内核第一条指令(实践篇)#
本节导读#
承接上一节,本节我们将实践在 Qemu 上执行内核的第一条指令。首先我们编写内核第一条指令并嵌入到我们的内核项目中,接着指定内核的内存布局使得我们的内核可以正确对接到 Qemu 中。由于 Qemu 的文件加载功能过于简单,它不支持完整的可执行文件,因此我们从内核可执行文件中剥离多余的元数据得到内核镜像并提供给 Qemu 。最后,我们使用 GDB 来跟踪 Qemu 的整个启动流程并验证内核的第一条指令被正确执行。
提示:在进入本节之前请参考 实验环境配置 安装配置 Rust 相关软件包、Qemu软件和 GDB 调试工具等。
编写内核第一条指令#
首先,我们需要编写进入内核后的第一条指令,这样更方便我们验证我们的内核镜像是否正确对接到 Qemu 上。
1 # os/src/entry.asm
2 .section .text.entry
3 .globl _start
4 _start:
5 li x1, 100
实际的指令位于第 5 行,也即 li x1, 100 。 li 是 Load Immediate 的缩写,也即将一个立即数加载到某个寄存器,因此这条指令可以看做将寄存器 x1 赋值为 100 。第 4 行我们声明了一个符号 _start ,该符号指向紧跟在符号后面的内容——也就是位于第 5 行的指令,因此符号 _start 的地址即为第 5 行的指令所在的地址。第 3 行我们告知编译器 _start 是一个全局符号,因此可以被其他目标文件使用。第 2 行表明我们希望将第 2 行后面的内容全部放到一个名为 .text.entry 的段中。一般情况下,所有的代码都被放到一个名为 .text 的代码段中,这里我们将其命名为 .text.entry 从而区别于其他 .text 的目的在于我们想要确保该段被放置在相比任何其他代码段更低的地址上。这样,作为内核的入口点,这段指令才能被最先执行。
接着,我们在 main.rs 中嵌入这段汇编代码,这样 Rust 编译器才能够注意到它,不然编译器会认为它是一个与项目无关的文件:
1// os/src/main.rs
2#![no_std]
3#![no_main]
4
5mod lang_items;
6
7use core::arch::global_asm;
8global_asm!(include_str!("entry.asm"));
第 8 行,我们通过 include_str! 宏将同目录下的汇编代码 entry.asm 转化为字符串并通过 global_asm! 宏嵌入到代码中。
调整内核的内存布局#
由于链接器默认的内存布局并不能符合我们的要求,为了实现与 Qemu 正确对接,我们可以通过 链接脚本 (Linker Script) 调整链接器的行为,使得最终生成的可执行文件的内存布局符合Qemu的预期,即内核第一条指令的地址应该位于 0x80200000 。我们修改 Cargo 的配置文件来使用我们自己的链接脚本 os/src/linker.ld 而非使用默认的内存布局:
1 // os/.cargo/config
2 [build]
3 target = "riscv64gc-unknown-none-elf"
4
5 [target.riscv64gc-unknown-none-elf]
6 rustflags = [
7 "-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes"
8 ]
链接脚本 os/src/linker.ld 如下:
1OUTPUT_ARCH(riscv)
2ENTRY(_start)
3BASE_ADDRESS = 0x80200000;
4
5SECTIONS
6{
7 . = BASE_ADDRESS;
8 skernel = .;
9
10 stext = .;
11 .text : {
12 *(.text.entry)
13 *(.text .text.*)
14 }
15
16 . = ALIGN(4K);
17 etext = .;
18 srodata = .;
19 .rodata : {
20 *(.rodata .rodata.*)
21 *(.srodata .srodata.*)
22 }
23
24 . = ALIGN(4K);
25 erodata = .;
26 sdata = .;
27 .data : {
28 *(.data .data.*)
29 *(.sdata .sdata.*)
30 }
31
32 . = ALIGN(4K);
33 edata = .;
34 .bss : {
35 *(.bss.stack)
36 sbss = .;
37 *(.bss .bss.*)
38 *(.sbss .sbss.*)
39 }
40
41 . = ALIGN(4K);
42 ebss = .;
43 ekernel = .;
44
45 /DISCARD/ : {
46 *(.eh_frame)
47 }
48}
第 1 行我们设置了目标平台为 riscv ;第 2 行我们设置了整个程序的入口点为之前定义的全局符号 _start;
第 3 行定义了一个常量 BASE_ADDRESS 为 0x80200000 ,也就是我们之前提到内核的初始化代码被放置的地址;
从第 5 行开始体现了链接过程中对输入的目标文件的段的合并。其中 . 表示当前地址,也就是链接器会从它指向的位置开始往下放置从输入的目标文件中收集来的段。我们可以对 . 进行赋值来调整接下来的段放在哪里,也可以创建一些全局符号赋值为 . 从而记录这一时刻的位置。我们还能够看到这样的格式:
.rodata : {
*(.rodata)
}
冒号前面表示最终生成的可执行文件的一个段的名字,花括号内按照放置顺序描述将所有输入目标文件的哪些段放在这个段中,每一行格式为 <ObjectFile>(SectionName),表示目标文件 ObjectFile 的名为 SectionName 的段需要被放进去。我们也可以使用通配符来书写 <ObjectFile> 和 <SectionName> 分别表示可能的输入目标文件和段名。因此,最终的合并结果是,在最终可执行文件中各个常见的段 .text, .rodata .data, .bss 从低地址到高地址按顺序放置,每个段里面都包括了所有输入目标文件的同名段,且每个段都有两个全局符号给出了它的开始和结束地址(比如 .text 段的开始和结束地址分别是 stext 和 etext )。
第 12 行我们将包含内核第一条指令的 .text.entry 段放在最终的 .text 段的最开头,同时注意到在最终内存布局中代码段 .text 又是先于任何其他段的。因为所有的段都从 BASE_ADDRESS 也即 0x80200000 开始放置,这就能够保证内核的第一条指令正好放在 0x80200000 从而能够正确对接到 Qemu 上。
此后我们便可以生成内核可执行文件,切换到 os 目录下并进行以下操作:
$ cargo build --release
Finished release [optimized] target(s) in 0.10s
$ file target/riscv64gc-unknown-none-elf/release/os
target/riscv64gc-unknown-none-elf/release/os: ELF 64-bit LSB executable, UCB RISC-V, version 1 (SYSV), statically linked, not stripped
我们以 release 模式生成了内核可执行文件,它的位置在 os/target/riscv64gc.../release/os 。接着我们通过 file 工具查看它的属性,可以看到它是一个运行在 64 位 RISC-V 架构计算机上的可执行文件,它是静态链接得到的。
注解
思考: 0x80200000 可否改为其他地址?
首先需要区分绝对地址和相对地址。在对编译器进行某些设置的情况下,在访问变量或函数时,可以通过它们所在地址与当前某个寄存器(如 PC)的相对地址而非它们位于的绝对地址来访问这些变量或函数。比如,在一个起始地址(即上面提到的 BASE_ADDRESS )固定为 0x80200000 的内存布局中,某个函数入口位于 0x80201111 处,那么我们可以使用其绝对地址 0x80201111 来访问它。但是,如果一条位于 0x80200111 指令会调用该函数,那么这条指令也不一定要用到绝对地址 0x80201111 ,而是用函数入口地址相对于当前指令地址 0x80200111 的相对地址 0x1000 (计算方式为函数入口地址与当前指令地址之差值)来找到并调用该函数。
如果一个程序全程都使用相对地址而不依赖任何绝对地址,那么只要保持好各段之间的相对位置不发生变化,将程序整体加载到内存中的任意位置程序均可正常运行。在这种情况下, BASE_ADDRESS 可以为任意值,我们可以将程序在内存中随意平移。这种程序被称为 位置无关可执行文件(PIE,Position-independent Executable) 。相对的,如果程序依赖绝对地址,那么它一定有一个确定的内存布局,而且该程序必须被加载到与其内存布局一致的位置才能正常运行。由于我们的内核并不是位置无关的,所以我们必须将内存布局的起始地址设置为 0x80200000 ,与之匹配我们也必须将内核加载到这一地址。
注解
静态链接与动态链接
静态链接是指程序在编译时就将所有用到的函数库的目标文件链接到可执行文件中,这样会导致可执行文件容量较大,占用硬盘空间;而动态链接是指程序在编译时仅在可执行文件中记录用到哪些函数库和在这些函数库中用到了哪些符号,在操作系统执行该程序准备将可执行文件加载到内存时,操作系统会检查这些被记录的信息,将用到的函数库的代码和数据和程序一并加载到内存,并进行一些重定位工作,即对装入内存的目标程序中的指令或数据的内存地址进行修改,确保程序运行时能正确找到相关函数或数据。使用动态链接可以显著缩减可执行文件的容量,并使得程序不必在函数库更新后重新链接依然可用。
根据以往的经验, Qemu 模拟的计算机不支持在加载时动态链接,因此我们的内核采用静态链接进行编译。
手动加载内核可执行文件#
上面得到的内核可执行文件完全符合我们对于内存布局的要求,但是我们不能将其直接提交给 Qemu ,因为它除了实际会被用到的代码和数据段之外还有一些多余的元数据,这些元数据无法被 Qemu 在加载文件时利用,且会使代码和数据段被加载到错误的位置。如下图所示:
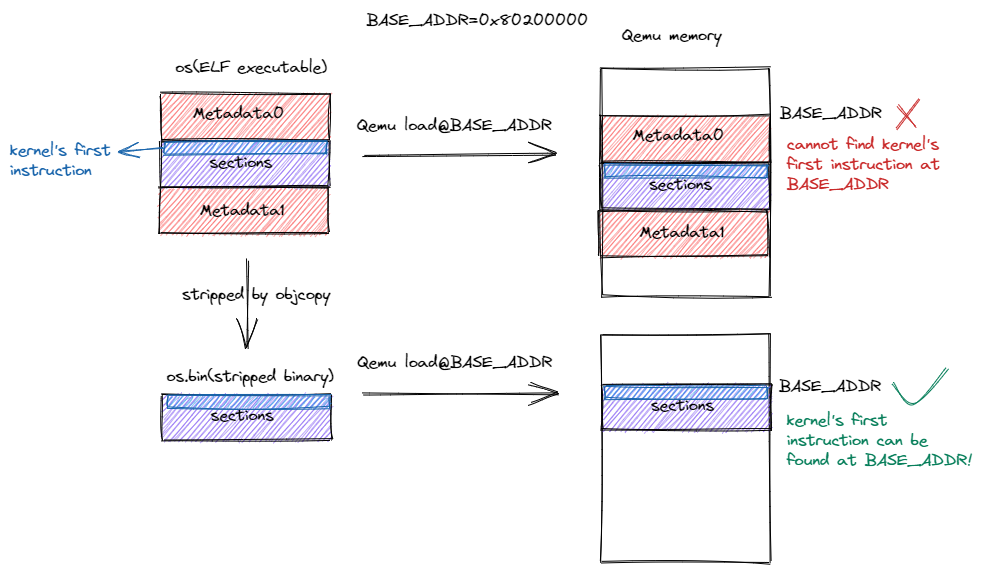
丢弃元数据前后的内核可执行文件被加载到 Qemu 上的情形#
图中,红色的区域表示内核可执行文件中的元数据,深蓝色的区域表示各个段(包括代码段和数据段),而浅蓝色区域则表示内核被执行的第一条指令,它位于深蓝色区域的开头。图示的上半部分中,我们直接将内核可执行文件 os 提交给 Qemu ,而 Qemu 会将整个可执行文件不加处理的加载到 Qemu 内存的 0x80200000 处,由于内核可执行文件的开头是一段元数据,这会导致 Qemu 内存 0x80200000 处无法找到内核第一条指令,也就意味着 RustSBI 无法正常将计算机控制权转交给内核。相反,图示的下半部分中,将元数据丢弃得到的内核镜像 os.bin 被加载到 Qemu 之后,则可以在 0x80200000 处正确找到内核第一条指令。如果想要深入了解这些元数据的内容,可以参考 附录 B:常见工具的使用方法 。
使用如下命令可以丢弃内核可执行文件中的元数据得到内核镜像:
$ rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/release/os -O binary target/riscv64gc-unknown-none-elf/release/os.bin
我们可以使用 stat 工具来比较内核可执行文件和内核镜像的大小:
$ stat target/riscv64gc-unknown-none-elf/release/os
File: target/riscv64gc-unknown-none-elf/release/os
Size: 1016 Blocks: 8 IO Block: 4096 regular file
...
$ stat target/riscv64gc-unknown-none-elf/release/os.bin
File: target/riscv64gc-unknown-none-elf/release/os.bin
Size: 4 Blocks: 8 IO Block: 4096 regular file
...
可以看到,内核镜像的大小仅有 4 字节,这是因为它里面仅包含我们在 entry.asm 中编写的一条指令。一般情况下 RISC-V 架构的一条指令位宽即为 4 字节。而内核可执行文件由于包含了两部分元数据,其大小达到了 1016 字节。这些元数据能够帮助我们更加灵活地加载并使用可执行文件,比如在加载时完成一些重定位工作或者动态链接。不过由于 Qemu 的加载功能过于简单,我们只能将这些元数据丢弃再交给 Qemu 。从某种意义上可以理解为我们手动帮助 Qemu 完成了可执行文件的加载。
注解
新版 Qemu 支持直接加载 ELF
经过我们的实验,至少在 Qemu 7.0.0 版本后,我们可以直接将内核可执行文件 os 提交给 Qemu 而不必进行任何元数据的裁剪工作,这种情况下我们的内核也能正常运行。其具体做法为:将 Qemu 的参数替换为 -device loader,file=path/to/os 。但是,我们仍推荐大家了解并在代码框架和文档中保留这一流程,原因在于这种做法更加通用,对环境和工具的依赖程度更低。
基于 GDB 验证启动流程#
在 os 目录下通过以下命令启动 Qemu 并加载 RustSBI 和内核镜像:
1$ qemu-system-riscv64 \
2 -machine virt \
3 -nographic \
4 -bios ../bootloader/rustsbi-qemu.bin \
5 -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 \
6 -s -S
-s 可以使 Qemu 监听本地 TCP 端口 1234 等待 GDB 客户端连接,而 -S 可以使 Qemu 在收到 GDB 的请求后再开始运行。因此,Qemu 暂时没有任何输出。注意,如果不想通过 GDB 对于 Qemu 进行调试而是直接运行 Qemu 的话,则要删掉最后一行的 -s -S 。
打开另一个终端,启动一个 GDB 客户端连接到 Qemu :
$ riscv64-unknown-elf-gdb \
-ex 'file target/riscv64gc-unknown-none-elf/release/os' \
-ex 'set arch riscv:rv64' \
-ex 'target remote localhost:1234'
[GDB output]
0x0000000000001000 in ?? ()
可以看到,正如我们在上一节提到的那样,Qemu 启动后 PC 被初始化为 0x1000 。我们可以检查一下 Qemu 的启动固件的内容:
$ (gdb) x/10i $pc
=> 0x1000: auipc t0,0x0
0x1004: addi a1,t0,32
0x1008: csrr a0,mhartid
0x100c: ld t0,24(t0)
0x1010: jr t0
0x1014: unimp
0x1016: unimp
0x1018: unimp
0x101a: 0x8000
0x101c: unimp
这里 x/10i $pc 的含义是从当前 PC 值的位置开始,在内存中反汇编 10 条指令。不过可以看到 Qemu 的固件仅包含 5 条指令,从 0x1014 开始都是数据,当数据为 0 的时候则会被反汇编为 unimp 指令。 0x101a 处的数据 0x8000 是能够跳转到 0x80000000 进入启动下一阶段的关键。有兴趣的读者可以自行探究位于 0x1000 和 0x100c 两条指令的含义。总之,在执行位于 0x1010 的指令之前,寄存器 t0 的值恰好为 0x80000000 ,随后通过 jr t0 便可以跳转到该地址。我们可以通过单步调试来复盘这个过程:
$ (gdb) si
0x0000000000001004 in ?? ()
$ (gdb) si
0x0000000000001008 in ?? ()
$ (gdb) si
0x000000000000100c in ?? ()
$ (gdb) si
0x0000000000001010 in ?? ()
$ (gdb) p/x $t0
$1 = 0x80000000
$ (gdb) si
0x0000000080000000 in ?? ()
其中, si 可以让 Qemu 每次向下执行一条指令,之后屏幕会打印出待执行的下一条指令的地址。 p/x $t0 以 16 进制打印寄存器 t0 的值,注意当我们要打印寄存器的时候需要在寄存器的名字前面加上 $ 。可以看到,当位于 0x1010 的指令执行完毕后,下一条待执行的指令位于 RustSBI 的入口,也即 0x80000000 ,这意味着我们即将把控制权转交给 RustSBI 。
$ (gdb) x/10i $pc
=> 0x80000000: auipc sp,0x28
0x80000004: mv sp,sp
0x80000008: lui t0,0x4
0x8000000a: addi t1,a0,1
0x8000000e: add sp,sp,t0
0x80000010: addi t1,t1,-1
0x80000012: bnez t1,0x8000000e
0x80000016: j 0x8001125a
0x8000001a: unimp
0x8000001c: addi sp,sp,-48
$ (gdb) si
0x0000000080000004 in ?? ()
$ (gdb) si
0x0000000080000008 in ?? ()
$ (gdb) si
0x000000008000000a in ?? ()
$ (gdb) si
0x000000008000000e in ?? ()
我们可以用同样的方式反汇编 RustSBI 最初的几条指令并单步调试。不过由于 RustSBI 超出了本书的范围,我们这里并不打算进行深入。接下来我们检查控制权能否被移交给我们的内核:
$ (gdb) b *0x80200000
Breakpoint 1 at 0x80200000
$ (gdb) c
Continuing.
Breakpoint 1, 0x0000000080200000 in ?? ()
我们在内核的入口点,也即地址 0x80200000 处打一个断点。需要注意,当需要在一个特定的地址打断点时,需要在地址前面加上 * 。接下来通过 c 命令(Continue 的缩写)让 Qemu 向下运行直到遇到一个断点。可以看到,我们成功停在了 0x80200000 处。随后,可以检查内核第一条指令是否被正确执行:
$ (gdb) x/5i $pc
=> 0x80200000: li ra,100
0x80200004: unimp
0x80200006: unimp
0x80200008: unimp
0x8020000a: unimp
$ (gdb) si
0x0000000080200004 in ?? ()
$ (gdb) p/d $x1
$2 = 100
$ (gdb) p/x $sp
$3 = 0x0
可以看到我们在 entry.asm 中编写的第一条指令可以在 0x80200000 处找到。这里 ra 是寄存器 x1 的别名, p/d $x1 可以以十进制打印寄存器 x1 的值,它的结果正确。最后,作为下一节的铺垫,我们可以检查此时栈指针 sp 的值,可以发现它目前是 0 。下一节我们将设置好栈空间,使得内核代码可以正常进行函数调用,随后将控制权转交给 Rust 代码。