1// adder_mutex1.rs
2
3use std::sync::Mutex;
4static mut A: usize = 0;
5static LOCK: Mutex<bool> = Mutex::new(true);
6const THREAD_COUNT: usize = 4;
7const PER_THREAD: usize = 10000;
8fn main() {
9 let mut v = Vec::new();
10 for _ in 0..THREAD_COUNT {
11 v.push(std::thread::spawn(|| {
12 for _ in 0..PER_THREAD {
13 let _lock = LOCK.lock();
14 unsafe { A = A + 1; }
15 }
16 }));
17 }
18 for handle in v {
19 handle.join().unwrap();
20 }
21 println!("{}", unsafe { A });
22}
其中锁 LOCK 用来保护共享资源 A 。此处, LOCK 有用的仅有那个描述锁状态(可能是上锁或空闲)的标记,它内部包裹的值反而无关紧要,其类型 T 可以随意选择。可以看到在这种实现中,锁 LOCK 和共享资源 A 是分离开的,这样实现更加灵活,但是更容易由于编码错误而出现 bug 。
评价锁实现的指标#
锁机制有多种不同的实现。对于一种实现而言,我们常常用以下的指标来从多个维度评估这种实现是否能够正确、高效地达成锁这种互斥原语应有的功能:
忙则等待:意思是当一个线程持有了共享资源的锁,此时资源处于繁忙状态,这个时候其他线程必须等待拿着锁的线程将锁释放后才有进入临界区的机会。这其实就是互斥访问的另一种说法。这种互斥性是锁实现中最重要的也是必须做到的目标,不然共享资源访问的正确性会受到影响。
空闲则入 (在《操作系统概念》一书中也被称为 前进 Progress):若资源处于空闲状态且有若干线程尝试进入临界区,那么一定能够在有限时间内从这些线程中选出一个进入临界区。如果不满足空闲则入的话,可能导致即使资源空闲也没有线程能够进入临界区,对于锁来说是不可接受的。
有界等待 (Bounded Waiting):当线程获取锁失败的时候首先需要等待锁被释放,但这并不意味着此后它能够立即抢到被释放的锁,因为此时可能还有其他的线程也处于等待状态。于是它可能需要等待一轮、二轮、多轮才能拿到锁,甚至在极端情况下永远拿不到锁。 有界等待 要求每个线程在等待有限长时间后最终总能够拿到锁。相对的,线程可能永远无法拿到锁的情况被称之为 饥饿 (Starvation) 。这体现了锁实现分配共享资源给线程的 公平性 (Fairness) 。
让权等待(可选):线程如何进行等待实际上也大有学问。这里所说的让权等待是指需要等待的线程暂时主动或被动交出 CPU 使用权来让 CPU 做一些有意义的事情,这通常需要操作系统的支持。这样可以提升系统的总体效率。
总的来说,忙则等待、空闲则入和有界等待是一个合格的锁实现必须满足的要求,而让权等待则关系到锁机制的效率,是可选的。
这一小节我们介绍了锁的形态:一种附加在共享资源上的标记,需要区分当前是否有线程在该种资源的临界区中。它支持两种基本操作:上锁和解锁。接着我们还介绍了 Rust 标准库提供的互斥锁 Mutex<T> 并通过例子演示了它的用法。最后我们介绍了评价锁机制实现的一些指标,从中我们可以了解到怎样才可以称之为一个好的锁实现。接下来,我们将正式开始亲自动手根据上述需求尝试实现锁机制。
锁的纯用户态软件实现#
在本节中,我们仅考虑在用户态使用锁机制保证多线程对共享资源的互斥访问的情形。此时在实现锁机制的时候,应用的执行环境的多个部分都有可能给我们带来一些帮助,从上到下它们分别是:
用户态软件的一些函数库;
操作系统内核的支持;
相关硬件机制或特殊指令的支持。
为了简单起见,我们暂不考虑操作系统内核支持和硬件机制,看看能否仅基于用户态软件实现锁机制,如果无法实现或者实现得不好是由于哪些问题,应当如何改进。本节之前的例子 adder.rs 运行在我们的真实计算机上的 Linux/Windows 或其他操作系统上,不过当我们自己实现锁的时候,我们选择在一个比较简单的平台——即 Qemu 模拟出来的 单核 计算机上的我们自己实现支持多线程的“达科塔盗龙”操作系统上进行实现和测试。因为如果基于真实计算机和成熟的操作系统,多线程在 多核 上的执行模型比较复杂,为了正确实现需要了解很多相关知识。在 Qemu 上我们能最大限度简化问题,也同样能有机会讨论锁实现的一些核心问题。
基于 内核态的线程管理 ,我们可以在自己的“达科塔盗龙”操作系统上实现 adder.rs 。代码如下:
1// user/src/bin/adder.rs
2
3#![no_std]
4#![no_main]
5
6#[macro_use]
7extern crate user_lib;
8extern crate alloc;
9
10use alloc::vec::Vec;
11use core::ptr::addr_of_mut;
12use user_lib::{exit, get_time, thread_create, waittid};
13
14static mut A: usize = 0;
15const PER_THREAD_DEFAULT: usize = 10000;
16const THREAD_COUNT_DEFAULT: usize = 16;
17static mut PER_THREAD: usize = 0;
18
19unsafe fn critical_section(t: &mut usize) {
20 let a = addr_of_mut!(A);
21 let cur = a.read_volatile();
22 for _ in 0..500 {
23 *t = (*t) * (*t) % 10007;
24 }
25 a.write_volatile(cur + 1);
26}
27
28unsafe fn f() -> ! {
29 let mut t = 2usize;
30 for _ in 0..PER_THREAD {
31 critical_section(&mut t);
32 }
33 exit(t as i32)
34}
35
36#[unsafe(no_mangle)]
37pub fn main(argc: usize, argv: &[&str]) -> i32 {
38 let mut thread_count = THREAD_COUNT_DEFAULT;
39 let mut per_thread = PER_THREAD_DEFAULT;
40 if argc >= 2 {
41 thread_count = argv[1].parse().unwrap();
42 if argc >= 3 {
43 per_thread = argv[2].parse().unwrap();
44 }
45 }
46 unsafe { PER_THREAD = per_thread; }
47 let start = get_time();
48 let mut v = Vec::new();
49 for _ in 0..thread_count {
50 v.push(thread_create(linker_symbol_addr!(f), 0) as usize);
51 }
52 for tid in v.into_iter() {
53 waittid(tid);
54 }
55 println!("time cost is {}ms", get_time() - start);
56 assert_eq!(unsafe { A }, unsafe { PER_THREAD } * thread_count);
57 0
58}
这里共享资源仍然为全局变量 A ,具体操作为开 thread_count 个线程,每个线程执行 A=A+1 操作 PER_THREAD 次。线程数和每个线程上的操作次数默认值分别由 THREAD_COUNT_DEFAULT 和 PER_THREAD_DEFAULT 给出,也可以通过命令行参数设置。例如,命令 adder 4 1000 可以调整为 4 个线程,每个线程执行 1000 次操作,详情参考第 37~45 行的命令行参数逻辑。
每个线程在创建之后都会不带参数执行第 27 行的 f 函数,里面是一个循环。循环的每次迭代都会尝试进入临界区(第 18 行的 critical_section 函数),共迭代 PER_THREAD 次。临界区其实就是进行 A=A+1 的操作,但有两点不同:第一点是我们使用 core::ptr::read/write_volatile 而不是直接 A=A+1 ,这是为了生成的汇编代码严格遵循 A=A+1 的三阶段而不会被编译器误优化,其实有些类似于手写汇编;第二点是我们插入了一些关于 t 的冗余操作,这并不影响到共享资源的访问,目的在于加大阶段之间的间隔,使得一次 A=A+1 操作更容易横跨两个时间片从而出现一些有趣的现象。
注解
Rust Tips: 易失性读写 read/write_volatile
有些时候,编译器会对一些访存行为进行优化。举例来说,如果我们写入一个内存位置并立即读取该位置,并且在同段时间内其他线程不会访问该内存位置,这意味着我们写入的值能够在 RAM 上保持不变。那么,编译器可能会认为读取到的值必定是此前写入的值,于是在最终的汇编码中读取内存的操作可能被优化掉。然而,有些时候,特别是访问 I/O 外设以 MMIO 方式映射的设备寄存器时,即使是相同的内存位置,对它进行读取和写入的含义可能完全不同,于是读取到的值和我们之前写入的值可能没有任何关系。连续两次读取同个设备寄存器也可能得到不同的结果。这种情况下,编译器对访存行为的修改显然是一种误优化。
于是,在访问 I/O 设备寄存器或是与 RAM 特性不同的内存区域时,就要注意通过 read/write_volatile 来确保编译器完全按照我们的源代码生成汇编代码而不会自作主张进行删除或者重排访存操作等优化。若想更加深入了解 volatile 的含义,可以参考 Rust 官方文档 。
在 user/src/bin 目录下我们还会看到很多 adder.rs 衍生出来的 adder_*.rs 测例,每个测例对应到一种锁实现。它们与 adder.rs 的主要不同在于临界区看起来是受保护的:在临界区 critical_section 的前后分别会调用上锁和解锁函数 lock 和 unlock ,每个测例的 lock 和 unlock 的实现也是不同的。然而它们不全是正确的实现,效率也各不相同。
单标记的简单尝试#
我们知道锁的本质上是一个标记,表明目前是否已经有线程进入共享资源的临界区了。于是,最简单的实现思路就是加入一个新的全局变量用作这个标记:
1// user/src/bin/adder_simple_spin.rs
2
3static mut OCCUPIED: bool = false;
4
5unsafe fn lock() {
6 while vload!(OCCUPIED) {}
7 OCCUPIED = true;
8}
9
10unsafe fn unlock() {
11 OCCUPIED = false;
12}
我们使用一个新的全局变量 OCCUPIED 作为标记,表示当前是否有线程在临界区内。在 lock 的时候,我们等待 OCCUPIED 变为 false (注意这里的 vload! 来自用户库 user_lib ,基于临界区中用到的 read_volatile 实现,含义相同),这意味着没有线程在临界区内了,于是将标记修改为 true 并自己进入临界区。在退出临界区 unlock 的时候则只需将标记改成 false 。
第 6 行不断 while 循环直到标记被改为 false ,在循环体内则不做任何事情,这是一种典型的 忙等待 (Busy Waiting) 策略,它也被形象地称为 自旋 (Spinning) 。我们目前基于单核 CPU ,如果循环第一次迭代发现标记为 true 的话,在触发时钟中断切换到其他线程之前,无论多少次查看标记都必定为 true ,因为当前线程不会修改标记。这就会造成 CPU 资源的严重浪费。针对这种场景, Rust 提供了 spin_loop_hint 函数,我们可以在循环体内调用该函数来通知 CPU 当前线程正处于忙等待状态,于是 CPU 可能会进行一些优化(比如降频减少功耗等),其在不同平台上有不同表现。此外,如果我们有操作系统支持的话,便可以考虑锁实现评价指标中的“让权等待”,这个我们后面还会讲到。
可以看到,总体上这种实现是非常简单的,但是它能够保证最关键的互斥访问吗?我们可以尝试运行一下测例,很遗憾,最后的结果并不正确!那么是哪里出了问题呢?根据原先的思路我们还是先检查 lock 的汇编代码,我们将其简化为伪代码的形式(有兴趣的同学可以自行尝试),大致上分为三个阶段,每个阶段由一到多条指令组成:
将标记的值加载到寄存器 reg
条件跳转,如果 reg 为 1 则跳转回第一阶段开始新一轮循环;否则向下进行
将标记赋值为 1
仿照最早的 adder.rs 的例子,我们很容易构造出一种时间片分割的方式使得互斥访问失效:假设某时刻标记 OCCUPIED 的值为 false ,线程 T0 和 T1 都准备进入临界区。假设先切换到 T0 ,它经历 1、2 阶段,看到标记为 false ,认为自己能够进入临界区,但是在执行关键的 3 阶段之前被操作系统切换到线程 T1 。T1 也经历 1、2阶段,由于 T0 并没有修改标记,它也认为自己能够进入临界区。接下来显然线程 T0 和 T1 能够同时进入临界区了,这就违背了互斥访问要求。
问题的本质是:在这个实现中,标记 OCCUPIED 也成为了多线程均可访问的 共享资源 ,那么 它也需求互斥访问 。而我们并没有吸取 adder.rs 的教训,我们让操作为多阶段多指令的 OCCUPIED 无任何保护的暴露在操作系统调度面前,那么自然也会发生和 adder.rs 类似的问题。那么应该如何解决问题呢?参照 adder_fixed.rs ,在硬件的支持下,将对标记的操作替换为原子操作显然很靠谱。但我们不禁要问,如果不依赖硬件,是否有一种纯软件的解决方案呢?其实在某些限制条件下是可以的,下面就介绍一个例子。
多标记的组合#
既然仅使用一个标记不行,我们尝试使用多标记的组合来表示锁的状态。比如下面的 Peterson 算法 就适用于两个线程间的互斥访问:
1// user/src/bin/adder_peterson_spin.rs
2
3/// FLAG[i]=true 表示线程 i 想要进入或已经进入临界区
4static mut FLAG: [bool; 2] = [false; 2];
5/// TURN=i 表示轮到线程 i 进入临界区
6static mut TURN: usize = 0;
7
8/// id 表示当前的线程 ID ,为 0 或 1
9unsafe fn lock(id: usize) {
10 FLAG[id] = true;
11 let j = 1 - id;
12 TURN = j;
13 // Tell the compiler not to reorder memory operations
14 // across this fence.
15 compiler_fence(Ordering::SeqCst);
16 // Why do we need to use volatile_read here?
17 // Otherwise the compiler will assume that they will never
18 // be changed on this thread. Thus, they will be accessed
19 // only once!
20 while vload!(FLAG[j]) && vload!(TURN) == j {}
21 // while FLAG[j] && TURN == j {}
22}
23
24unsafe fn unlock(id: usize) {
25 FLAG[id] = false;
26}
目前一共有三个标记:两个线程 \(T_0\) 和 \(T_1\) 各自有一个标记 \(\text{flag}_i,i\in\{0,1\}\) ,表示线程 \(T_i\) 想要或已经进入临界区。此外还有一个标记 \(\text{turn}\) ,当 \(\text{turn}\) 为 \(i\) 的时候表示轮到线程 \(T_i\) 进入临界区。
我们来看看 lock 和 unlock 各自做了哪些事情(假设调用者为线程 \(T_i\) )。在 lock 中,首先我们将 \(\text{flag}_i\) 设置为 true ,表明线程 \(T_i\) 想要进入临界区。接着得到另一个线程的编号 \(j=1-i\) 。第 12 行非常有趣:线程 \(T_i\) 将标记 \(\text{turn}\) 设置为 \(j\) ,由于 \(\text{turn}\) 的含义是有资格进入临界区的线程 ID ,这相当于 \(T_i\) 将进入临界区的资格拱手让给 \(T_j\) 。第 15 行我们可以先忽略。最后是第 20 行的忙等(为了防止编译器优化我们使用了 vload! ,逻辑同第 21 行):如果 \(T_j\) 想要或已经进入临界区而且轮到 \(T_j\) 进入临界区就一直等待下去。 unlock 则只是将 \(\text{flag}_i\) 设置为 false 。
运行一下这个测例发现总是可以得到正确的结果,说明在操作系统调度的影响下这种算法仍能够保证临界区的互斥访问,但这是如何做到的呢?这里并无必要给出一个严格证明,我们分成两种情况进行简单说明:
第一种情况考虑两个线程的
lock操作不重叠的情况,这种情况比较简单。假设 \(T_j\) 已经成功lock并进入了临界区且尚未离开,此时 \(T_i\) 开始尝试进入临界区,它能成功吗?根据lock的流程, \(T_i\) 会将 \(\text{flag}_i\) 设置为 true ,并将 \(\text{turn}\) 设置为 \(j\) 。接下来来看忙等的两个条件。首先是 \(\text{turn}\) ,它被 \(T_i\) 设置为 \(j\) ,而 \(T_j\) 在退出临界区之前不会对它进行修改,所以此时 \(\text{turn}\) 的值一定为 \(j\) ,条件成立;其次是 \(\text{flag}_j\) ,注意到 \(T_j\) 在进入临界区之前的lock中将其修改为 true ,且在离开临界区之前不会将其改为 false ,所以此时 \(\text{flag}_j\) 一定为 true ,条件也成立。因此, \(T_i\) 会陷入忙等而不会进入临界区。第二种情况考虑两个线程的
lock操作由于操作系统调度出现交错现象,也即两个线程在同段时间内尝试进入临界区,是否只有一个线程能成功进入呢?为了方便起见我们先排除 \(\text{flag}_{i,j}\) 的影响。因为两个线程在lock的第一步就是将自己的 \(\text{flag}\) 设置为 true ,且在退出临界区之后才会修改为 false 。从时间上,我们只考察从两个线程开始lock直到某个线程成功进入临界区且未离开的这段时间,我们可以认为在这段时间内始终有 \(\text{flag}_i=\text{flag}_j=\text{true}\) 。于是两个线程的忙等条件可以得到简化:即线程 \(T_i\) 只要 \(\text{turn}=j\) 就一直忙等,而线程 \(T_j\) 只要 \(\text{turn}=i\) 就一直忙等。每个线程都不能单靠自己进入临界区:以 \(T_i\) 为例,它将 \(\text{turn}\) 设置为 \(j\) ,但它忙等的条件也是 \(\text{turn}=j\) ,于是只有它自己的话就会进入忙等而不能进入临界区。必须要两个线程的协作:即当 \(T_j\) 将 \(\text{turn}\) 设置为 \(i\) , \(T_i\) 才能进入临界区。
可以看出问题的关键在于 \(\text{turn}\) 。无论操作系统如何进行调度,在单核 CPU 上,线程 \(T_i\) 和线程 \(T_j\) 对于 \(\text{turn}\) 的 修改总有一个在时间上靠后 。不妨设 \(T_i\) 在 \(T_j\) 之后将 \(\text{turn}\) 修改为 \(j\) ,那么这段时间中 \(\text{turn}\) 就会一直是 \(j\) 了,因为两个线程都已经完成了仅有一次的对于 \(\text{turn}\) 的修改。于是, \(T_i\) 不可能在这一轮进入临界区了。考虑 \(T_j\) ,它已经完成了 \(\text{turn}\leftarrow i\) 的修改,此时可能已陷入忙等或者还没开始忙等。无论如何,只要接下来操作系统从 \(T_i\) 切换到 \(T_j\) , \(T_j\) 就能退出忙等并成功进入临界区。结论是,哪个线程最后修改了 \(\text{turn}\) ,则另一个线程最终一定能进入临界区。
这样我们就说明了 Peterson 算法是如何在操作系统调度下仍保证互斥访问的。那么它能够满足空闲则入和有界等待这另外两个必须的要求吗?在这里需要说明的是,我们不必考虑操作系统调度导致的一些极端情况。比如说在考察是否能满足有界等待的时候,假如某个线程在进入等待状态之后,操作系统就再也不会调度到这个线程,看起来是出现了饥饿现象。但是这应当被归结于操作系统调度算法而非我们的锁实现。因此,我们需要合理地假设调度算法较为公平,各线程分到的 CPU 资源比较接近,这样调度算法就不会在很大程度上影响到锁的效果。现在回过头来看两个要求:
对于空闲则入,之前我们说明了当资源空闲的时候,如果只有单个线程要进入临界区,那么它一定能进去。如果两个线程要同时进入的话,只需要等到两个线程对于 \(\text{turn}\) 的修改均完成就能够确定哪个线程进入临界区,这一定能够在有限时间内做到。
对于有界等待,假设线程 \(T_i\) 由于没有竞争过 \(T_j\) 而在
lock中陷入忙等待,相反 \(T_j\) 则成功进入临界区。在 \(T_j\) 离开临界区之后,可以发现它不可能在 \(T_i\) 进入临界区之前再次进入临界区了。可以使用反证法,假设 \(T_j\) 能够在 \(T_i\) 不进入的情况下再次进入,考虑 \(T_j\) 的忙等循环的两个条件,由于 \(T_i\) 一直处在忙等状态,有 \(\text{flag}_i\) 为 true ,而 \(\text{turn}=i\) (由 \(T_j\) 在进入忙等循环之前修改, \(T_i\) 已经在忙等没有机会修改为 \(j\) ),可知 \(T_j\) 会卡在忙等中不能进入临界区,与假设矛盾。相反,从 \(T_i\) 的视角看来,在 \(T_j\) 离开临界区之后,只要操作系统通过调度切换到 \(T_i\) , \(T_i\) 立即就能进入临界区(除非在 \(T_j\) 完成 \(\text{flag}_j\leftarrow\text{true}\) 之后立即切换,但这种情况也只是让 \(T_i\) 晚一些进入临界区),有兴趣的同学可自行验证。总体看来, \(T_i\) 和 \(T_j\) 是在交替进入临界区,因此不存在某一个线程的无限等待——即饥饿现象。
这说明, Peterson 算法确实能够满足忙则等待、空闲则入和有界等待三个要求,是一种合格的锁实现。类似的算法还有适用于双线程的 Dekkers 算法 以及适用于多线程的 Eisenberg & McGuire 算法 。 这类算法仅依赖最基本的访存操作以及用户态权限,但思想上用到了多标记的组合以及精巧的构造,虽然代码比较简单,但是不容易理解,要证明其正确性更是十分复杂。更为重要的是,这类算法存在着时代局限性,对 CPU 的内存访问有着比较严格的要求,因此这类算法是不能不加修改的运行在现代多核处理器上的。如果要保证其正确性,则要付出极大的性能开销,甚至得不偿失。因此,目前在实践中我们并不会用到这类算法实现锁机制。关于这种局限性更加深入的讨论超出了本书的范围,因此我们将其放在附录中,有兴趣的同学可以参考 附录 F:类 Peterson 算法的局限性和内存顺序 。
基于硬件机制及特殊指令的锁实现#
上面我们介绍了锁的纯软件实现。可以看到,为了保证互斥访问要求,需要用到类似于 Peterson 的十分精密复杂的算法,它们不易理解,而且与现代处理器(特别是多核架构的处理器)的适配性不好。于是,我们可以考虑将这种通用的锁机制的需求下沉到硬件。如果硬件能提供相应的一些支持,那么我们在软件层面上就能比较简单地实现锁机制,且总体性能较高。下面依次介绍两种实现锁机制相关硬件支持:即关闭中断和原子指令。
关闭中断#
从前面的分析可以看出,站在用户态软件也就是应用的角度,并发问题的一个重要来源是操作系统随时有可能通过抢占式调度切换到其他线程,特别是当线程处于临界区被切换出去的时候,将导致不同线程的临界区交错运行使得共享资源访问出错。那么如何保证线程处于临界区的时候不会被操作系统切换出去呢?经过第三章的学习,我们知道操作系统进行的这种抢占式调度是由时钟中断触发的。如果应用程序能够控制中断的打开(使能)与关闭(屏蔽),那就能提供互斥解决方案了。代码如下:
1fn lock() {
2 disable_interrupt(); //屏蔽中断的机器指令
3}
4
5fn unlock() {
6 enable_interrupt(); //使能中断的机器指令
7}
在进入临界区之前,线程调用 lock 函数屏蔽整个 CPU 包括时钟中断在内的所有中断。这样在临界区中,线程就不用担心会被操作系统切换出去了,可以放心操作共享资源了。实际上此时它独占了整个 CPU 。在离开临界区之后,线程再调用 unlock 函数使能所有中断,因为此时它再被切换出去也没有问题了。
这种方法的优点是简单,但是缺点则很多。首先,这种做法给了用户态程序使能/屏蔽中断这种特权,相当于相信应用并放权给它。这会面临和我们引入抢占式调度之前一样的问题:线程可以选择恶意永久关闭中断而独占所有 CPU 资源,这将会影响到整个系统的正常运行。因此,事实上至少在 RISC-V 这样含多个特权级的架构中,这甚至是完全做不到的。回顾第三章,可以看到中断使能和屏蔽的相关标志位分布在 S 特权级的 CSR sstatus 和 sie ,甚至更高的 M 特权级的 CSR 中。用户态试图修改它们将会触发非法指令异常,操作系统会直接杀死该线程。其次,即使我们能够做到,它对于多处理器架构也是无效的。假设同一进程的多个线程运行在不同的 CPU 上,它们都尝试访问同种共享资源。一般来说,每个 CPU 都有自己的独立的中断相关的寄存器,它只能对自己的中断处理进行设置。对于一个线程来说,它可以关闭它所在 CPU 的中断,但是这无法影响到其他线程所在的 CPU ,其他线程仍然可以在此时进入临界区,便不能满足互斥访问的要求了。所以,采用控制中断的方式仅对一些非常简单,且信任应用的单处理器场景有效,而对于更广泛的其他场景是不够的。
然而,需要注意的是,这种关闭中断的方法作为用户态锁机制的实现很不靠谱,在实现内核态锁机制的时候有些情况下却是必不可少的。我们将在第九章介绍位于内核态的一种基于关中断的锁实现。
原子指令#
常用的 CAS 和 TAS 指令#
在之前的 adder_simple_spin.rs 中,我们尝试用一个全局变量作为锁标记,但是最后却失败了。主要原因在于这个锁标记作为全局变量也是一种共享资源,对它进行的操作也是多阶段多条指令的,也会受到操作系统调度的影响,从而不能满足互斥访问要求,也就无法正确实现锁机制了。应该如何解决这个问题呢?回忆在 adder_fixed.rs 中我们使用 Rust 提供的原子操作将全局变量 A 的临界区缩小为一条原子指令使其免受操作系统调度的影响,这里我们也可以换用原子操作处理锁标记达到同样的效果,不过需要使用不同类型的原子操作:
1// user/src/bin/adder_atomic.rs
2
3static OCCUPIED: AtomicBool = AtomicBool::new(false);
4
5fn lock() {
6 while OCCUPIED
7 .compare_exchange(false, true, Ordering::Relaxed, Ordering::Relaxed)
8 .is_err()
9 {
10 yield_();
11 }
12}
13
14fn unlock() {
15 OCCUPIED.store(false, Ordering::Relaxed);
16}
这里我们将全局锁标记替换为原子 bool 类型 AtomicBool 。它支持 AtomicBool::compare_exchange 操作,接口定义如下:
pub fn compare_exchange(
&self,
current: bool,
new: bool,
success: Ordering,
failure: Ordering,
) -> Result<bool, bool>;
其功能为:如果原子变量当前的值与 current 相同,则将原子变量的值修改为 new ,否则不进行修改。无论是否进行修改,都会返回原子变量在操作之前的值。可以看到返回值是一个 Result ,如果修改成功的话这个值会用 Ok 包裹,否则则会用 Err 包裹。关于另外两个内存顺序参数 success 和 failure 不必深入了解,在单核环境下使用 Ordering::Relaxed 即可。注意 compare_exchange 作为一个基于硬件的原子操作, 它不会被操作系统的调度打断 。
那么 lock 和 unlock 是如何实现的呢?在 lock 中,主体仍然是一个 while 循环。每次迭代我们使用 compare_exchange 进行如下操作:如果 OCCUPIED 当前是 false ,表明目前没有线程在临界区内,那么就将 OCCUPIED 改成 true ,返回 Ok 退出 while 循环,随后线程进入临界区;否则, OCCUPIED 当前是 true ,表明已经有线程在临界区之内了,那么 compare_exchange 修改失败并返回 Err ,循环还需要继续下去。这种情况由于是在单核 CPU 上,进行下一轮迭代一定会继续失败,故而及时通过 yield 系统调用交出 CPU 资源。 unlock 的实现则比较简单,离开临界区的线程同样通过原子存储操作 store 将 OCCUPIED 修改为 false 表示已经没有线程在临界区中了,此后线程可以进入临界区了。尝试运行一下 adder_atomic.rs ,可以看到它能够满足互斥访问需求。
Rust 核心库为我们提供了原子类型以及 compare_exchange 这种方便的操作,那么它们是用硬件提供的哪些原子指令来实现的呢?硬件提供的原子指令一般是对于一个内存位置进行一系列操作,并保证整个过程的原子性。比如说最经典的 比较并交换 (Compare-And-Swap, CAS)指令。它在不同平台上的具体表现存在细微差异,我们这里按照 RISC-V 的写法描述它的核心功能:它有三个源寄存器和一个目标寄存器,于是应该写成 CAS rd, rs1, rs2, rs3 。它的功能是将一个内存位置存放的值(其地址保存在一个源寄存器中,假设是 rs1 )与一个期待值 expected (保存在源寄存器 rs2 中)进行比较,如果相同的话就将内存位置存放的值改为 new (保存在源寄存器 rs3 中)。无论是否相同,都将执行 CAS 指令之前这个内存位置存放的值写入到目标寄存器 rd 中。如果用 Rust 语言伪代码的形式描述 CAS 指令的功能应该是这样:
1fn compare_and_swap(ptr: *mut i32, expected: i32, new: i32) -> i32 {
2 let original = unsafe { *ptr };
3 if original == expected {
4 unsafe { *ptr = new; }
5 }
6 original
7}
所以“比较并交换”展开来说是如果比较结果相同,则将 new 交换到内存中,然后将内存中原来的值交换出来并返回。这段伪代码仅能用来描述 CAS 指令的功能,但 CAS 指令并不等价于这段伪代码,因为硬件能够保证 CAS 指令中的一系列操作是原子的,而不是按顺序执行若干访存和算术指令。同时,这里我们假定内存位置存放的值以及寄存器中有效的值是 32 位的。对于 CAS 指令,硬件通常会支持 16 位、32位、64位等通用寄存器常用的位宽,并在大多数情况下要求内存地址是对齐到对应位宽的。忽略这些细节,我们可以发现 CAS 指令和 Rust 中的 compare_exchange 本质上是一回事,后者可以直接用前者来实现。CAS 是实现包括锁在内的同步机制最主要的方式,因此主流平台上基本都提供了 CAS 指令的支持。比如,在 x86 平台上我们有 CMPXCHG 指令,在 SPARC-V9 平台上我们则有 CASA/SWAP 等指令。
除了 CAS 之外,曾经还有另一类常用来实现同步机制的原子指令,它被称为 测试并设置 (Test-And-Set, TAS) 。相比 CAS , TAS 没有比较的步骤,它直接将 new 写入到内存并返回内存位置原先的值。用 Rust 语言伪代码描述 TAS 的功能如下:
1fn test_and_set(ptr: *mut i32, new: i32) -> i32 {
2 let original = unsafe { *ptr };
3 unsafe { *ptr = new };
4 original
5}
在 TAS 中,内存中的值一定会被改成 new ,于是更关键的在于返回值,也就是 TAS 之前内存中的值。比如,可以这样来用 TAS 指令实现锁机制:
1static mut OCCUPIED: i32 = 0;
2
3unsafe fn lock() {
4 while (test_and_set(&mut OCCUPIED, 1) == 1) {}
5}
6
7unsafe fn unlock() {
8 OCCUPIED = 0;
9}
这里我们仍然使用 OCCUPIED 作为全局锁标记表示是否已经有线程在临界区中。当一个线程想要进入临界区的时候,它会调用 lock 函数,其中使用 TAS 指令原子地将锁标记设置为 1 并返回原先的值。假设有多个线程同时想要进入临界区,由于硬件保证 TAS 指令的原子性不受中断或多核同时访问的影响,只有 TAS 指令被最早执行的线程能够看到 TAS 的返回值为 0 ,意味着此时还没有线程在临界区中,那么这个线程可以结束忙等进入临界区。而后会执行其他线程上的 TAS 指令,它们的返回值就是 1 了,需要忙等待进入临界区的线程退出临界区。这样就保证了互斥访问。 unlock 则是将全局锁标记改成 0 即可。
RISC-V 架构上的原子指令#
如果同学还有印象的话,我们曾经在 第二章介绍 Trap 上下文保存与恢复 的时候用到过一系列读写 RISC-V 控制状态寄存器(CSR)的特殊指令,比如 csrr , csrw ,特别是 csrrw 等。当时我们提到这些指令也都是原子指令。现在我们更加深入的理解了原子指令的含义,同学如有兴趣可以想想这些指令为什么必须保证其原子性。
除此之外, RISC-V 架构的原子拓展(Atomic,简称 A 拓展)提供了一些对于一个内存位置上的值进行原子操作的原子指令,分为两大类。其中第一类被称为原子内存操作(Atomic Memory Operation, AMO)。这类原子指令首先根据寄存器 rs1 保存的内存地址将值从内存载入到寄存器 rd 中,然后将这个载入的值与寄存器 rs2 中保存的值进行某种运算,并将结果写回到 rs1 中的地址对应的内存区域中。整个过程可以被概括为一种 read-modify-write 的三阶段操作,硬件能够保证其原子性。AMO 支持多种不同的运算,包括交换、整数加法、按位与、按位或、按位异或以及有/无符号整数最大或最小值。容易看出,这类指令能够方便地实现 adder_fixed.rs 中 Rust 提供的 fetch_add 这类原子操作。
RISC-V 提供的另一类原子指令被称为加载保留/条件存储(Load Reserved / Store Conditional,简称LR/SC),它们通常被配对使用。首先, LR 指令可以读取内存中的一个值(其地址保存在寄存器 rs1 中)到目标寄存器 rd 。然后,可以使用 SC 指令,它的功能是将内存中的这个值(其地址保存在寄存器 rs1 中且与 LR 指令中的相同)改成寄存器 rs2 保存的值,但前提是:执行 LR 和 SC 这两条指令之间的这段时间内,内存中的这个值并未被修改。如果这个前提条件不满足,那么 SC 指令不会进行修改。SC 指令的目标寄存器 rd 指出 SC 指令是否进行了修改:如果进行了修改, rd 为 0;否则, rd 可能为一个非零的任意值。
那么 SC 指令是如何判断此前一段时间该内存中的值是否被修改呢?在 RISC-V 架构下,存在一个 保留集 (Reservation Set) 的概念,这也是“加载保留”这种叫法的来源。保留集用来实现 LR/SC 的检查机制:当 CPU 执行 LR 指令的时候,硬件会记录下此时内存中的值是多少,此外还可能有一些附加信息,这些被记录下来的信息就被称为保留集。之后,当其他 CPU 或者外设对内存这个值进行修改的时候,硬件可以将这个值对应的保留集标记为非法或者删除。等到之前执行 LR 指令的 CPU 执行 SC 指令的时候,CPU 就可以检查保留集是否存在/合法或者保留集记录的值是否与内存中现在的值一致,以这种方式来决定是否进行写入以及目标寄存器 rd 的值。
RISC-V 并不原生支持 CAS/TAS 原子指令,但我们可以通过 LR/SC 指令对来实现它。比如下面是通过 LR/SC 指令对来模拟 CAS 指令。有兴趣的同学可以对照注释自行研究。
1# 参数 a0 存放内存中的值的所在地址
2# 参数 a1 存放 expected
3# 参数 a2 存放 new
4# 返回值 a0 略有不同:这里若比较结果相同则返回 0 ,否则返回 1
5# 而不是返回 CAS 之前内存中的值
6cas:
7 lr.w t0, (a0) # LR 将值加载到 t0
8 bne t0, a1, fail # 如果值和 a1 中的 expected 不同,跳转到 fail
9 sc.w t0, a2, (a0) # SC 尝试将值修改为 a2 中的 new
10 bnez t0, cas # 如果 SC 的目标寄存器 t0 不为 0 ,说明 LR/SC 中间值被修改,重试
11 li a0, 0 # 成功,返回值为 0
12 ret # 返回
13fail:
14 li a0, 1 # 失败,返回值为 1
15 ret # 返回
原子指令小结#
让我们来对原子指令部分进行一个小结。为了提供软件所需的包含互斥锁在内的各种同步机制,硬件对于内存中的一个字、双字、四字(位宽分别为16、32、64位,且通常要求是对齐的)这类通用的存储单位提供了一系列原子指令,这些原子指令能够对内存中的值进行加载、运算、修改等多种操作,且能够保证整个过程是原子的。也就是说,在硬件层面上,其原子性有着更高的优先级而不会被中断、多个 CPU 同时访问内存中同个位置或者指令执行中的更多情况破坏。
作为例子我们介绍了经典的 CAS/TAS 指令以及 RISC-V 上提供的 LR/SC 指令对,基于它们我们能够简单且高效的实现锁机制。重新回顾一下这些指令,可以发现它们从结果上都存在成功/失败之分。如果多个 CPU 同时用这些指令访问内存中同一个值,显然只有一个 CPU 能够成功。事实上,当多个 CPU 同时执行这些原子指令的时候,它们会将相关请求发送到 CPU 与 RAM 间总线上,总线会将这些请求进行排序。这就好像一群纷乱的游客在通过一个狭窄的隘口的时候必须单列排队通过,无论如何总会产生一种顺序。于是我们会看到,请求排在最前面的 CPU 能够成功,随后它便相当于独占了这一块被访问的内存区域。接下来,排在后面的 CPU 的请求都会失败了,这种状况会持续到之前独占的 CPU 将对应内存区域重置(相当于 unlock )。正因如此,我们才说:“ 原子指令是整个计算机系统中最根本的原子性和互斥性的来源 。”这种最根本的互斥性来源于总线的仲裁,表现为原子指令,作用范围为基础存储单位。在原子指令的基础上,我们可以灵活地编写软件来延伸互斥性或其他同步需求的作用范围,使得对于各种丰富多彩的资源(如复杂数据结构和多种外设)我们都能将其管理得有条不紊。
虽然原子指令已经能够简单高效的解决问题了,但是在很多情况下,我们可以在此基础上再引入软件对资源进行灵活的调度管理,从而避免资源浪费并得到更高的性能。
在操作系统支持下实现让权等待#
在编程时,常常遇到必须满足某些条件(或是遇到某些事件)才能进行接下来的流程的情况。如果一开始这些条件并不成立,那么必须通过某种方式暂时在原地 等待 这些条件满足之后才能继续前进。我们可以用多种不同的方式进行等待,最为常见的几种包括:忙等、通过 yield 暂时让权以及后面重点介绍的阻塞。
忙等#
应用 adder_peterson_spin.rs 展示了如何使用 Peterson 算法实现锁机制,在这里我们关注它如何进行等待。在其中的 lock 函数中,需要满足 \(\text{flag}_j\) 为 false 和 \(\text{turn}\not=j\) 两个条件至少满足其一才能继续前进并成功进入临界区。于是在第 20 行,我们通过一个 while 循环进行 忙等待 直到条件成立。
运行这个测例会发现一种现象:虽然其结果是正确的,但是每个线程尝试进入临界区的次数 PER_THREAD 比较大(比如大于 5000 )的时候有时总运行时间会非常长,对于这种数据规模来说是完全不可接受的。如何解释这种现象呢?对于一个线程来说,在 while 循环的第一次迭代中如果发现条件不成立,那么就可以知道在这个分配给它的时间片中,接下来的所有迭代条件都不成立。因为我们是单核,此时 CPU 由这个线程使用,它只是不断做判断而不会做任何修改。另一个线程可以做修改,但是暂时没有 CPU 使用权。所以,在这种忙等待的做法中,只要一开始条件不成立,那么剩余时间片都会被浪费在 while 循环中,这也就导致了某些情况下测例运行时间很长。要解决这个问题,需要线程一旦注意到条件不成立,就立即主动或者被动交出 CPU 使用权,反正它暂时无法做任何有意义的事情了。我们后面再介绍具体如何实现。
总体上说,若要以忙等方式进行等待,首先要保证忙等是有意义的,不然就只是单纯的在浪费 CPU 资源。怎样才算是有意义的忙等呢?那就是 在忙等的时候被等待的条件有可能从不满足变为满足 。比如说,一个线程占据 CPU 资源进行忙等的同时,另一个线程可以在另一个 CPU 上执行,外设也在工作,它们都可以修改内存使得条件得到满足。这种情况才有等待的价值。于是可以知道, 在单核环境下且等待条件不涉及外设的时候,一个线程的忙等是没有意义的 ,因为被等待的条件的状态不可能发生变化。
在忙等有意义的前提下,忙等的优势是在条件成立的第一时间就能够进行响应,对于事件的响应延迟更低,实时性更好,而且不涉及开销很大的上下文切换。它的缺点则是不可避免的会浪费一部分 CPU 资源在忙等上。因此,如果我们能够预测到条件将很快得到满足,在这种情况下使用忙等是一个好主意。如果条件成立的时间无法预测或者所需时间比较长,那还是及时交出 CPU 资源更好。
通过 yield 暂时让权#
在应用 adder_peterson_spin.rs 的基础上,线程可以在发现条件暂时不成立的情况下通过 yield 系统调用主动交出 CPU 使用权:
1// user/src/bin/adder_peterson_yield.rs
2
3unsafe fn lock(id: usize) {
4 FLAG[id] = true;
5 let j = 1 - id;
6 TURN = j;
7 // Tell the compiler not to reorder memory operations
8 // across this fence.
9 compiler_fence(Ordering::SeqCst);
10 while FLAG[j] && TURN == j {
11 yield_();
12 }
13}
事实上,这并不是我们第一次利用 yield 在等待条件不满足的时候让权了,此前我们就做过类似的事情。考虑 sys_waitpid 系统调用在 user_lib 中的封装 waitpid :
1// user/src/lib.rs
2
3pub fn waitpid(pid: usize, exit_code: &mut i32) -> isize {
4 loop {
5 match sys_waitpid(pid as isize, exit_code as *mut _) {
6 -2 => {
7 yield_();
8 }
9 // -1 or a real pid
10 exit_pid => return exit_pid,
11 }
12 }
13}
这里是被等待的子进程尚未退出,于是我们先 yield ,等下一次获得 CPU 使用权的时候再检查该子进程是否退出。
另一个例子是在本章之前, sleep 由用户库 user_lib 提供而不是一个系统调用:
1// user/src/lib.rs
2
3pub fn sleep(period_ms: usize) {
4 let start = sys_get_time();
5 while sys_get_time() < start + period_ms as isize {
6 sys_yield();
7 }
8}
这里是发现睡眠的时间还不够,于是 yield 并在下一次获得时间片的时候再检查。
使用 yield 实现通常情况下不会出错。但是它的实际表现却很大程度上受到操作系统调度器的影响。 如果在条件满足之前就多次调度到等待的线程,虽然看起来线程很快就会再次通过 yield 主动让权从而没什么开销,但是实际上却增加了上下文切换的次数。上下文切换的开销是很大的,除了要保存和恢复寄存器之外,更重要的一点是会破坏程序的时间和空间局部性使得我们无法高效利用 CPU 上的各类缓存。比如说,我们的实现中在 Trap 的时候需要切换地址空间,有可能需要清空 TLB ;由于用户态和内核态使用不同的栈,在应用 Trap 到内核态的时候,缓存中原本保存着用户栈的内容,在执行内核态代码的时候可能由于缓存容量不足而需要逐步替换成内核栈的内容,而在返回用户态之后又需要逐步替换回来。整个过程中的缓存命中率将会很低。所以说,即使线程只是短暂停留也有可能对整体性能产生影响。 相反,如果在条件满足很久之后才调度到等待的线程,这则会造成事件的响应延迟不可接受。使用 yield 就有可能出现这些极端情况,而且我们完全无法控制或预测其效果究竟如何。因此,我们需要一种更加确定、可控的等待方案。
阻塞#
在操作系统的协助下,我们可以对于等待进行更加精细的控制。为了避免等待事件的线程在事件到来之前被调度到而产生大量上下文切换开销,我们可以新增一种 阻塞 (Blocking) 机制。当线程需要等待事件到来的时候,操作系统可以将该线程标记为阻塞状态 (Blocked) 并将其从调度器的就绪队列中移除。由于操作系统每次只会从就绪队列中选择一个线程分配 CPU 资源,被阻塞的线程就不再会获得 CPU 使用权,也就避免了上下文切换。相对的,在线程要等待的事件到来之后,我们需要解除线程的阻塞状态,将线程状态改成就绪状态,并将线程重新加入到就绪队列,使其有资格得到 CPU 资源。这就是与阻塞机制配套的唤醒机制。在线程被唤醒之后,由于它所等待的事件已经出现,在操作系统调度到它之后它就可以继续向下运行了。
阻塞与唤醒机制相配合就可以实现精确且高效的等待。阻塞机制保证在线程等待的事件到来之前,线程不会参与调度,因此不会浪费任何时间片或产生上下文切换。唤醒机制则在事件到来之后允许线程正常继续执行。注意到,操作系统能够感知到事件以及等待该事件的线程,因此根据事件的实时性要求以及线程上任务的重要程度,操作系统可以在对于调度策略进行调整。比如,当事件为键盘或鼠标输入时,操作系统可以在唤醒之后将对应线程的优先级调高,让其能够被尽量早的调度到,这样就能够降低响应延迟并提升用户体验。也就是说,相比 yield ,这种做法的可控性更好。
阻塞机制的缺点在于会不可避免的产生两次上下文切换。站在等待的线程的视角,它会被切换出去再切换回来然后再继续执行。在事件产生频率较低、事件到来速度比较慢的情况下这不是问题,但当事件产生频率很高的时候直接忙等也许是更好的选择。此外,阻塞机制相对比较复杂,需要操作系统的支持。
下面介绍我们的操作系统如何实现阻塞机制以及阻塞机制的若干应用。
实现阻塞与唤醒机制#
在任务管理方面,此前我们已经有 suspend/exit_current_and_run_next 两种接口。现在我们新增第三种接口 block_current_and_run_next :
1// os/src/task/mod.rs
2
3pub fn block_current_and_run_next() {
4 let task = take_current_task().unwrap();
5 let mut task_inner = task.inner_exclusive_access();
6 let task_cx_ptr = &mut task_inner.task_cx as *mut TaskContext;
7 task_inner.task_status = TaskStatus::Blocked;
8 drop(task_inner);
9 schedule(task_cx_ptr);
10}
11
12pub fn suspend_current_and_run_next() {
13 let task = take_current_task().unwrap();
14 let mut task_inner = task.inner_exclusive_access();
15 let task_cx_ptr = &mut task_inner.task_cx as *mut TaskContext;
16 task_inner.task_status = TaskStatus::Ready;
17 drop(task_inner);
18 add_task(task);
19 schedule(task_cx_ptr);
20}
当一个线程陷入内核态之后,如果内核发现这个线程需要等待某个暂未到来的事件或暂未满足的条件,就需要调用这个函数阻塞这个线程。从实现来看,第 4 行我们将线程从当前 CPU 的处理器管理结构中移除;第 5~8 行我们将线程状态修改为阻塞状态 Blocked ;最后在第 9 行我们保存当前的任务上下文到线程控制块中并触发调度切换到其他线程。
作为比较,上面还给出了我们非常熟悉的会在时钟中断时被调用的 suspend_current_and_run_next 函数。我们的 block 版本和它的区别仅仅在于我们会将线程状态修改为 Blocked 以及我们此处 不会将被阻塞的线程重新加回到就绪队列中 。这样才能保证被阻塞的线程在事件到来之前不会被调度到。
上面就是阻塞机制的实现,那么唤醒机制如何实现呢?当一个事件到来或是条件被满足的时候,首先我们要找到有哪些线程在等待这个事件或条件,这样才能够唤醒它们。因此,在内核中我们会 将被阻塞的线程的控制块按照它们等待的具体事件或条件分类存储 。通常情况,对于每种事件,我们将所有等待该事件的线程而被阻塞的线程保存在这个事件的阻塞队列(或称等待队列)中。这样我们在事件到来的时候就知道要唤醒哪些线程了。
在事件到来的时候,我们要从事件的等待队列中取出线程,并调用唤醒它们的函数 wakeup_task :
1// os/src/task/manager.rs
2
3pub fn wakeup_task(task: Arc<TaskControlBlock>) {
4 let mut task_inner = task.inner_exclusive_access();
5 task_inner.task_status = TaskStatus::Ready;
6 drop(task_inner);
7 add_task(task);
8}
这里只是简单的将线程状态修改为就绪状态 Ready 并将线程加回到就绪队列。
在引入阻塞机制后,还需要注意它跟线程机制的结合。我们知道,当进程的主线程退出之后,进程的所有其他线程都会被强制退出。此时,这些线程不光有可能处于就绪队列中,还有可能正被阻塞等待某些事件,因而在这些事件的阻塞队列中。所以,在线程退出时,我们需要 检查线程所有可能出现的位置并将线程控制块移除,不然就会造成内存泄漏 。有兴趣的同学可以参考 os/src/task/mod.rs 中的 remove_inactive_task 的实现。
这样,我们就成功实现了阻塞-唤醒机制。
基于阻塞机制实现 sleep 系统调用#
现在我们尝试基于阻塞机制将 sleep 功能作为一个系统调用而不是在用户库 user_lib 中通过 yield 来实现。首先来看该系统调用的接口定义:
/// 功能:当前线程睡眠一段时间。
/// 参数: sleep_ms 表示线程睡眠的时间,单位为毫秒。
/// 返回值: 0
/// syscall ID : 101
pub fn sys_sleep(sleep_ms: usize) -> isize;
当线程使用这个系统调用之后,它将在陷入内核态之后被阻塞。线程等待的事件则是 时钟计数器 的值超过当前时间再加上线程睡眠的时长的总和,也就是超时之后就可以唤醒线程了。因此,我们要等待的事件可以用一个超时时间表示。然后,我们用一个数据结构 TimerCondVar 将这个超时时间以及等待它的线程放到一起,这是唤醒机制的关键数据结构:
1pub struct TimerCondVar {
2 pub expire_ms: usize,
3 pub task: Arc<TaskControlBlock>,
4}
那么如何保证在超时的时候内核能够接收到这个事件并做相应处理呢?我们这里选择一种比较简单的做法:即在每次时钟中断的时候检查在上个时间片中是否有一些线程的睡眠超时了,如果有的话我们就唤醒它们。这样的做法可能使得线程实际睡眠的时间不太精确,但是其误差也不会超过一个时间片,还算可以接受。同学有兴趣的话可以想想看有没有什么更好的做法。
当时钟中断的时候我们可以扫描所有的 TimerCondVar ,将其中已经超时的移除并唤醒相应的线程。不过这里我们可以用学过的数据结构知识做一点小优化:可以以超时时间为键值将所有的 TimerCondVar 组织成一个小根堆(另一种叫法是优先级队列),这样每次时钟中断的时候只需不断弹出堆顶直到堆顶还没有超时。
为了能将 TimerCondVar 放入堆中,需要为其定义偏序、全序比较方法和相等运算,也就是要实现 PartialEq, Eq, PartialOrd, Ord 这些 Trait :
1// os/src/timer.rs
2
3impl PartialEq for TimerCondVar {
4 fn eq(&self, other: &Self) -> bool {
5 self.expire_ms == other.expire_ms
6 }
7}
8impl Eq for TimerCondVar {}
9impl PartialOrd for TimerCondVar {
10 fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
11 let a = -(self.expire_ms as isize);
12 let b = -(other.expire_ms as isize);
13 Some(a.cmp(&b))
14 }
15}
16impl Ord for TimerCondVar {
17 fn cmp(&self, other: &Self) -> Ordering {
18 self.partial_cmp(other).unwrap()
19 }
20}
由于标准库提供的二叉堆 BinaryHeap 是一个大根堆,因此在实现 PartialOrd Trait 的时候我们需要将超时时间取反。这样的话,就可以把所有的 TimerCondVar 放到一个全局二叉堆 TIMERS 中:
// os/src/timer.rs
use alloc::collections::BinaryHeap;
lazy_static! {
static ref TIMERS: UPSafeCell<BinaryHeap<TimerCondVar>> =
unsafe { UPSafeCell::new(BinaryHeap::<TimerCondVar>::new()) };
}
设计好数据结构之后,首先来看 sleep 系统调用如何实现:
// os/src/syscall/sync.rs
pub fn sys_sleep(ms: usize) -> isize {
let expire_ms = get_time_ms() + ms;
let task = current_task().unwrap();
add_timer(expire_ms, task);
block_current_and_run_next();
0
}
// os/src/timer.rs
pub fn add_timer(expire_ms: usize, task: Arc<TaskControlBlock>) {
let mut timers = TIMERS.exclusive_access();
timers.push(TimerCondVar { expire_ms, task });
}
在 sys_sleep 中,我们首先计算当前线程睡眠超时时间 expire_ms ,然后调用 adder_timer 生成一个 TimerCondVar 并将其加入到全局堆 TIMERS 中。注意这个过程中线程控制块是如何流动的:它被复制了一份并移动到 TimerCondVar 中,此时在处理器管理结构 PROCESSOR 中还有一份。而在调用 block_current_and_run_next 阻塞当前线程之后, PROCESSOR 中的那一份就被移除了。此后直到线程被唤醒之前,线程控制块都只存在于 TimerCondVar 中。
在时钟中断的时候则会调用 check_timer 尝试唤醒睡眠超时的线程:
1// os/src/timer.rs
2
3pub fn check_timer() {
4 let current_ms = get_time_ms();
5 let mut timers = TIMERS.exclusive_access();
6 while let Some(timer) = timers.peek() {
7 if timer.expire_ms <= current_ms {
8 // 调用 wakeup_task 唤醒超时线程
9 wakeup_task(Arc::clone(&timer.task));
10 timers.pop();
11 } else {
12 break;
13 }
14 }
15}
当线程睡眠的时候退出, timer.rs 中的 remove_timer 可以移除掉线程所在的 TimerCondVar ,在此不再赘述。
基于阻塞机制实现锁机制#
为了在操作系统的支持下实现锁机制,我们可以将锁看成进程内的一种资源(类似文件描述符表和地址空间),一个进程可以有多把锁,这些锁可以用它们的 ID 来区分,每把锁可以用来保护不同的共享资源。进程内的所有线程均可以访问锁,但是只能通过系统调用这种间接的方式进行访问。因此,需要新增若干锁机制相关的系统调用:
1/// 功能:为当前进程新增一把互斥锁。
2/// 参数: blocking 为 true 表示互斥锁基于阻塞机制实现,
3/// 否则表示互斥锁基于类似 yield 的方法实现。
4/// 返回值:假设该操作必定成功,返回创建的锁的 ID 。
5/// syscall ID: 1010
6pub fn sys_mutex_create(blocking: bool) -> isize;
7
8/// 功能:当前线程尝试获取所属进程的一把互斥锁。
9/// 参数: mutex_id 表示要获取的锁的 ID 。
10/// 返回值: 0
11/// syscall ID: 1011
12pub fn sys_mutex_lock(mutex_id: usize) -> isize;
13
14/// 功能:当前线程释放所属进程的一把互斥锁。
15/// 参数: mutex_id 表示要释放的锁的 ID 。
16/// 返回值: 0
17/// syscall ID: 1012
18pub fn sys_mutex_unlock(mutex_id: usize) -> isize;
下面来看我们如何基于这些系统调用实现多线程计数器:
1// user/src/bin/adder_mutex_blocking.rs
2
3unsafe fn f() -> ! {
4 let mut t = 2usize;
5 for _ in 0..PER_THREAD {
6 mutex_lock(0);
7 critical_section(&mut t);
8 mutex_unlock(0);
9 }
10 exit(t as i32)
11}
12
13#[unsafe(no_mangle)]
14pub fn main(argc: usize, argv: &[&str]) -> i32 {
15 ...
16 assert_eq!(mutex_blocking_create(), 0);
17 let mut v = Vec::new();
18 for _ in 0..thread_count {
19 v.push(thread_create(linker_symbol_addr!(f), 0) as usize);
20 }
21 ...
22}
在第 16 行我们调用用户库提供的 mutex_blocking_create 在进程内创建一把基于阻塞实现的互斥锁,由于这是进程内创建的第一把锁,其 ID 一定为 0 。接下来,每个线程在执行的函数 f 中,在进入临界区前后分别获取(第 6 行调用 mutex_lock )和释放(第 8 行调用 mutex_unlock )在主线程中创建的 ID 为 0 的锁。这里用到的三个函数都是由用户库直接封装相关系统调用得到的。
那么在内核态这些系统调用是如何实现的呢?在我们的设计中,允许同个进程内的多把锁有着不同的底层实现,这样更加灵活。因此,我们用 Mutex Trait 来规定描述一把互斥锁应该有哪些功能:
// os/src/sync/mutex.rs
pub trait Mutex: Sync + Send {
fn lock(&self);
fn unlock(&self);
}
其实只包含 lock 和 unlock 两个方法。然后,我们可以在进程控制块中新增互斥锁这类资源:
1// os/src/task/process.rs
2
3pub struct ProcessControlBlockInner {
4 ...
5 pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,
6 pub mutex_list: Vec<Option<Arc<dyn Mutex>>>,
7 ...
8}
和文件描述符表 fd_table 一样, mutex_list 使用 Vec<Option<T>> 构建一个含有多个可空槽位且槽位数可以拓展的互斥锁表,表中的每个元素都实现了 Mutex Trait ,是一种互斥锁实现。 sys_mutex_create 会找到第一个空闲的槽位(如果没有则新增一个)并将指定类型的锁的实例插入进来:
1// os/src/syscall/sync.rs
2
3pub fn sys_mutex_create(blocking: bool) -> isize {
4 let process = current_process();
5 let mutex: Option<Arc<dyn Mutex>> = if !blocking {
6 Some(Arc::new(MutexSpin::new()))
7 } else {
8 Some(Arc::new(MutexBlocking::new()))
9 };
10 let mut process_inner = process.inner_exclusive_access();
11 if let Some(id) = process_inner
12 .mutex_list
13 .iter()
14 .enumerate()
15 .find(|(_, item)| item.is_none())
16 .map(|(id, _)| id)
17 {
18 process_inner.mutex_list[id] = mutex;
19 id as isize
20 } else {
21 process_inner.mutex_list.push(mutex);
22 process_inner.mutex_list.len() as isize - 1
23 }
24}
然后是 sys_mutex_lock 和 sys_mutex_unlock 的实现,它们都只是从进程控制块中的互斥锁表的指定槽位中复制一份 Mutex 实现,并调用其 lock 和 unlock 方法。以 sys_mutex_lock 为例:
1// os/src/syscall/sync.rs
2
3pub fn sys_mutex_lock(mutex_id: usize) -> isize {
4 let process = current_process();
5 let process_inner = process.inner_exclusive_access();
6 let mutex = Arc::clone(process_inner.mutex_list[mutex_id].as_ref().unwrap());
7 drop(process_inner);
8 drop(process);
9 mutex.lock();
10 0
11}
目前,我们仅提供了两种互斥锁实现:基于阻塞机制的 MutexBlocking 和基于类似 yield 机制的 MutexSpin ,篇幅原因我们只介绍前者。首先看 MutexBlocking 包含哪些内容:
1// os/src/sync/mutex.rs
2
3pub struct MutexBlocking {
4 inner: UPSafeCell<MutexBlockingInner>,
5}
6
7pub struct MutexBlockingInner {
8 locked: bool,
9 wait_queue: VecDeque<Arc<TaskControlBlock>>,
10}
可以看到,最外层是一个 UPSafeCell ,然后 inner 里面有两个成员:
locked作用和 之前介绍的单标记软件实现 相同,表示目前是否有线程进入临界区。在线程通过sys_mutex_lock系统调用尝试获取锁的时候,如果发现locked为 true ,那么就需要等待locked变为 false ,在此之前都需要被阻塞。wait_queue作为阻塞队列记录所有等待locked变为 false 而被阻塞的线程控制块。
于是,获取和释放锁的实现方式如下:
1// os/src/sync/mutex.rs
2
3impl Mutex for MutexBlocking {
4 fn lock(&self) {
5 let mut mutex_inner = self.inner.exclusive_access();
6 if mutex_inner.locked {
7 mutex_inner.wait_queue.push_back(current_task().unwrap());
8 drop(mutex_inner);
9 block_current_and_run_next();
10 } else {
11 mutex_inner.locked = true;
12 }
13 }
14
15 fn unlock(&self) {
16 let mut mutex_inner = self.inner.exclusive_access();
17 assert!(mutex_inner.locked);
18 if let Some(waking_task) = mutex_inner.wait_queue.pop_front() {
19 wakeup_task(waking_task);
20 } else {
21 mutex_inner.locked = false;
22 }
23 }
24}
对于
lock来说,首先检查是否已经有线程在临界区中。如果locked为 true ,则将当前线程复制一份到阻塞队列中,然后调用block_current_and_run_next阻塞当前线程;否则当前线程可以进入临界区,将locked修改为 true 。对于
unlock来说,简单起见我们假定当前线程一定持有锁(也就是所有的线程一定将lock和unlock配对使用),因此断言locked为 true 。接下来尝试从阻塞队列中取出一个线程,如果存在的话就将这个线程唤醒。被唤醒的线程将继续执行lock并返回,进而回到用户态进入临界区。在此期间locked始终为 true ,相当于 释放锁的线程将锁直接移交给这次唤醒的线程 。反之,如果阻塞队列中没有线程的话,我们则将locked改成 false ,让后来的线程能够进入临界区。
观察 lock 中调用 block_current_and_run_next 的位置,可以发现阻塞在 lock 中的线程一经唤醒便能够立刻进入临界区,因此在 unlock 的时候我们最多只能唤醒一个线程,不然便无法满足互斥访问要求。我们这种实现能够满足一定的公平性,因为我们每次都是唤醒阻塞队列队头的线程,于是每个线程在被阻塞有限时间之后一定能进入临界区。但还有一些其他的互斥锁实现,比如在 unlock 的时候将阻塞队列中的所有线程同时唤醒,感兴趣的同学可自行想想如何实现以及其优缺点。
注解
为什么同样使用单标记,这里却无需用到原子操作?
这里我们仅用到单标记 locked ,为什么无需使用原子指令来保证对于 locked 本身访问的互斥性呢?这其实是因为,RISC-V 架构规定从用户态陷入内核态之后所有(内核态)中断默认被自动屏蔽,也就是说与应用的执行不同, 目前系统调用的执行是不会被中断打断的 。同时,目前我们是在单核上,也 不会有多个 CPU 同时执行系统调用的情况 。在这种情况下,内核态的共享数据访问就仍在 UPSafeCell 的框架之内,只要使用它就能保证互斥访问。
小结#
本节我们从一个多线程计数器的小例子入手,它的结果与我们的预期不同。于是我们以一种通用的方式:即从编译结果,到操作系统调度,再到处理器执行这多个阶段排查出错的原因。我们着重分析由于操作系统调度所导致的不同线程对全局变量 A 的操作出现的 交错 现象,进而引入了 共享资源 、 临界区 以及 互斥 等重要概念。我们介绍了 锁 这种通用的互斥原语的功能和使用方式,还提到了如何评价一种锁的实现:有忙则等待、空闲则入和有界等待这些必须的功能性要求,还有让权等待这种性能层面上的可选要求。
接下来,我们尝试以多种方式实现锁机制。首先我们尝试锁的纯软件实现。第一种方法是设置单变量作为锁标记,但是由于它自身无法支持互斥访问而失败。第二种方式是使用多变量联合表示锁的状态,我们以经典的 Peterson 算法为例说明了它的正确性,但它以及类似的其他算法尤其是在现代 CPU 上存在局限性。
于是我们考虑在硬件的帮助下实现锁机制。一种简单的做法是屏蔽中断保证临界区的原子性,但这种做法需要过度放权给用户态而且在多核环境下无效。另一种做法则是依赖原子指令,我们深入理解了其原子性内涵及其使用范围(仅支持通用存储单位)。我们介绍了经典的 CAS/TAS 型原子指令以及 RISC-V 架构提供的 AMO 和 LR/SC 原子指令,并最终用它们成功简单且高效的实现了锁机制。
随后我们介绍如何基于操作系统支持实现让权等待。一般地,我们列举出了三种不同的等待方式: 忙等 、 yield 轮询 和 阻塞 并分析了它们的优劣势和各自的适用场景。我们着重在我们内核中实现了关键的阻塞机制,并实现了 sleep 和互斥锁系统调用作为其应用。在实际中实现锁的时候,我们可以将软件算法、硬件支持和操作系统支持融合起来,这样才能得到更好的锁实现。
最后,让我们再从整体上回顾一下互斥这一关键概念。可以思考一下为何会存在互斥访问需求?是因为不同线程(或其他执行流,比如说系统调用执行)在执行期间出现了 时间与空间的交集 。空间交集体现为访问同种共享资源,而时间交集体现在对于共享资源的操作或访问在时间上存在交错。只要满足了这两个条件,那就必须考虑使用锁之类的互斥原语对共享资源进行保护。另一种思路则是想办法规避时间或空间交集,这样也能够避免并发问题。
参考文献#
《操作系统概念》第七版,第六章
《Operating Systems: Three Easy Pieces》 Chapter 28 Locks
RISC-V A Standard Extension for Atomic Instructions, Version 2.1