内核态的线程管理#
本节导读#
在上一节介绍了如何在用户态实现对多线程的管理,让同学对多线程的实际运行机制:创建线程、切换线程等有了一个比较全面的认识。由于在用户态进行线程管理,带了的一个潜在不足是没法让线程管理运行时直接切换线程,只能等当前运行的线程主动让出处理器使用权后,线程管理运行时才能切换检查。而我们的操作系统运行在处理器内核态,如果扩展一下对线程的管理,那就可以基于时钟中断来直接打断当前用户态线程的运行,实现对线程的调度和切换等。
本节参考上一节的用户态线程管理机制,结合之前的操作系统实现:具有UNIX操作系统基本功能的 “迅猛龙” 操作系统,进化为更加迅捷的 “达科塔盗龙” 1 操作系统,我们首先分析如何扩展现有的进程,以支持线程管理。然后设计线程的总体结构、管理线程执行的线程控制块数据结构、以及对线程管理相关的重要函数:线程创建和线程切换。并最终合并到现有的进程管理机制中。本节的内容能帮助我们理解进程和线程的关系,二者在设计思想与具体实现上的差异,为后续支持各种并发机制打下基础。
注解
为何要在这里才引入线程
学生对进程有一定了解后,再来理解线程也会更加容易。因为从对程序执行的控制流进行调度和切换上看,本章讲解的线程调度与切换操作是之前讲解的进程调度与切换的一个子集。另外,在这里引入线程的一个重要原因是为了便于引入并发。没在进程阶段引入并发这个专题的原因是,进程主要的目的是隔离,而线程的引入强调了共享,即属于同一进程的多个线程可共享进程的资源,这样就必须要解决同步问题了。
线程概念#
这里会结合与进程的比较来说明线程的概念。到本章之前,我们看到了进程这一抽象,操作系统让进程拥有相互隔离的虚拟的地址空间,让进程感到在独占一个虚拟的处理器。其实这只是操作系统通过时分复用和空分复用技术来让每个进程复用有限的物理内存和物理CPU。而线程是在进程内的一个新的抽象。在没有线程之前,一个进程在一个时刻只有一个执行点(即程序计数器 PC 寄存器保存的要执行指令的指针以及栈的位置)。线程的引入把进程内的这个单一执行点给扩展为多个执行点,即在进程中存在多个线程,每个线程都有一个执行点。而且这些线程共享进程的地址空间,所以可以不必采用相对比较复杂的进程间通信机制(一般需要内核的介入)也可以很方便地直接访问进程内的数据进行协作。
在线程的具体运行过程中,需要有程序计数器寄存器来记录当前的执行位置,需要有一组通用寄存器记录当前的指令的操作数据,需要有一个栈作为线程执行过程的函数调用栈保存局部变量等内容,这就形成了线程上下文的主体部分。这样如果两个线程运行在一个处理器上,就需要采用类似两个进程运行在一个处理器上的调度/切换管理机制,即需要在一定时刻进行线程切换,并进行线程上下文的保存与恢复。这样在一个进程中的多线程可以独立运行,取代了进程,成为操作系统调度的基本单位。
由于把进程的结构进行了细化,通过线程来表示对处理器的虚拟化,使得进程成为了管理线程的容器。在进程中的线程没有父子关系,大家都是兄弟,但还是有个老大。这个代表老大的线程其实就是创建进程(比如通过 fork 系统调用创建进程)时建立的第一个线程,我们称之为主线程。类似于进程标识符(PID),每个线程都有一个在所属进程内生效的线程标识符(TID),同进程下的两个线程有着不同的 TID ,可以用来区分它们。主线程由于最先被创建,它的 TID 固定为 0 。
通用操作系统多线程应用程序示例#
当创建一个进程的时候,如果是基于 fork 系统调用的话,子进程会和父进程一样从系统调用返回后的下一条指令开始执行;如果是基于 exec 系统调用的话,子进程则会从新加载程序的入口点开始执行。而对于线程的话,除了主线程仍然从程序入口点(一般是 main 函数)开始执行之外,每个线程的生命周期都与程序中的一个函数的一次执行绑定。也就是说,线程从该函数入口点开始执行,当函数返回之后,线程也随之退出。因此,在创建线程的时候我们需要提供程序中的一个函数让线程来执行这个函数。
我们用 C 语言中的线程 API 来举例说明。在 C 语言中,常用的线程接口为 pthread 系列 API,这里的 pthread 意为 POSIX thread 即 POSIX 线程。这组 API 被很多不同的内核实现所支持,基于它实现的应用很容易在不同的平台间移植。pthread 创建线程的接口 pthread_create 如下:
#include <pthread.h>
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
其中:
第一个参数为一个类型为
pthread_t的线程结构体的指针。在实际创建线程之前我们首先要创建并初始化一个pthread_t的实例,它与线程一一对应,线程相关的操作都要通过它来进行。通过第二个参数我们可以对要创建的线程进行一些配置,比如内核应该分配给这个线程多少栈空间。简单起见我们这里不展开。
第三个参数为一个函数指针,表示创建的线程要执行哪个函数。观察函数签名可以知道该函数的参数和返回值类型均被要求为一个
void *,这样是为了兼容各种不同的线程函数,因为void *可以和各种类型的指针相互转换。在声明函数的时候要遵循这个约定,但实现的时候我们常常需要首先将void *转化为具体类型的指针。第四个参数为传给线程执行的函数的参数,类型为
void *,和函数签名中的约定一致。需要这个参数的原因是:方便区分,我们常常会让很多线程执行同一个函数,但可以传给它们不同的参数,以这种手段来对它们进行区分。
让我们来看一个例子:
1#include <stdio.h>
2#include <pthread.h>
3
4typedef struct {
5 int x;
6 int y;
7} FuncArguments;
8
9void *func(void *arg) {
10 FuncArguments *args = (FuncArguments*)arg;
11 printf("x=%d,y=%d\n", args->x, args->y);
12}
13
14void main() {
15 pthread_t t0, t1, t2;
16 FuncArguments args[3] = {{1, 2}, {3, 4}, {5, 6}};
17 pthread_create(&t0, NULL, func, &args[0]);
18 pthread_create(&t1, NULL, func, &args[1]);
19 pthread_create(&t2, NULL, func, &args[2]);
20 pthread_join(t0, NULL);
21 pthread_join(t1, NULL);
22 pthread_join(t2, NULL);
23 return;
24}
第 4~7 行我们声明线程函数接受的参数类型为一个名为
FuncArguments的结构体,内含x和y两个字段。第 15 行我们创建并默认初始化三个
pthread_t实例t0、t1和t2,分别代表我们接下来要创建的三个线程。第 16 行在主线程的栈上给出三个线程接受的参数。
第 9~12 行实现线程运行的函数
func,可以看到它的函数签名符合要求。它实际接受的参数类型应该为我们之前定义的FuncArguments类型的指针,但是在函数签名中是一个void *,所以在第 10 行我们首先进行类型转换得到FuncArguments*,而后才能访问x和y两个字段并打印出来。第 17~19 行使用
pthread_create创建三个线程,分别绑定到t0~t2三个pthread_t实例上。它们均执行func函数,但接受的参数有所不同。
编译运行,一种可能的输出为:
x=1,y=2
x=5,y=6
x=3,y=4
从中可以看出,线程的实际执行顺序不一定和我们创建它们的顺序相同。在创建完三个线程之后,同时存在四个线程,即创建的三个线程和主线程,它们的执行顺序取决于操作系统如何调度它们。这可能导致主线程先于我们创建的线程结束,在一些内核实现中,这种情况下整个进程直接退出,于是我们创建的线程也直接被删除,未正常返回,没有达到我们期望的效果。为了解决这个问题,我们可以使用 pthread_join 函数来使主线程等待某个线程退出之后再继续向下执行。其函数签名为:
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
我们需要传入线程对应的 pthread_t 实例来等待一个线程退出。另一个参数 retval 是用来捕获线程函数的返回值,我们这里不展开。上面代码片段的第 20~22 行我们便要求主线程依次等待我们创建的三个线程退出之后再退出,这样主线程就不会影响到其他线程的执行。
在开发 Rust 多线程应用的时候,我们也可以使用标准库 std::thread 中提供的 API 来创建、管理或结束线程。其中:
std::thread::spawn类似于pthread_create,可以创建一个线程,它会返回一个JoinHandle代表创建的线程;std::thread::JoinHandle::join类似于pthread_join,用来等待调用join的JoinHandle对应的线程结束。
下面使用 Rust 重写上面基于 C 语言的多线程应用:
1use std::thread;
2struct FuncArguments {
3 x: i32,
4 y: i32,
5}
6fn func(args: FuncArguments) -> i32 {
7 println!("x={},y={}", args.x, args.y);
8 args.x + args.y
9}
10fn main() {
11 let v = vec![
12 thread::spawn(|| func(FuncArguments {x: 1, y: 2})),
13 thread::spawn(|| func(FuncArguments {x: 3, y: 4})),
14 thread::spawn(|| func(FuncArguments {x: 5, y: 6})),
15 ];
16 for handle in v {
17 println!("result={}", handle.join().unwrap());
18 }
19}
可以看到,相比 C 语言,在 Rust 实现中无需进行繁琐的类型转换,直接正常将参数传入 thread::spawn 所需的闭包中即可。同时使用 handle.join 即可接收线程函数的返回值。一种可能的运行结果如:
x=1,y=2
result=3
x=3,y=4
x=5,y=6
result=7
result=11
从中可以观察到主线程和我们创建的线程在操作系统的调度下交错运行。
为了在 “达科塔盗龙” 1 操作系统中实现类似 Linux 操作系统的多线程支持,我们需要建立精简的线程模型和相关系统调用,并围绕这两点来改进操作系统。
线程模型与重要系统调用#
目前,我们只介绍本章实现的内核中采用的一种非常简单的线程模型。这个线程模型有如下特征:
线程有三种状态:就绪态、运行态和阻塞态(阻塞态是本章后面并发部分的重点概念,到时会详细讲解);
同进程下的所有线程共享所属进程的地址空间和其他共享资源(如文件等);
线程可被操作系统调度来分时占用 CPU 执行;
线程可以动态创建和退出;
同进程下的多个线程不像进程一样存在父子关系,但有一个特殊的主线程在它所属进程被创建的时候产生,应用程序的
main函数就运行在这个主线程上。当主线程退出后,整个进程立即退出,也就意味着不论进程下的其他线程处于何种状态也随之立即退出;线程可通过系统调用获得操作系统的服务。注意线程和进程两个系列的系统调用不能混用。
我们实现的线程模型建立在进程的地址空间抽象之上:同进程下的所有线程共享该进程的地址空间,包括代码段和数据段。从逻辑上来说某些段是由所有线程共享的(比如包含代码中的全局变量的全局数据段),而某些段是由某个线程独占的(比如操作系统为每个线程分配的栈),通常情况下程序员会遵循这种约定。然而,线程之间并不能严格做到隔离。举例来说,一个线程访问另一个线程的栈这种行为并不会被操作系统和硬件禁止。这也体现了线程和进程的不同:线程的诞生是为了方便共享,而进程更强调隔离。
此外,线程模型还需要操作系统支持一些重要的系统调用:创建线程、等待线程结束等来支持灵活的多线程应用。接下来我们介绍这些系统调用的基本功能和设计思路。
线程的创建#
在我们的内核中,通过 thread_create 系统调用可以创建一个从属于当前进程的线程。类似于 C 标准库中的 pthread_create ,我们也需要传入线程运行的函数的入口地址和函数接受的参数。不同之处在于: pthread 系列 API 中基于 pthread_t 实例对线程进行控制,而我们则是用线程的线程标识符(TID, Thread Identifier)来区分不同线程并对指定线程进行控制,这一点类似于进程的控制方式。因此,在没有出错的情况下,我们的 thread_create 系统调用会返回创建的线程的 TID 。具体系统调用原型如下:
1/// 功能:当前进程创建一个新的线程
2/// 参数:entry 表示线程的入口函数地址,arg 表示传给线程入口函数参数
3/// 返回值:创建的线程的 TID
4/// syscall ID: 1000
5pub fn sys_thread_create(entry: usize, arg: usize) -> isize;
内核会为每个线程分配一组专属于该线程的资源:用户栈、Trap 上下文还有内核栈,前面两个在进程地址空间中,内核栈在内核地址空间中。这样这些线程才能相对独立地被调度和执行。相比于创建进程的 fork 系统调用,创建线程无需建立新的地址空间,这是二者之间最大的不同。另外属于同一进程中的线程之间没有父子关系,这一点也与进程不一样。
简单线程管理#
类似 getpid ,我们新增了一个 gettid 的系统调用可以获取当前线程的 TID,其 syscall ID 为1001 。由于比较简单,在这里不再赘述。
线程退出及资源回收#
在 C/Rust 语言实现的多线程应用中,当线程执行的函数返回之后线程会自动退出,在编程的时候无需对函数做任何特殊处理。其实现原理是当函数返回之后,会自动跳转到用户态一段预先设置好的代码,在这段代码中通过系统调用实现线程退出操作。在这里,我们为了让实现更加简单,约定线程函数需要在返回之前通过 exit 系统调用退出。这里 exit 系统调用的含义发生了变化:从进程退出变成线程退出。
内核在收到线程发出的 exit 系统调用后,会回收线程占用的用户态资源,包括用户栈和 Trap 上下文等。线程占用的内核态资源(包括内核栈等)则需要在进程内使用 waittid 系统调用来回收,这样该线程占用的资源才能被完全回收。 waittid 的系统调用原型如下:
1/// 功能:等待当前进程内的一个指定线程退出
2/// 参数:tid 表示指定线程的 TID
3/// 返回值:如果线程不存在,返回-1;如果线程还没退出,返回-2;其他情况下,返回结束线程的退出码
4/// syscall ID: 1002
5pub fn sys_waittid(tid: usize) -> i32;
waittid 基本上就是把我们比较熟悉的 waitpid 的操作对象从进程换成了线程,使用方法也和 waitpid 比较像。它像 pthread_join 一样能起到一定的同步作用,也能够彻底回收一个线程的资源。一般情况下进程/主线程要负责通过 waittid 来等待它创建出来的线程(不是主线程)结束并回收它们在内核中的资源(如线程的内核栈、线程控制块等)。如果进程/主线程先调用了 exit 系统调用来退出,那么整个进程(包括所属的所有线程)都会退出,而对应父进程会通过 waitpid 回收子进程剩余还没被回收的资源。
进程相关的系统调用#
在引入了线程机制后,进程相关的重要系统调用: fork 、 exec 、 waitpid 虽然在接口上没有变化,但在它要完成的功能上需要有一定的扩展。首先,需要注意到把以前进程中与处理器执行相关的部分拆分到线程中。这样,在通过 fork 创建进程其实也意味着要单独建立一个主线程来使用处理器,并为以后创建新的线程建立相应的线程控制块向量。相对而言, exec 和 waitpid 这两个系统调用要做的改动比较小,还是按照与之前进程的处理方式来进行。
而且,为了实现更加简单,我们要求每个应用对于 线程和进程两个系列的系统调用只能使用其中之一 。比如说,使用了进程系列的 fork 就不能使用线程系列的 thread_create ,这是因为很难定义如何 fork 一个多线程的进程。类似的,可以发现要将进程和线程模型融合起来需要做很多额外的工作。如果做了上述要求的话,我们就可以对进程-线程的融合模型进行简化。如果涉及到父子进程的交互,那么这些进程只会有一个主线程,基本等价于之前的进程模型;如果使用 thread_create 创建了新线程,那么我们只需考虑多个线程在这一个进程内的交互。因此,总体上看,进程相关的这三个系统调用还是保持了已有的进程操作的语义,并没有由于引入了线程,而带来大的变化。
应用程序示例#
我们刚刚介绍了 thread_create/waittid 两个重要系统调用,我们可以借助它们和之前实现的系统调用开发出功能更为灵活的应用程序。下面我们通过描述一个多线程应用程序 threads 的开发过程,来展示这些系统调用的使用方法。
系统调用封装#
同学可以在 user/src/syscall.rs 中看到以 sys_* 开头的系统调用的函数原型,它们后续还会在 user/src/lib.rs 中被封装成方便应用程序使用的形式。如 sys_thread_create 被封装成 thread_create ,而 sys_waittid 被封装成 waittid :
1// user/src/lib.rs
2
3pub fn thread_create(entry: usize, arg: usize) -> isize {
4 sys_thread_create(entry, arg)
5}
6
7pub fn waittid(tid: usize) -> isize {
8 loop {
9 match sys_waittid(tid) {
10 -2 => { yield_(); }
11 exit_code => return exit_code,
12 }
13 }
14}
waittid 等待一个线程标识符的值为 tid 的线程结束。在具体实现方面,我们看到当 sys_waittid 返回值为 -2 ,即要等待的线程存在但它却尚未退出的时候,主线程调用 yield_ 主动交出 CPU 使用权,待下次 CPU 使用权被内核交还给它的时候再次调用 sys_waittid 查看要等待的线程是否退出。这样做是为了减小 CPU 资源的浪费以及尽可能简化内核的实现。
多线程应用程序#
多线程应用程序 – threads 开始执行后,先调用 thread_create 创建了三个线程,加上进程自带的主线程,其实一共有四个线程。每个线程在打印了 1000 个字符后,会执行 exit 退出。进程通过 waittid 等待这三个线程结束后,最终结束进程的执行。下面是多线程应用程序 – threads 的源代码:
1//usr/src/bin/threads.rs
2
3#![no_std]
4#![no_main]
5
6#[macro_use]
7extern crate user_lib;
8extern crate alloc;
9
10use alloc::vec;
11use user_lib::{exit, thread_create, waittid};
12
13pub fn thread_a() -> ! {
14 for _ in 0..1000 { print!("a"); }
15 exit(1)
16}
17
18pub fn thread_b() -> ! {
19 for _ in 0..1000 { print!("b"); }
20 exit(2)
21}
22
23pub fn thread_c() -> ! {
24 for _ in 0..1000 { print!("c"); }
25 exit(3)
26}
27
28#[unsafe(no_mangle)]
29pub fn main() -> i32 {
30 let v = vec![
31 thread_create(linker_symbol_addr!(thread_a), 0),
32 thread_create(linker_symbol_addr!(thread_b), 0),
33 thread_create(linker_symbol_addr!(thread_c), 0),
34 ];
35 for tid in v.iter() {
36 let exit_code = waittid(*tid as usize);
37 println!("thread#{} exited with code {}", tid, exit_code);
38 }
39 println!("main thread exited.");
40 0
41}
另一个名为 threads_arg 的应用和 threads 的功能相同,其不同在于利用 thread_create 可以传参的特性,从而只需编写一个线程函数。
1#![no_std]
2#![no_main]
3
4#[macro_use]
5extern crate user_lib;
6extern crate alloc;
7
8use alloc::vec::Vec;
9use user_lib::{exit, thread_create, waittid};
10
11struct Argument {
12 pub ch: char,
13 pub rc: i32,
14}
15
16fn thread_print(arg: *const Argument) -> ! {
17 let arg = unsafe { &*arg };
18 for _ in 0..1000 {
19 print!("{}", arg.ch);
20 }
21 exit(arg.rc)
22}
23
24#[unsafe(no_mangle)]
25pub fn main() -> i32 {
26 let mut v = Vec::new();
27 let args = [
28 Argument { ch: 'a', rc: 1 },
29 Argument { ch: 'b', rc: 2 },
30 Argument { ch: 'c', rc: 3 },
31 ];
32 for arg in args.iter() {
33 v.push(thread_create(
34 linker_symbol_addr!(thread_print),
35 arg as *const _ as usize,
36 ));
37 }
38 for tid in v.iter() {
39 let exit_code = waittid(*tid as usize);
40 println!("thread#{} exited with code {}", tid, exit_code);
41 }
42 println!("main thread exited.");
43 0
44}
这里传给创建的三个线程的参数放在主线程的栈上,在 thread_create 的时候提供的是对应参数的地址。参数会决定每个线程打印的字符和线程的返回码。
线程管理的核心数据结构#
为了实现线程机制,我们需要将操作系统的 CPU 资源调度单位(也即“任务”)从之前的进程改为线程。这意味着调度器需要考虑更多的因素,比如当一个线程时间片用尽交出 CPU 使用权的时候,切换到同进程下还是不同进程下的线程的上下文切换开销往往有很大不同,可能影响到是否需要切换页表。不过我们为了实现更加简单,仍然采用 Round-Robin 调度算法,将所有线程一视同仁,不考虑它们属于哪个进程。
本章之前,进程管理的三种核心数据结构和一些软/硬件资源如下:
第一个数据结构是任务(进程)控制块 TaskControlBlock ,可以在 os/src/task/task.rs 中找到。它除了记录当前任务的状态之外,还包含如下资源:
进程标识符
pid;内核栈
kernel_stack;进程地址空间
memory_set;进程地址空间中的用户栈和 Trap 上下文(进程控制块中相关字段为
trap_cx_ppn);文件描述符表
fd_table;信号相关的字段。
这些资源的生命周期基本上与进程的生命周期相同。但是在有了线程之后,我们需要将一些与代码执行相关的资源分离出来,让它们与相关线程的生命周期绑定。
第二个数据结构是任务管理器 TaskManager ,可以在 os/src/task/manager.rs 中找到。它实质上是我们内核的调度器,可以决定一个任务时间片用尽或退出之后接下来执行哪个任务。
第三个数据结构是处理器管理结构 Processor ,可以在 os/src/task/processor.rs 中找到。它维护了处理器当前在执行哪个任务,在处理系统调用的时候我们需要依据这里的记录来确定系统调用的发起者是哪个任务。
本章的变更如下:
进程控制块由之前的
TaskControlBlock变成新增的ProcessControlBlock(简称 PCB ),我们在其中保留进程的一些信息以及由进程下所有线程共享的一些资源。 PCB 可以在os/src/task/process.rs中找到。任务控制块TaskControlBlock则变成用来描述线程的线程控制块,包含线程的信息以及线程独占的资源。在资源管理方面,本章之前在
os/src/task/pid.rs可以看到与进程相关的一些 RAII 风格的软/硬件资源,包括进程描述符PidHandle以及内核栈KernelStack,其中内核栈被分配在内核地址空间中且其位置由所属进程的进程描述符决定。本章将pid.rs替换为id.rs,仍然保留PidHandle和KernelStack两种资源,不过KernelStack变为一种线程独占的资源,我们可以在线程控制块TaskControlBlock中找到它。此外,我们还在id.rs中新增了TaskUserRes表示每个线程独占的用户态资源,还有一个各类资源的通用分配器RecycleAllocator。CPU 资源调度单位仍为任务控制块
TaskControlBlock不变。因此,基于任务控制块的任务控制器TaskManager和处理器管理结构Processor也基本不变,只有某些接口有小幅修改。
接下来依次对它们进行介绍。
通用资源分配器及线程相关的软硬件资源#
在 os/src/task/id.rs 中,我们将之前的 PidAllocator 改造为通用的资源分配器 RecycleAllocator 用来分配多种不同的资源。这些资源均为 RAII 风格,可以在被 drop 掉之后自动进行资源回收:
进程描述符
PidHandle;线程独占的线程资源组
TaskUserRes,其中包括线程描述符;线程独占的内核栈
KernelStack。
通用资源分配器 RecycleAllocator 的实现如下:
1// os/src/task/id.rs
2
3pub struct RecycleAllocator {
4 current: usize,
5 recycled: Vec<usize>,
6}
7
8impl RecycleAllocator {
9 pub fn new() -> Self {
10 Self::new_start(0)
11 }
12 pub fn new_start(current: usize) -> Self {
13 RecycleAllocator {
14 current,
15 recycled: Vec::new(),
16 }
17 }
18 pub fn alloc(&mut self) -> usize {
19 if let Some(id) = self.recycled.pop() {
20 id
21 } else {
22 self.current += 1;
23 self.current - 1
24 }
25 }
26 pub fn dealloc(&mut self, id: usize) {
27 assert!(id < self.current);
28 assert!(
29 !self.recycled.iter().any(|i| *i == id),
30 "id {} has been deallocated!",
31 id
32 );
33 self.recycled.push(id);
34 }
35}
分配与回收的算法与之前的 PidAllocator 一样,不过分配的内容从 PID 变为一个非负整数的通用标识符,可以用来表示多种不同资源。这个通用整数标识符可以直接用作进程的 PID 和进程内一个线程的 TID 。下面是 PID 的全局分配器 PID_ALLOCATOR :
// os/src/task/id.rs
lazy_static! {
static ref PID_ALLOCATOR: UPSafeCell<RecycleAllocator> =
unsafe { UPSafeCell::new(RecycleAllocator::new_start(1)) };
}
pub fn pid_alloc() -> PidHandle {
PidHandle(PID_ALLOCATOR.exclusive_access().alloc())
}
impl Drop for PidHandle {
fn drop(&mut self) {
PID_ALLOCATOR.exclusive_access().dealloc(self.0);
}
}
调用 pid_alloc 可以从全局 PID 分配器中分配一个 PID 并构成一个 RAII 风格的 PidHandle 。这里通过 RecycleAllocator::new_start(1) 让 PID 从 1 开始分配,从而保留 PID 0 ;而 RecycleAllocator::new() 仍然表示从 0 开始分配,供 TID、内核栈标识符等其他资源继续使用。当 PidHandle 被回收的时候则会自动调用 drop 方法在全局 PID 分配器将对应的 PID 回收。
对于 TID 而言,每个进程控制块中都有一个给进程内的线程分配资源的通用分配器:
1// os/src/task/process.rs
2
3pub struct ProcessControlBlock {
4 // immutable
5 pub pid: PidHandle,
6 // mutable
7 inner: UPSafeCell<ProcessControlBlockInner>,
8}
9
10pub struct ProcessControlBlockInner {
11 ...
12 pub task_res_allocator: RecycleAllocator,
13 ...
14}
15
16impl ProcessControlBlockInner {
17 pub fn alloc_tid(&mut self) -> usize {
18 self.task_res_allocator.alloc()
19 }
20
21 pub fn dealloc_tid(&mut self, tid: usize) {
22 self.task_res_allocator.dealloc(tid)
23 }
24}
可以看到进程控制块中有一个名为 task_res_allocator 的通用分配器,同时还提供了 alloc_tid 和 dealloc_tid 两个接口来分别在创建线程和销毁线程的时候分配和回收 TID 。除了 TID 之外,每个线程都有自己独立的用户栈和 Trap 上下文,且它们在所属进程的地址空间中的位置可由 TID 计算得到。参考新的进程地址空间如下图所示:
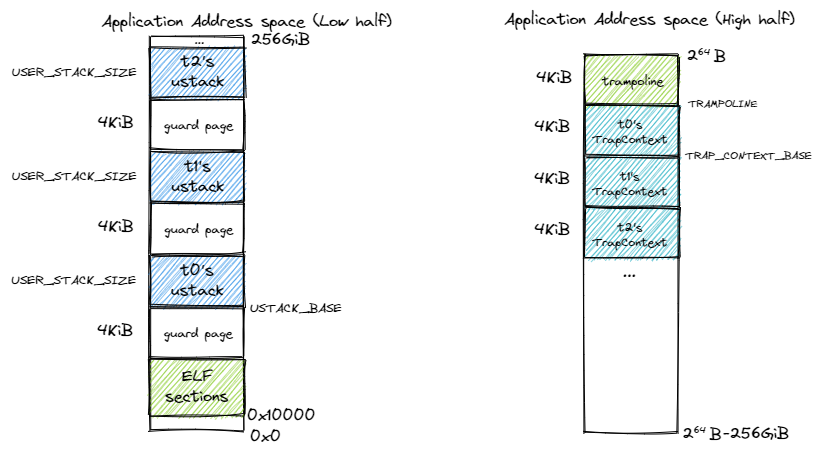
可以看到,在低地址空间中,在放置完应用 ELF 的所有段之后,会预留 4KiB 的空间作为保护页,得到地址 ustack_base ,这部分实现可以参考创建应用地址空间的 MemorySet::from_elf , ustack_base 即为其第二个返回值。接下来从 ustack_base 开始按照 TID 从小到大的顺序向高地址放置线程的用户栈,两两之间预留一个保护页放置栈溢出。在高地址空间中,最高的虚拟页仍然作为跳板页,跳板页中放置的是只读的代码,因此线程之间可以共享。然而,每个线程需要有自己的 Trap 上下文,于是我们在跳板页的下面向低地址按照 TID 从小到大的顺序放置线程的 Trap 上下文。也就是说,只要知道线程的 TID ,我们就可以计算出线程在所属进程地址空间内的用户栈和 Trap 上下文的位置,计算方式由下面的代码给出:
// os/src/config.rs
pub const TRAMPOLINE: usize = usize::MAX - PAGE_SIZE + 1;
pub const TRAP_CONTEXT_BASE: usize = TRAMPOLINE - PAGE_SIZE;
// os/src/task/id.rs
fn trap_cx_bottom_from_tid(tid: usize) -> usize {
TRAP_CONTEXT_BASE - tid * PAGE_SIZE
}
fn ustack_bottom_from_tid(ustack_base: usize, tid: usize) -> usize {
ustack_base + tid * (PAGE_SIZE + USER_STACK_SIZE)
}
线程的 TID 、用户栈和 Trap 上下文均和线程的生命周期相同,因此我们可以将它们打包到一起统一进行分配和回收。这就形成了名为 TaskUserRes 的线程资源集合,它可以在任务(线程)控制块 TaskControlBlock 中找到:
1// os/src/task/id.rs
2
3pub struct TaskUserRes {
4 pub tid: usize,
5 pub ustack_base: usize,
6 pub process: Weak<ProcessControlBlock>,
7}
8
9impl TaskUserRes {
10 pub fn new(
11 process: Arc<ProcessControlBlock>,
12 ustack_base: usize,
13 alloc_user_res: bool,
14 ) -> Self {
15 let tid = process.inner_exclusive_access().alloc_tid();
16 let task_user_res = Self {
17 tid,
18 ustack_base,
19 process: Arc::downgrade(&process),
20 };
21 if alloc_user_res {
22 task_user_res.alloc_user_res();
23 }
24 task_user_res
25 }
26
27 /// 在进程地址空间中实际映射线程的用户栈和 Trap 上下文。
28 pub fn alloc_user_res(&self) {
29 let process = self.process.upgrade().unwrap();
30 let mut process_inner = process.inner_exclusive_access();
31 // alloc user stack
32 let ustack_bottom = ustack_bottom_from_tid(self.ustack_base, self.tid);
33 let ustack_top = ustack_bottom + USER_STACK_SIZE;
34 process_inner.memory_set.insert_framed_area(
35 ustack_bottom.into(),
36 ustack_top.into(),
37 MapPermission::R | MapPermission::W | MapPermission::U,
38 );
39 // alloc trap_cx
40 let trap_cx_bottom = trap_cx_bottom_from_tid(self.tid);
41 let trap_cx_top = trap_cx_bottom + PAGE_SIZE;
42 process_inner.memory_set.insert_framed_area(
43 trap_cx_bottom.into(),
44 trap_cx_top.into(),
45 MapPermission::R | MapPermission::W,
46 );
47 }
48}
TaskUserRes 中记录了进程分配的 TID ,用来计算线程用户栈位置的 ustack_base 。我们还需要所属进程的弱引用,因为 TaskUserRes 中的资源都在进程控制块中,特别是其中的用户栈和 Trap 上下文需要在进程地址空间 MemorySet 中进行映射。因此我们需要进程控制块来完成实际的资源分配和回收。
在使用 TaskUserRes::new 新建的时候进程控制块会分配一个 TID 用于初始化,但并不一定调用 TaskUserRes::alloc_user_res 在进程地址空间中实际对用户栈和 Trap 上下文进行映射,这要取决于 new 参数中的 alloc_user_res 是否为真。举例来说,在 fork 子进程并创建子进程的主线程的时候,就不必再分配一次用户栈和 Trap 上下文,因为子进程拷贝了父进程的地址空间,这些内容已经被映射过了。因此这个时候 alloc_user_res 为假。其他情况下则需要进行映射。
当线程退出之后, TaskUserRes 会随着线程控制块一起被回收,意味着进程分配给它的资源也会被回收:
1// os/src/task/id.rs
2
3impl TaskUserRes {
4 fn dealloc_user_res(&self) {
5 // dealloc tid
6 let process = self.process.upgrade().unwrap();
7 let mut process_inner = process.inner_exclusive_access();
8 // dealloc ustack manually
9 let ustack_bottom_va: VirtAddr = ustack_bottom_from_tid(self.ustack_base, self.tid).into();
10 process_inner
11 .memory_set
12 .remove_area_with_start_vpn(ustack_bottom_va.into());
13 // dealloc trap_cx manually
14 let trap_cx_bottom_va: VirtAddr = trap_cx_bottom_from_tid(self.tid).into();
15 process_inner
16 .memory_set
17 .remove_area_with_start_vpn(trap_cx_bottom_va.into());
18 }
19 pub fn dealloc_tid(&self) {
20 let process = self.process.upgrade().unwrap();
21 let mut process_inner = process.inner_exclusive_access();
22 process_inner.dealloc_tid(self.tid);
23 }
24}
25
26impl Drop for TaskUserRes {
27 fn drop(&mut self) {
28 self.dealloc_tid();
29 self.dealloc_user_res();
30 }
31}
可以看到我们依次调用 dealloc_tid 和 dealloc_user_res 使进程控制块回收掉当前 TID 并在进程地址空间中解映射线程用户栈和 Trap 上下文。
接下来是内核栈 KernelStack 。与之前一样它是从内核高地址空间的跳板页下面开始分配,每两个内核栈中间用一个保护页隔开,因此总体地址空间布局和之前相同。不同的则是它的位置不再与 PID 或者 TID 挂钩,而是与一种新的内核栈标识符有关。我们需要新增一个名为 KSTACK_ALLOCATOR 的通用资源分配器来对内核栈标识符进行分配。
1// os/src/task/id.rs
2
3lazy_static! {
4 static ref KSTACK_ALLOCATOR: UPSafeCell<RecycleAllocator> =
5 unsafe { UPSafeCell::new(RecycleAllocator::new()) };
6}
7
8pub struct KernelStack(pub usize);
9
10/// Return (bottom, top) of a kernel stack in kernel space.
11pub fn kernel_stack_position(kstack_id: usize) -> (usize, usize) {
12 let top = TRAMPOLINE - kstack_id * (KERNEL_STACK_SIZE + PAGE_SIZE);
13 let bottom = top - KERNEL_STACK_SIZE;
14 (bottom, top)
15}
16
17pub fn kstack_alloc() -> KernelStack {
18 let kstack_id = KSTACK_ALLOCATOR.exclusive_access().alloc();
19 let (kstack_bottom, kstack_top) = kernel_stack_position(kstack_id);
20 KERNEL_SPACE.exclusive_access().insert_framed_area(
21 kstack_bottom.into(),
22 kstack_top.into(),
23 MapPermission::R | MapPermission::W,
24 );
25 KernelStack(kstack_id)
26}
27
28impl Drop for KernelStack {
29 fn drop(&mut self) {
30 let (kernel_stack_bottom, _) = kernel_stack_position(self.0);
31 let kernel_stack_bottom_va: VirtAddr = kernel_stack_bottom.into();
32 KERNEL_SPACE
33 .exclusive_access()
34 .remove_area_with_start_vpn(kernel_stack_bottom_va.into());
35 KSTACK_ALLOCATOR.exclusive_access().dealloc(self.0);
36 }
37}
KSTACK_ALLOCATOR 分配/回收的是内核栈标识符 kstack_id ,基于它可以用 kernel_stack_position 函数计算出内核栈在内核地址空间中的位置。进而, kstack_alloc 和 KernelStack::drop 分别在内核地址空间中通过映射/解映射完成内核栈的分配和回收。
于是,我们就将通用资源分配器和三种软硬件资源的分配和回收机制介绍完了,这也是线程机制中最关键的一个部分。
进程和线程控制块#
在引入线程机制之后,线程就代替进程成为了 CPU 资源的调度单位——任务。因此,代码执行有关的一些内容被分离到任务(线程)控制块中,其中包括线程状态、各类上下文和线程独占的一些资源等。线程控制块 TaskControlBlock 是内核对线程进行管理的核心数据结构。在内核看来,它就等价于一个线程。
1// os/src/task/task.rs
2
3pub struct TaskControlBlock {
4 // immutable
5 pub process: Weak<ProcessControlBlock>,
6 pub kstack: KernelStack,
7 // mutable
8 inner: UPSafeCell<TaskControlBlockInner>,
9}
10
11pub struct TaskControlBlockInner {
12 pub res: Option<TaskUserRes>,
13 pub trap_cx_ppn: PhysPageNum,
14 pub task_cx: TaskContext,
15 pub task_status: TaskStatus,
16 pub exit_code: Option<i32>,
17}
线程控制块中的不变量有所属进程的弱引用和自身的内核栈。在可变的 inner 里面则保存了线程资源集合 TaskUserRes 和 Trap 上下文。任务上下文 TaskContext 仍然保留在线程控制块中,这样才能正常进行线程切换。此外,还有线程状态 TaskStatus 和线程退出码 exit_code 。
进程控制块中则保留进程内所有线程共享的资源:
1// os/src/task/process.rs
2
3pub struct ProcessControlBlock {
4 // immutable
5 pub pid: PidHandle,
6 // mutable
7 inner: UPSafeCell<ProcessControlBlockInner>,
8}
9
10pub struct ProcessControlBlockInner {
11 pub is_zombie: bool,
12 pub memory_set: MemorySet,
13 pub parent: Option<Weak<ProcessControlBlock>>,
14 pub children: Vec<Arc<ProcessControlBlock>>,
15 pub exit_code: i32,
16 pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,
17 pub signals: SignalFlags,
18 pub tasks: Vec<Option<Arc<TaskControlBlock>>>,
19 pub task_res_allocator: RecycleAllocator,
20 ... // 其他同步互斥相关资源
21}
其中 pid 为进程标识符,它在进程创建后的整个生命周期中不再变化。可变的 inner 中的变化如下:
第 18 行在进程控制块里面设置一个向量保存进程下所有线程的任务控制块。其布局与文件描述符表比较相似,可以看成一组可以拓展的线程控制块插槽;
第 19 行是进程为进程内的线程分配资源的通用资源分配器
RecycleAllocator。
任务管理器与处理器管理结构#
任务管理器 TaskManager 和处理器管理结构 Processor 分别在 task/manager.rs 和 task/processor.rs 中。它们的接口和功能和之前基本上一致,但是由于任务控制块 TaskControlBlock 和进程控制块 ProcessControlBlock 和之前章节的语义不同,部分接口略有改动。让我们再总体回顾一下它们对外提供的接口:
// os/src/task/manager.rs
/// 全局变量:
/// 1. 全局任务管理器 TASK_MANAGER
/// 2. 全局 PID-进程控制块映射 PID2TCB
/// 将线程加入就绪队列
pub fn add_task(task: Arc<TaskControlBlock>);
/// 将线程移除出就绪队列
pub fn remove_task(task: Arc<TaskControlBlock>);
/// 从就绪队列中选出一个线程分配 CPU 资源
pub fn fetch_task() -> Option<Arc<TaskControlBlock>>;
/// 根据 PID 查询进程控制块
pub fn pid2process(pid: usize) -> Option<Arc<ProcessControlBlock>>;
/// 增加一对 PID-进程控制块映射
pub fn insert_into_pid2process(pid: usize, process: Arc<ProcessControlBlock>);
/// 删除一对 PID-进程控制块映射
pub fn remove_from_pid2process(pid: usize);
// os/src/task/processor.rs
/// 全局变量:当前处理器管理结构 PROCESSOR
/// CPU 的调度主循环
pub fn run_tasks();
/// 取出当前处理器正在执行的线程
pub fn take_current_task() -> Option<Arc<TaskControlBlock>>;
/// 当前线程控制块/进程控制块/进程地址空间satp/线程Trap上下文
pub fn current_task() -> Option<Arc<TaskControlBlock>>;
pub fn current_process() -> Arc<ProcessControlBlock>;
pub fn current_user_token() -> usize;
pub fn current_trap_cx() -> &'static mut TrapContext;
/// 当前线程Trap上下文在进程地址空间中的地址
pub fn current_trap_cx_user_va() -> usize;
/// 当前线程内核栈在内核地址空间中的地址
pub fn current_kstack_top() -> usize;
/// 将当前线程的内核态上下文保存指定位置,并切换到调度主循环
pub fn schedule(switched_task_cx_ptr: *mut TaskContext);
线程管理机制的设计与实现#
在上述线程模型和内核数据结构的基础上,我们还需完成线程管理的基本实现,从而构造出一个完整的“达科塔盗龙”操作系统。这里将从如下几个角度分析如何实现线程管理:
线程生命周期管理
线程执行中的调度和特权级切换
线程生命周期管理#
线程生命周期管理包括线程从创建到退出的整个过程以及过程中的资源分配与回收。
线程创建#
线程创建有两种方式:第一种是在创建进程的时候默认为这个进程创建一个主线程(创建进程又分为若干种方式);第二种是通过 thread_create 系统调用在当前进程内创建一个新的线程。
创建进程的第一种方式是调用 ProcessControlBlock::new 创建初始进程 INITPROC :
1// os/src/task/process.rs
2
3impl ProcessControlBlock {
4 pub fn new(elf_data: &[u8]) -> Arc<Self> {
5 // memory_set with elf program headers/trampoline/trap context/user stack
6 let (memory_set, ustack_base, entry_point) = MemorySet::from_elf(elf_data);
7 // allocate a pid
8 let pid_handle = pid_alloc();
9 // create PCB
10 let process = ...;
11 // create a main thread, we should allocate ustack and trap_cx here
12 let task = Arc::new(TaskControlBlock::new(
13 Arc::clone(&process),
14 ustack_base,
15 true,
16 ));
17 // prepare trap_cx of main thread
18 let task_inner = task.inner_exclusive_access();
19 let trap_cx = task_inner.get_trap_cx();
20 let ustack_top = task_inner.res.as_ref().unwrap().ustack_top();
21 let kstack_top = task.kstack.get_top();
22 drop(task_inner);
23 *trap_cx = TrapContext::app_init_context(
24 entry_point,
25 ustack_top,
26 KERNEL_SPACE.exclusive_access().token(),
27 kstack_top,
28 linker_symbol_addr!(trap_handler),
29 );
30 // add main thread to the process
31 let mut process_inner = process.inner_exclusive_access();
32 process_inner.tasks.push(Some(Arc::clone(&task)));
33 drop(process_inner);
34 insert_into_pid2process(process.getpid(), Arc::clone(&process));
35 // add main thread to scheduler
36 add_task(task);
37 process
38 }
39}
40
41// os/src/task/mod.rs
42
43lazy_static! {
44 pub static ref INITPROC: Arc<ProcessControlBlock> = {
45 let inode = open_file("initproc", OpenFlags::RDONLY).unwrap();
46 let v = inode.read_all();
47 ProcessControlBlock::new(v.as_slice())
48 };
49}
其中的要点在于:
第 10 和 12 行分别创建进程 PCB 和主线程的 TCB ;
第 18~29 行获取所需的信息并填充主线程的 Trap 上下文;
第 32 行将主线程插入到进程的线程列表中。因为此时该列表为空,只需直接
push即可;第 34 行维护 PID-进程控制块映射。
第 36 行将主线程加入到任务管理器使得它可以被调度。
创建进程的第二种方式是 fork 出新进程:
1// os/src/task/process.rs
2
3impl ProcessControlBlock {
4 /// Only support processes with a single thread.
5 pub fn fork(self: &Arc<Self>) -> Arc<Self> {
6 let mut parent = self.inner_exclusive_access();
7 assert_eq!(parent.thread_count(), 1);
8 // clone parent's memory_set completely including trampoline/ustacks/trap_cxs
9 let memory_set = MemorySet::from_existed_user(&parent.memory_set);
10 // alloc a pid
11 let pid = pid_alloc();
12 // copy fd table
13 let mut new_fd_table: Vec<Option<Arc<dyn File + Send + Sync>>> = Vec::new();
14 for fd in parent.fd_table.iter() {
15 ...
16 }
17 // create child process pcb
18 let child = ...;
19 // add child
20 parent.children.push(Arc::clone(&child));
21 // create main thread of child process
22 let task = Arc::new(TaskControlBlock::new(
23 Arc::clone(&child),
24 parent
25 .get_task(0)
26 .inner_exclusive_access()
27 .res
28 .as_ref()
29 .unwrap()
30 .ustack_base(),
31 // here we do not allocate trap_cx or ustack again
32 // but mention that we allocate a new kstack here
33 false,
34 ));
35 // attach task to child process
36 let mut child_inner = child.inner_exclusive_access();
37 child_inner.tasks.push(Some(Arc::clone(&task)));
38 drop(child_inner);
39 // modify kstack_top in trap_cx of this thread
40 let task_inner = task.inner_exclusive_access();
41 let trap_cx = task_inner.get_trap_cx();
42 trap_cx.kernel_sp = task.kstack.get_top();
43 drop(task_inner);
44 insert_into_pid2process(child.getpid(), Arc::clone(&child));
45 // add this thread to scheduler
46 add_task(task);
47 child
48 }
49}
第 18 行创建子进程的 PCB ,并在第 20 行将其加入到当前进程的子进程列表中。
第 22~34 行创建子进程的主线程控制块,注意它继承了父进程的
ustack_base,并且不用重新分配用户栈和 Trap 上下文。在第 37 行将主线程加入到子进程中。子进程的主线程基本上继承父进程的主线程 Trap 上下文,但是其中的内核栈地址需要修改,见第 42 行。
第 44 行将子进程插入到 PID-进程控制块映射中。第 46 行将子进程的主线程加入到任务管理器中。
exec 也是进程模型中的重要操作,它虽然并不会创建新的进程但会替换进程的地址空间。在引入线程机制后,其实现也需要更新,但原理与前面介绍的类似,由于篇幅原因不再赘述,感兴趣的同学可自行了解。
第二种创建线程的方式是通过 thread_create 系统调用。重点是需要了解创建线程控制块,在线程控制块中初始化各个成员变量,建立好进程和线程的关系等。只有建立好这些成员变量,才能给线程建立一个灵活方便的执行环境。这里列出支持线程正确运行所需的重要的执行环境要素:
线程的用户态栈:确保在用户态的线程能正常执行函数调用;
线程的内核态栈:确保线程陷入内核后能正常执行函数调用;
线程共享的跳板页和线程独占的 Trap 上下文:确保线程能正确的进行用户态与内核态间的切换;
线程的任务上下文:线程在内核态的寄存器信息,用于线程切换。
线程创建的具体实现如下:
1// os/src/syscall/thread.rs
2
3pub fn sys_thread_create(entry: usize, arg: usize) -> isize {
4 let task = current_task().unwrap();
5 let process = task.process.upgrade().unwrap();
6 // create a new thread
7 let new_task = Arc::new(TaskControlBlock::new(
8 Arc::clone(&process),
9 task.inner_exclusive_access().res.as_ref().unwrap().ustack_base,
10 true,
11 ));
12 // add new task to scheduler
13 add_task(Arc::clone(&new_task));
14 let new_task_inner = new_task.inner_exclusive_access();
15 let new_task_res = new_task_inner.res.as_ref().unwrap();
16 let new_task_tid = new_task_res.tid;
17 let mut process_inner = process.inner_exclusive_access();
18 // add new thread to current process
19 let tasks = &mut process_inner.tasks;
20 while tasks.len() < new_task_tid + 1 {
21 tasks.push(None);
22 }
23 tasks[new_task_tid] = Some(Arc::clone(&new_task));
24 let new_task_trap_cx = new_task_inner.get_trap_cx();
25 *new_task_trap_cx = TrapContext::app_init_context(
26 entry,
27 new_task_res.ustack_top(),
28 kernel_token(),
29 new_task.kstack.get_top(),
30 linker_symbol_addr!(trap_handler),
31 );
32 (*new_task_trap_cx).x[10] = arg;
33 new_task_tid as isize
34}
上述代码主要完成了如下事务:
第 4~5 行,找到当前正在执行的线程
task和此线程所属的进程process。第 7~11 行,调用
TaskControlBlock::new方法,创建一个新的线程new_task,在创建过程中,建立与进程process的所属关系,分配了线程资源组TaskUserRes和其他资源。第 13 行,把线程挂到调度队列中。
第 19~22 行,把线程接入到所属进程的线程列表
tasks中。第 25~32 行,初始化位于该线程在用户态地址空间中的 Trap 上下文:设置线程的函数入口点和用户栈,使得第一次进入用户态时能从指定位置开始正确执行;设置好内核栈和陷入函数指针
trap_handler,保证在 Trap 的时候用户态的线程能正确进入内核态。
线程退出#
线程可以通过 sys_exit 系统调用退出:
// os/src/syscall/process.rs
pub fn sys_exit(exit_code: i32) -> ! {
exit_current_and_run_next(exit_code);
panic!("Unreachable in sys_exit!");
}
无论当前线程是否是主线程,都会调用 exit_current_and_run_next 。如果是主线程,将会导致整个进程退出,从而其他线程也会退出;否则的话,只有当前线程会退出。下面是具体实现:
1// os/src/task/mod.rs
2
3pub fn exit_current_and_run_next(exit_code: i32) {
4 let task = take_current_task().unwrap();
5 let mut task_inner = task.inner_exclusive_access();
6 let process = task.process.upgrade().unwrap();
7 let tid = task_inner.res.as_ref().unwrap().tid;
8 // record exit code
9 task_inner.exit_code = Some(exit_code);
10 task_inner.res = None;
11 // here we do not remove the thread since we are still using the kstack
12 // it will be deallocated when sys_waittid is called
13 drop(task_inner);
14 drop(task);
15 // however, if this is the main thread of current process
16 // the process should terminate at once
17 if tid == 0 {
18 let pid = process.getpid();
19 ...
20 remove_from_pid2process(pid);
21 let mut process_inner = process.inner_exclusive_access();
22 // mark this process as a zombie process
23 process_inner.is_zombie = true;
24 // record exit code of main process
25 process_inner.exit_code = exit_code;
26
27 {
28 // move all child processes under init process
29 let mut initproc_inner = INITPROC.inner_exclusive_access();
30 for child in process_inner.children.iter() {
31 child.inner_exclusive_access().parent = Some(Arc::downgrade(&INITPROC));
32 initproc_inner.children.push(child.clone());
33 }
34 }
35
36 // deallocate user res (including tid/trap_cx/ustack) of all threads
37 // it has to be done before we dealloc the whole memory_set
38 // otherwise they will be deallocated twice
39 let mut recycle_res = Vec::<TaskUserRes>::new();
40 for task in process_inner.tasks.iter().filter(|t| t.is_some()) {
41 let task = task.as_ref().unwrap();
42 // if other tasks are Ready in TaskManager or waiting for a timer to be
43 // expired, we should remove them.
44 //
45 // Mention that we do not need to consider Mutex/Semaphore since they
46 // are limited in a single process. Therefore, the blocked tasks are
47 // removed when the PCB is deallocated.
48 remove_inactive_task(Arc::clone(&task));
49 let mut task_inner = task.inner_exclusive_access();
50 if let Some(res) = task_inner.res.take() {
51 recycle_res.push(res);
52 }
53 }
54 // dealloc_tid and dealloc_user_res require access to PCB inner, so we
55 // need to collect those user res first, then release process_inner
56 // for now to avoid deadlock/double borrow problem.
57 drop(process_inner);
58 recycle_res.clear();
59
60 let mut process_inner = process.inner_exclusive_access();
61 process_inner.children.clear();
62 // deallocate other data in user space i.e. program code/data section
63 process_inner.memory_set.recycle_data_pages();
64 // drop file descriptors
65 process_inner.fd_table.clear();
66 // Remove all tasks except for the main thread itself.
67 while process_inner.tasks.len() > 1 {
68 process_inner.tasks.pop();
69 }
70 }
71 drop(process);
72 // we do not have to save task context
73 let mut _unused = TaskContext::zero_init();
74 schedule(&mut _unused as *mut _);
75}
第 4 行将当前线程从处理器管理结构
PROCESSOR中移除,随后在第 9 行在线程控制块中记录退出码并在第 10 行回收当前线程的线程资源组TaskUserRes。第 17~68 行针对当前线程是所属进程主线程的情况退出整个进程和其他的所有线程(此时主线程已经在上一步中被移除)。其判断条件为第 17 行的当前线程 TID 是否为 0 ,这是主线程的特征。具体来说:
第 20~25 行更新 PID-进程控制块映射,将进程标记为僵尸进程然后记录进程退出码, 进程退出码即为其主线程退出码 。
第 29~33 行将子进程挂到初始进程 INITPROC 下面。
第 36~58 行回收所有线程的
TaskUserRes,为了保证进程控制块的独占访问,我们需要先将所有的线程的TaskUserRes收集到向量recycle_res中。在第 57 行独占访问结束后,第 58 行通过清空recycle_res自动回收所有的TaskUserRes。第 60~65 行依次清空子进程列表、回收进程地址空间中用于存放数据的物理页帧、清空文件描述符表。注意我们在回收物理页帧之前必须将
TaskUserRes清空,不然相关物理页帧会被回收两次。目前这种回收顺序并不是最好的实现,同学可以想想看有没有更合适的实现。第 66~69 行移除除了主线程之外的所有线程。目前线程控制块中,只有内核栈资源还未回收,但我们此时无法回收主线程的内核栈,因为当前的流程还是在这个内核栈上跑的,所以这里要绕过主线程。等到整个进程被父进程通过
waitpid回收的时候,主线程的内核栈会被一起回收。
这里特别需要注意的是在第 48 行,主线程退出的时候可能有一些线程处于就绪状态等在任务管理器 TASK_MANAGER 的队列中,我们需要及时调用 remove_inactive_task 函数将它们从队列中移除,不然将导致它们的引用计数不能成功归零并回收资源,最终导致内存溢出。相关测例如 early_exit.rs ,请同学思考我们的内核能否正确处理这种情况。
等待线程结束#
如果调用 sys_exit 退出的不是进程的主线程,那么 sys_exit 之后该线程的资源并没有被完全回收,这一点和进程比较像。我们还需要另一个线程调用 waittid 系统调用才能收集该线程的退出码并彻底回收该线程的资源:
1// os/src/syscall/thread.rs
2
3/// thread does not exist, return -1
4/// thread has not exited yet, return -2
5/// otherwise, return thread's exit code
6pub fn sys_waittid(tid: usize) -> i32 {
7 let task = current_task().unwrap();
8 let process = task.process.upgrade().unwrap();
9 let task_inner = task.inner_exclusive_access();
10 let mut process_inner = process.inner_exclusive_access();
11 // a thread cannot wait for itself
12 if task_inner.res.as_ref().unwrap().tid == tid {
13 return -1;
14 }
15 let mut exit_code: Option<i32> = None;
16 let waited_task = process_inner.tasks[tid].as_ref();
17 if let Some(waited_task) = waited_task {
18 if let Some(waited_exit_code) = waited_task.inner_exclusive_access().exit_code {
19 exit_code = Some(waited_exit_code);
20 }
21 } else {
22 // waited thread does not exist
23 return -1;
24 }
25 if let Some(exit_code) = exit_code {
26 // dealloc the exited thread
27 process_inner.tasks[tid] = None;
28 exit_code
29 } else {
30 // waited thread has not exited
31 -2
32 }
33}
第 12~14 行,如果是线程等自己,返回错误.
第 17~24 行,如果找到
tid对应的退出线程,则收集该退出线程的退出码exit_tid,否则返回错误(退出线程不存在)。第 25~32 行,如果退出码存在,则在第 27 行从进程的线程向量中将被等待的线程删除。这意味着该函数返回之后,被等待线程的 TCB 的引用计数将被归零从而相关资源被完全回收。否则,返回错误(线程还没退出)。
线程执行中的特权级切换和调度切换#
在特权级切换方面,注意到在创建每个线程的时候,我们都正确设置了其用户态线程函数入口地址、用户栈、内核栈以及一些相关信息,于是第一次返回用户态之后能够按照我们的期望正确执行。后面在用户态和内核态间切换沿用的是前面的 Trap 上下文保存与恢复机制,本章并没有修改。有需要的同学可以回顾第二章和第四章的有关内容。
在线程切换方面,我们将任务上下文移至线程控制块中并依然沿用第三章的任务切换机制。同时,线程调度算法我们仍然采取第三章中时间片轮转的 Round-Robin 算法。
因此,这里我们就不再重复介绍这两种机制了。