练习#
课后练习#
编程题#
* 实现一个linux应用程序A,显示当前目录下的文件名。(用C或Rust编程)
*** 实现一个linux应用程序B,能打印出调用栈链信息。(用C或Rust编程)
** 实现一个基于rcore/ucore tutorial的应用程序C,用sleep系统调用睡眠5秒(in rcore/ucore tutorial v3: Branch ch1)
注: 尝试用GDB等调试工具和输出字符串的等方式来调试上述程序,能设置断点,单步执行和显示变量,理解汇编代码和源程序之间的对应关系。
问答题#
* 应用程序在执行过程中,会占用哪些计算机资源?
* 请用相关工具软件分析并给出应用程序A的代码段/数据段/堆/栈的地址空间范围。
* 请简要说明应用程序与操作系统的异同之处。
** 请基于QEMU模拟RISC—V的执行过程和QEMU源代码,说明RISC-V硬件加电后的几条指令在哪里?完成了哪些功能?
* RISC-V中的SBI的含义和功能是啥?
** 为了让应用程序能在计算机上执行,操作系统与编译器之间需要达成哪些协议?
** 请简要说明从QEMU模拟的RISC-V计算机加电开始运行到执行应用程序的第一条指令这个阶段的执行过程。
** 为何应用程序员编写应用时不需要建立栈空间和指定地址空间?
*** 现代的很多编译器生成的代码,默认情况下不再严格保存/恢复栈帧指针。在这个情况下,我们只要编译器提供足够的信息,也可以完成对调用栈的恢复。
我们可以手动阅读汇编代码和栈上的数据,体验一下这个过程。例如,对如下两个互相递归调用的函数:
void flip(unsigned n) { if ((n & 1) == 0) { flip(n >> 1); } else if ((n & 1) == 1) { flap(n >> 1); } } void flap(unsigned n) { if ((n & 1) == 0) { flip(n >> 1); } else if ((n & 1) == 1) { flap(n >> 1); } }
在某种编译环境下,编译器产生的代码不包括保存和恢复栈帧指针
fp的代码。以下是 GDB 输出的本次运行的时候,这两个函数所在的地址和对应地址指令的反汇编,为了方便阅读节选了重要的控制流和栈操作(省略部分不含栈操作):(gdb) disassemble flap Dump of assembler code for function flap: 0x0000000000010730 <+0>: addi sp,sp,-16 // 唯一入口 0x0000000000010732 <+2>: sd ra,8(sp) ... 0x0000000000010742 <+18>: ld ra,8(sp) 0x0000000000010744 <+20>: addi sp,sp,16 0x0000000000010746 <+22>: ret // 唯一出口 ... 0x0000000000010750 <+32>: j 0x10742 <flap+18> (gdb) disassemble flip Dump of assembler code for function flip: 0x0000000000010752 <+0>: addi sp,sp,-16 // 唯一入口 0x0000000000010754 <+2>: sd ra,8(sp) ... 0x0000000000010764 <+18>: ld ra,8(sp) 0x0000000000010766 <+20>: addi sp,sp,16 0x0000000000010768 <+22>: ret // 唯一出口 ... 0x0000000000010772 <+32>: j 0x10764 <flip+18> End of assembler dump.
启动这个程序,在运行的时候的某个状态将其打断。此时的
pc,sp,ra寄存器的值如下所示。此外,下面还给出了栈顶的部分内容。(为阅读方便,栈上的一些未初始化的垃圾数据用???代替。)(gdb) p $pc $1 = (void (*)()) 0x10752 <flip> (gdb) p $sp $2 = (void *) 0x40007f1310 (gdb) p $ra $3 = (void (*)()) 0x10742 <flap+18> (gdb) x/6a $sp 0x40007f1310: ??? 0x10750 <flap+32> 0x40007f1320: ??? 0x10772 <flip+32> 0x40007f1330: ??? 0x10764 <flip+18>
根据给出这些信息,调试器可以如何复原出最顶层的几个调用栈信息?假设调试器可以理解编译器生成的汇编代码 1 。
实验练习#
实验练习包括实践作业和问答作业两部分。
实践作业#
彩色化 LOG#
lab1 的工作使得我们从硬件世界跳入了软件世界,当看到自己的小 os 可以在裸机硬件上输出 hello world 是不是很高兴呢?但是为了后续的一步开发,更好的调试环境也是必不可少的,第一章的练习要求大家实现更加炫酷的彩色log。
详细的原理不多说,感兴趣的同学可以参考 ANSI转义序列 ,现在执行如下这条命令试试
$ echo -e "\x1b[31mhello world\x1b[0m"
如果你明白了我们是如何利用串口实现输出,那么要实现彩色输出就十分容易了,只需要用需要输出的字符串替换上一条命令中的 hello world,用期望颜色替换 31(代表红色) 即可。
警告
以下内容仅为推荐实现,不是练习要求,有时间和兴趣的同学可以尝试。
我们推荐实现如下几个等级的输出,输出优先级依次降低:
名称 |
颜色 |
用途 |
|---|---|---|
ERROR |
红色(31) |
表示发生严重错误,很可能或者已经导致程序崩溃 |
WARN |
黄色(93) |
表示发生不常见情况,但是并不一定导致系统错误 |
INFO |
蓝色(34) |
比较中庸的选项,输出比较重要的信息,比较常用 |
DEBUG |
绿色(32) |
输出信息较多,在 debug 时使用 |
TRACE |
灰色(90) |
最详细的输出,跟踪了每一步关键路径的执行 |
我们可以输出比设定输出等级以及更高输出等级的信息,如设置 LOG = INFO,则输出 ERROR、WARN、INFO 等级的信息。简单 demo 如下,输出等级为 INFO:
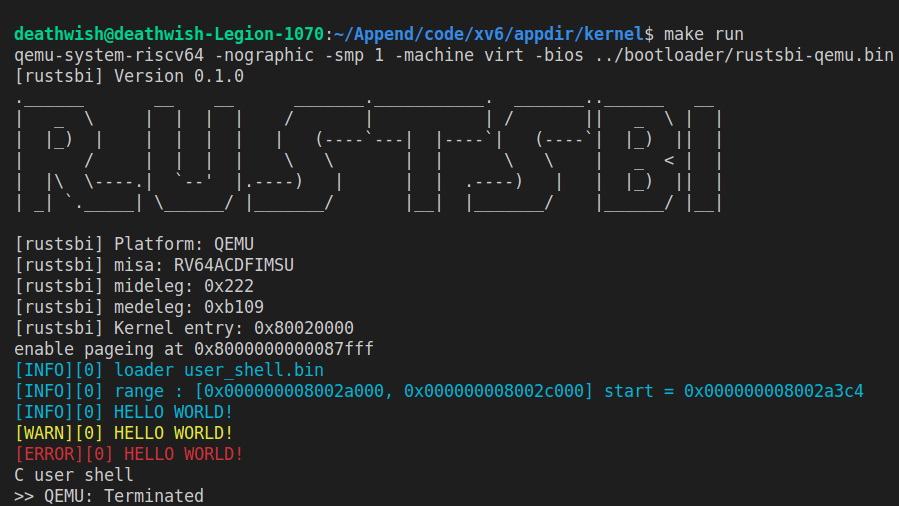
为了方便使用彩色输出,我们要求同学们实现彩色输出的宏或者函数,用以代替 print 完成输出内核信息的功能,它们有着和 prinf 十分相似的使用格式,要求支持可变参数解析,形如:
// 这段代码输出了 os 内存空间布局,这到这些信息对于编写 os 十分重要
info!(".text [{:#x}, {:#x})", linker_symbol_addr!(s_text), linker_symbol_addr!(e_text));
debug!(".rodata [{:#x}, {:#x})", linker_symbol_addr!(s_rodata), linker_symbol_addr!(e_rodata));
error!(".data [{:#x}, {:#x})", linker_symbol_addr!(s_data), linker_symbol_addr!(e_data));
info("load range : [%d, %d] start = %d\n", s, e, start);
在以后,我们还可以在 log 信息中增加线程、CPU等信息(只是一个推荐,不做要求),这些信息将极大的方便你的代码调试。
实验要求#
实现分支:ch1
完成实验指导书中的内容并在裸机上实现
hello world输出。实现彩色输出宏(只要求可以彩色输出,不要求 log 等级控制,不要求多种颜色)
隐形要求
可以关闭内核所有输出。从 lab2 开始要求关闭内核所有输出(如果实现了 log 等级控制,那么这一点自然就实现了)。
利用彩色输出宏输出 os 内存空间布局
输出
.text、.data、.rodata、.bss各段位置,输出等级为INFO。
challenge: 支持多核,实现多个核的 boot。
实验检查#
实验目录要求(Rust)
├── os(内核实现)
│ ├── Cargo.toml(配置文件)
│ ├── Makefile (要求 make run LOG=xxx 可以正确执行,可以不实现对 LOG 这一属性的支持,设置默认输出等级为 INFO)
│ └── src(所有内核的源代码放在 os/src 目录下)
│ ├── main.rs(内核主函数)
│ └── ...
├── reports
│ ├── lab1.md/pdf
│ └── ...
├── README.md(其他必要的说明)
├── ...
报告命名 labx.md/pdf,统一放在 reports 目录下。每个实验新增一个报告,为了方便修改,检查报告是以最新分支的所有报告为准。
检查
$ cd os
$ git checkout ch1
$ make run LOG=INFO
可以正确执行(可以不支持LOG参数,只有要彩色输出就好),可以看到正确的内存布局输出,根据实现不同数值可能有差异,但应该位于 linker.ld 中指示 BASE_ADDRESS 后一段内存,输出之后关机。
tips#
对于 C,可以实现不同的函数(注意不推荐多层可变参数解析,有时会出现不稳定情况),也可以参考 linux printk 使用宏实现代码重用。
两种语言都可以使用
extern关键字获得在其他文件中定义的符号。
问答作业#
请学习 gdb 调试工具的使用(这对后续调试很重要),并通过 gdb 简单跟踪从机器加电到跳转到 0x80200000 的简单过程。只需要描述重要的跳转即可,只需要描述在 qemu 上的情况。
tips:
事实上进入 rustsbi 之后就不需要使用 gdb 调试了。可以直接阅读代码。rustsbi起始代码 。
可以使用示例代码 Makefile 中的
make debug指令。
- 一些可能用到的 gdb 指令:
x/10i 0x80000000: 显示 0x80000000 处的10条汇编指令。
x/10i $pc: 显示即将执行的10条汇编指令。
x/10xw 0x80000000: 显示 0x80000000 处的10条数据,格式为16进制32bit。
info register: 显示当前所有寄存器信息。
info r t0: 显示 t0 寄存器的值。
break funcname: 在目标函数第一条指令处设置断点。
break *0x80200000: 在 0x80200000 处设置断点。
continue: 执行直到碰到断点。
si: 单步执行一条汇编指令。