应用程序执行环境与平台支持#
本节导读#
本节我们从一个最简单的 Rust 应用程序入手,深入地挖掘它下面的多层执行环境,分析编译器和操作系统为应用程序的开发和运行提供了怎样的便利条件。需要注意的是,LibOS操作系统也是一层执行环境,因此它需要为上层的应用程序提供服务。我们会接触到计算机科学中最核心的思想 – 抽象,同时以现实中不同需求层级的应用为例分析如何进行合理的抽象。最后,我们还会介绍软硬件平台(包括 RISC-V 架构)的一些基础知识。
执行应用程序#
我们先在Linux上开发并运行一个简单的 “Hello, world” 应用程序,看看一个简单应用程序从开发到执行的全过程。作为一切的开始,让我们使用 Cargo 工具来创建一个 Rust 项目。它看上去没有任何特别之处:
$ cargo new os --bin
我们加上了 --bin 选项来告诉 Cargo 我们创建一个可执行程序项目而不是函数库项目。此时,项目的文件结构如下:
$ tree os
os
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
其中 Cargo.toml 中保存着项目的配置,包括作者的信息、联系方式以及库依赖等等。显而易见源代码保存在 src 目录下,目前为止只有 main.rs 一个文件,让我们看一下里面的内容:
1fn main() {
2 println!("Hello, world!");
3}
进入 os 项目根目录下,利用 Cargo 工具即可一条命令实现构建并运行项目:
$ cargo run
Compiling os v0.1.0 (/home/shinbokuow/workspace/v3/rCore-Tutorial-v3/os)
Finished dev [unoptimized + debuginfo] target(s) in 1.15s
Running `target/debug/os`
Hello, world!
如我们预想的一样,我们在屏幕上看到了一行 Hello, world! 。但是,需要注意到我们所享受到的编程和执行程序的方便性并不是理所当然的,背后有着从硬件到软件多种机制的支持。特别是对于应用程序的运行,需要有一个强大的执行环境来帮助。接下来,我们就要看看有操作系统加持的强大的执行环境。
应用程序执行环境#
如下图所示,现在通用操作系统(如 Linux 等)上的应用程序运行需要下面多层次的执行环境栈的支持,图中的白色块自上而下(越往下则越靠近底层,下层作为上层的执行环境支持上层代码的运行)表示各级执行环境,黑色块则表示相邻两层执行环境之间的接口。
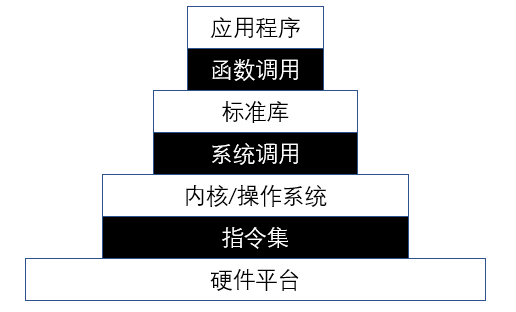
应用程序执行环境栈#
我们的应用位于最上层,它可以通过调用编程语言提供的标准库或者其他三方库对外提供的函数接口,使得仅需少量的源代码就能完成复杂的功能。但是这些库的功能不仅限于此,事实上它们属于应用程序 执行环境 (Execution Environment)的一部分。在我们通常不会注意到的地方,这些软件库还会在执行应用之前完成一些初始化工作,并在应用程序执行的时候对它进行监控。我们在打印 Hello, world! 时使用的 println! 宏正是由 Rust 标准库 std提供的。
从操作系统内核的角度看来,它上面的一切都属于用户态软件,而它自身属于内核态软件。无论用户态应用如何编写,是手写汇编代码,还是基于某种高级编程语言调用其标准库或三方库,某些功能总要直接或间接的通过操作系统内核提供的 系统调用 (System Call) 来实现。因此系统调用充当了用户和内核之间的边界。内核作为用户态软件的执行环境,它不仅要提供系统调用接口,还需要对用户态软件的执行进行监控和管理。
注解
Hello, world! 用到了哪些系统调用?
从之前的 cargo run 的输出可以看出之前构建的可执行文件是在 target/debug 目录下的 os 。在 Ubuntu 系统上,可以通过 strace 工具来运行一个程序并输出程序运行过程当中向内核请求的所有的系统调用及其返回值。我们只需输入 strace target/debug/os 即可看到一长串的各种系统调用。
其中,容易看出与 Hello, world! 应用实际执行相关的只有两个系统调用:
# 输出字符串
write(1, "Hello, world!\n", 14) = 14
# 程序退出执行
exit_group(0)
其参数的具体含义我们暂且不在这里进行解释。
其余的系统调用基本上分别用于函数库和内核两层执行环境的初始化工作和对上层应用的运行进行监控和管理。之后,随着应用场景的复杂化,操作系统需要提供更强的硬件抽象能力和资源管理能力,并实现相关的一些系统调用。
从硬件的角度来看,它上面的一切都属于软件。硬件可以分为三种: 处理器 (Processor,也称CPU),内存 (Memory) 还有 I/O 设备。其中处理器无疑是其中最复杂,同时也最关键的一个。它与软件约定一套 指令集体系结构 (ISA, Instruction Set Architecture),使得软件可以通过 ISA 中提供的机器指令来访问各种硬件资源。软件当然也需要知道处理器会如何执行这些指令,以及指令执行后的结果。当然,实际的情况远比这个要复杂得多,为了适应现代应用程序的场景,处理器还需要提供很多额外的机制(如特权级、页表、TLB、异常/中断响应等)来管理应用程序的执行过程,而不仅仅是让数据在 CPU 寄存器、内存和 I/O 设备三者之间流动。
注解
计算机科学中遇到的所有问题都可通过增加一层抽象来解决。
All problems in computer science can be solved by another level of indirection。
– 计算机科学家 David Wheeler
注解
多层执行环境都是必需的吗?
除了最上层的应用程序和最下层的硬件平台必须存在之外,作为中间层的函数库和操作系统内核并不是必须存在的: 它们都是对下层资源进行了 抽象 (Abstraction/Indirection),并为上层提供了一个执行环境(也可理解为一些服务功能)。抽象的优点在于它让上层以较小的代价获得所需的功能,并同时可以提供一些保护。但抽象同时也是一种限制,会丧失一些应有的灵活性。比如,当你在考虑在项目中应该使用哪个函数库的时候,就常常需要这方面的权衡:过多的抽象和过少的抽象自然都是不合适的。理解应用的需求也很重要。一个能合理满足应用需求的操作系统设计是操作系统设计者需要深入考虑的问题。这也是一种权衡,过多的服务功能和过少的服务功能自然都是不合适的。
实际上,我们通过应用程序的特征和需求来判断操作系统需要什么程度的抽象和功能。
如果函数库和操作系统内核都不存在,那么我们就需要手写汇编代码来控制硬件,这种方式具有最高的灵活性,抽象能力则最低,基本等同于编写汇编代码来直接控制硬件。我们通常用这种方式来实现一些架构相关且仅通过高级编程语言无法描述的小模块或者代码片段。
如果仅存在函数库而不存在操作系统内核,意味着我们不需要操作系统内核提供过于通用的抽象。在那些功能单一的嵌入式场景就常常会出现这种情况。嵌入式设备虽然也包含处理器、内存和 I/O 设备,但是它上面通常只会同时运行一个或几个功能非常简单的小应用程序,比如定时显示、实时采集数据、人脸识别打卡系统等。常见的解决方案是仅使用函数库构建单独的应用程序或是用专为应用场景特别裁减过的轻量级函数库管理少数应用程序。这就只需要一层函数库形态的执行环境。
如果存在函数库和操作系统内核,这意味着应用需求比较多样,会需要并发执行。常见的通用操作系统如 Windows/Linux/macOS 等都支持并发运行多个不同的应用程序。为此需要更加强大的操作系统抽象和功能,也就会需要多层执行环境。
注解
“用力过猛”的现代操作系统
对于如下更简单的小应用程序,我们可以看到“用力过猛”的现代操作系统提供的执行环境支持:
1//ch1/donothing.rs
2fn main() {
3 //do nothing
4}
对于这个程序,在它的执行过程中,几乎感知不到它存在感。在编译后运行,可以看到的情况是:
$ rustc donothing.rs
$ ./donothing
$ (无输出)
与我们预计一样,程序执行后,看不到有何明显的输出信息,程序非常快地就结束了。但如果通过监视程序系统调用请求的工具 strace 来重新执行一下这个程序,就可以看到程序执行过程中的大量动态信息:
$ strace ./donothing
(多达 93 行的输出,表明 donothing 向 Linux 操作系统内核发出了93次各种各样的系统调用)
execve("./donothing", ["./donothing"], 0x7ffe02c9ca10 /* 67 vars */) = 0
brk(NULL) = 0x563ba0532000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fff2da54360) = -1 EINVAL (无效的参数)
......
这说明了现在的操作系统,如 Linux ,为了通用性,而实现了大量的功能。但对于非常简单的程序而言,有很多的功能是多余的。
目标平台与目标三元组#
注解
现代编译器工具集(以C或Rust编译器为例)的主要工作流程如下:
源代码(source code) –> 预处理器(preprocessor) –> 宏展开的源代码
宏展开的源代码 –> 编译器(compiler) –> 汇编程序
汇编程序 –> 汇编器(assembler)–> 目标代码(object code)
目标代码 –> 链接器(linker) –> 可执行文件(executables)
对于一份用某种编程语言实现的应用程序源代码而言,编译器在将其通过编译、链接得到可执行文件的时候需要知道程序要在哪个 平台 (Platform) 上运行。这里平台主要是指 CPU 类型、操作系统类型和标准运行时库的组合。从上面给出的 应用程序执行环境栈 可以看出:
如果用户态基于的内核不同,会导致系统调用接口不同或者语义不一致;
如果底层硬件不同,对于硬件资源的访问方式会有差异。特别是如果 ISA 不同,则向软件提供的指令集和寄存器都不同。
它们都会导致最终生成的可执行文件有很大不同。需要指出的是,某些编译器支持同一份源代码无需修改就可编译到多个不同的目标平台并在上面运行。这种情况下,源代码是 跨平台 的。而另一些编译器则已经预设好了一个固定的目标平台。
Rust编译器通过 目标三元组 (Target Triplet) 来描述一个软件运行的目标平台。它一般包括 CPU、操作系统和运行时库等信息,从而控制Rust编译器可执行代码生成。比如,我们可以尝试看一下之前的 Hello, world! 的目标平台是什么。这可以通过打印编译器 rustc 的默认配置信息:
$ rustc --version --verbose
rustc 1.x.y
binary: rustc
commit-hash: ...
commit-date: ...
host: x86_64-unknown-linux-gnu
release: 1.x.y
LLVM version: ...
从其中的 host 一项可以看出默认的目标平台是 x86_64-unknown-linux-gnu,其中 CPU 架构是 x86_64,CPU 厂商是 unknown,操作系统是 linux,运行时库是 GNU libc(封装了 Linux 系统调用,并提供 POSIX 接口为主的函数库)。这种无论编译器还是其生成的可执行文件都在我们当前所处的平台运行是一种最简单也最普遍的情况。但是很快我们就将遇到另外一种情况。
讲了这么多,终于该介绍我们的主线任务了。我们希望能够在另一个硬件平台上运行 Hello, world!,而与之前的默认平台不同的地方在于,我们将 CPU 架构从 x86_64 换成 RISC-V。
可以看一下目前 Rust 编译器支持哪些基于 RISC-V 的目标平台:
$ rustc --print target-list | grep riscv
riscv32gc-unknown-linux-gnu
riscv32i-unknown-none-elf
riscv32imac-unknown-none-elf
riscv32imc-unknown-none-elf
riscv64gc-unknown-linux-gnu
riscv64gc-unknown-none-elf
riscv64imac-unknown-none-elf
这里我们选择 riscv64gc-unknown-none-elf 目标平台。这其中的 CPU 架构是 riscv64gc ,CPU厂商是 unknown ,操作系统是 none , elf 表示没有标准的运行时库(表明没有任何系统调用的封装支持),但可以生成 ELF 格式的执行程序。这里我们之所以不选择有 linux-gnu 系统调用支持的目标平台 riscv64gc-unknown-linux-gnu,是因为我们只是想跑一个在裸机环境上运行的 Hello, world! 应用程序,没有必要使用Linux操作系统提供的那么高级的抽象和多余的操作系统服务。而且我们很清楚后续我们要开发的是一个操作系统内核,它必须直面底层物理硬件(bare-metal)来提供精简的操作系统服务功能,通用操作系统(如 Linux)提供的很多系统调用服务对这个内核而言是多余的。
注解
RISC-V 指令集拓展
由于基于 RISC-V 架构的处理器可能用于嵌入式场景或是通用计算场景,因此指令集规范将指令集划分为最基本的 RV32/64I 以及若干标准指令集拓展。每款处理器只需按照其实际应用场景按需实现指令集拓展即可。
RV32/64I:每款处理器都必须实现的基本整数指令集。在 RV32I 中,每个通用寄存器的位宽为 32 位;在 RV64I 中则为 64 位。它可以用来模拟绝大多数标准指令集拓展中的指令,除了比较特殊的 A 拓展,因为它需要特别的硬件支持。
M 拓展:提供整数乘除法相关指令。
A 拓展:提供原子指令和一些相关的内存同步机制,这个后面会展开。
F/D 拓展:提供单/双精度浮点数运算支持。
C 拓展:提供压缩指令拓展。
G 拓展是基本整数指令集 I 再加上标准指令集拓展 MAFD 的总称,因此 riscv64gc 也就等同于 riscv64imafdc。我们剩下的内容都基于该处理器架构完成。除此之外 RISC-V 架构还有很多标准指令集拓展,有一些还在持续更新中尚未稳定,有兴趣的同学可以浏览最新版的 RISC-V 指令集规范。
Rust 标准库与核心库#
我们尝试一下将当前的 Hello, world! 程序的目标平台换成 riscv64gc-unknown-none-elf 看看会发生什么事情:
$ cargo run --target riscv64gc-unknown-none-elf
Compiling os v0.1.0 (/home/shinbokuow/workspace/v3/rCore-Tutorial-v3/os)
error[E0463]: can't find crate for `std`
|
= note: the `riscv64gc-unknown-none-elf` target may not be installed
在之前的开发环境配置中,我们已经在 rustup 工具链中安装了这个目标平台支持,因此并不是该目标平台未安装的问题。这个问题只是单纯的表示在这个目标平台上找不到 Rust 标准库 std。我们之前曾经提到过,编程语言的标准库或三方库的某些功能会直接或间接的用到操作系统提供的系统调用。但目前我们所选的目标平台不存在任何操作系统支持,于是 Rust 并没有为这个目标平台支持完整的标准库 std。类似这样的平台通常被我们称为 裸机平台 (bare-metal)。这意味着在裸机平台上的软件没有传统操作系统支持。
注解
Rust Tips:Rust语言标准库std和核心库core
Rust 语言标准库–std 是让 Rust 语言开发的软件具备可移植性的基础,类似于 C 语言的 LibC 标准库。它是一组小巧的、经过实践检验的共享抽象,适用于更广泛的 Rust 生态系统开发。它提供了核心类型,如 Vec 和 Option、类库定义的语言原语操作、标准宏、I/O 和多线程等。默认情况下,我们可以使用 Rust 语言标准库来支持 Rust 应用程序的开发。但 Rust 语言标准库的一个限制是,它需要有操作系统的支持。所以,如果你要实现的软件是运行在裸机上的操作系统,就不能直接用 Rust 语言标准库了。
幸运的是,Rust 有一个对 Rust 语言标准库–std 裁剪过后的 Rust 语言核心库 core。core库是不需要任何操作系统支持的,它的功能也比较受限,但是也包含了 Rust 语言相当一部分的核心机制,可以满足我们的大部分功能需求。Rust 语言是一种面向系统(包括操作系统)开发的语言,所以在 Rust 语言生态中,有很多三方库也不依赖标准库 std 而仅仅依赖核心库 core。对它们的使用可以很大程度上减轻我们的编程负担。它们是我们能够在裸机平台挣扎求生的最主要倚仗,也是大部分运行在没有操作系统支持的 Rust 嵌入式软件的必备。
于是,我们知道在裸机平台上我们要将对于标准库 std 的引用换成核心库 core。但是实际做起来其实还要有一些琐碎的事情需要解决。