简明 zCore 教程
自己动手山寨操作系统:自顶向下方法
zCore 是用 Rust 语言重写的 Zircon 微内核,它是 Google 正在开发的 Fuchsia OS 中的底层内核。
本教程基于 zCore 的真实开发历史,还原其开发过程。带领读者一步一步用 Rust 实现自己的 Zircon 内核,最终能够运行原生的 shell 程序。 在此过程中我们将体会 Zircon 微内核的设计理念,感受如何用 Rust 语言以一种现代的方式编写系统软件,在项目中实现理论与实践的融合。
与传统操作系统开发不同的是,zCore 使用一种自顶向下的方法:首先基于宿主系统已有的功能,在用户态实现一个能够工作的 libOS,然后再逐步替换底层实现, "移植"回裸机环境中运行。因此我们更关注系统的整体设计,从高层视角看待 OS 如何为用户提供服务,而不纠结于底层硬件细节。
鉴于此,本教程假设读者了解操作系统基本概念和原理,具有常用的 Linux 系统使用经验,并且会使用 Rust 语言编写简单程序。 如果读者不熟悉操作系统和 Rust 语言,希望以自底向上方法从零构建操作系统,rCore Tutorial 可能是更好的选择。
如果你准备好了,让我们开始吧!
zCore 整体结构和设计模式
首先,从 Rust语言操作系统的设计与实现,王润基本科毕设论文,2019 和 zCore操作系统内核的设计与实现,潘庆霖本科毕设论文,2020 可以了解到从 rCore 的设计到 zCore 的设计过程的全貌。
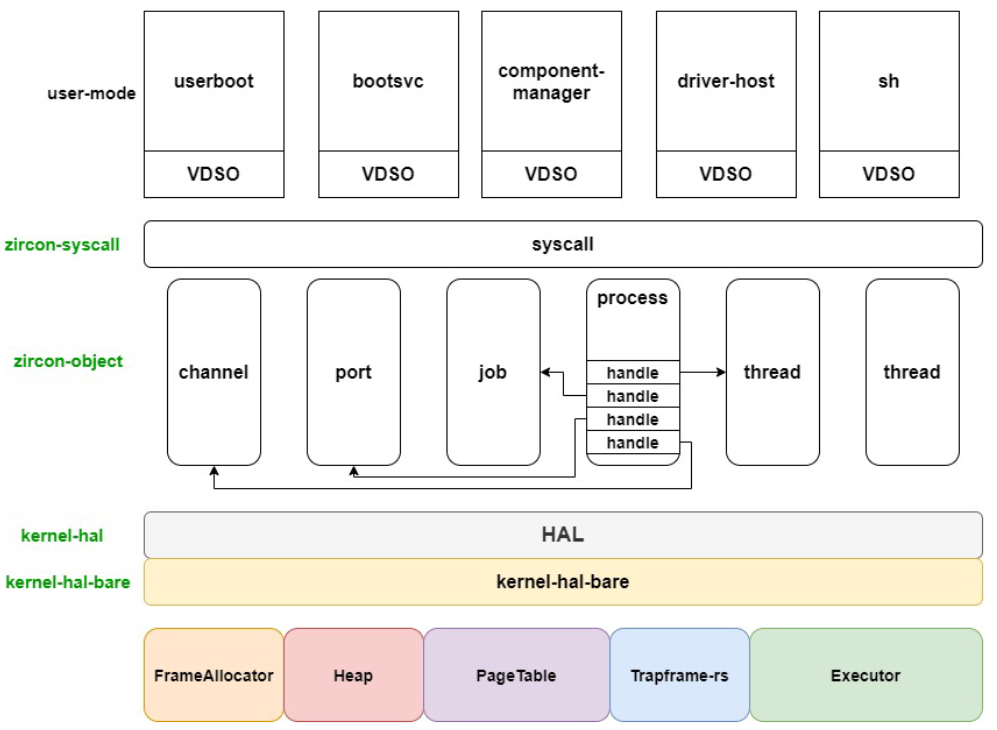
zCore 的整体结构
zCore 的整体结构/项目设计图如下:

zCore的设计主要有两个出发点:
- 内核对象的封装:将内核对象代码封装为一个库,保证可重用
- 硬件接口的设计:使硬件与内核对象的设计相对独立,只向上提供统一、抽象的API接口
项目设计从上到下,上层更远离硬件,下层更接近硬件。
zCore 设计的顶层是上层操作系统,比如 zCore、rCore、Zircon LibOS 和 Linux LibOS。在项目架构中,各版本的操作系统有部分公用代码。与 zCore 微内核设计实现相关的部分则主要是图中左侧蓝色线部分。
第二层,是 ELF 程序加载层(ELF Program Loader),包括 zircon-loader 和 linux-loader,其中封装了初始化内核对象、部分硬件相关的初始化、设定系统调用接口、运行首个用户态程序等逻辑,并形成一个库函数。zCore 在顶层通过调用 zircon-loader 库中的初始化逻辑,进入第一个用户态程序执行。
第三层,是系统调用实现层(Syscall Implementation),包括 zircon-syscall 和 linux-syscall,这一层将所有的系统调用处理例程封装为一个系统调用库,供上方操作系统使用。
第四层,利用硬件抽象层提供的虚拟硬件 API 进行内核对象(Kernel Objects)的实现,并且基于实现的各类内核对象,实现第三层各个系统调用接口所需要的具体处理例程。
第五层,是硬件抽象层(HAL,Hardware Abstraction Layer),这里对应的是 kernel-hal 模块。kernel-hal 将向上提供所有操作硬件需要的接口,从而使得硬件环境对上层操作系统透明化。
第六层,是对直接操作硬件的代码进行一层封装,对应模块为 kernel-hal-bare 和 kernel-hal-unix。kernel-hal 系列库仅仅负责接口定义,即将底层硬件/宿主操作系统的操作翻译为上层操作系统可以使用的形式。在这里,kernel-hal-bare 负责翻译裸机的硬件功能,而 kernel-hal-unix 则负责翻译类 Unix 系统的系统调用。
最底层是底层运行环境,包括 Bare Metal(裸机),Linux / macOS 操作系统。Bare Metal可以认为是硬件架构上的寄存器等硬件接口。
zCore 内核组件
zCore 内核运行时组件层次概况如下:
在zCore启动过程中,会初始化物理页帧分配器、堆分配器、线程调度器等各个组成部分。并委托 zircon-loader 进行内核对象的初始化创建过程,然后进入用户态的启动过程开始执行。每当用户态触发系统调用进入内核态,系统调用处理例程将会通过已实现的内核对象的功能来对服务请求进行处理;而对应的内核对象的内部实现所需要的各种底层操作,则是通过 HAL 层接口由各个内核组件负责提供。
其中,VDSO(Virtual dynamic shared object)是一个映射到用户空间的 so 文件,可以在不陷入内核的情况下执行一些简单的系统调用。在设计中,所有中断都需要经过 VDSO 拦截进行处理,因此重写 VDSO 便可以实现自定义的对下层系统调用(syscall)的支持。Executor 是 zCore 中基于 Rust 的 async 机制的协程调度器。
在HAL接口层的设计上,还借助了 Rust 的能够指定函数链接过程的特性。即,在 kernel-hal 中规定了所有可供 zircon-object 库及 zircon-syscall 库调用的虚拟硬件接口,以函数 API 的形式给出,但是内部均为未实现状态,并设置函数为弱引用链接状态。在 kernel-hal-bare 中才给出裸机环境下的硬件接口具体实现,编译 zCore 项目时、链接的过程中将会替换/覆盖 kernel-hal 中未实现的同名接口,从而达到能够在编译时灵活选择 HAL 层的效果。
Fuchsia OS 和 Zircon 微内核
内核对象
Zircon 是一个基于内核对象的系统。系统的功能被划分到若干组内核对象中。
作为一切的开始,本章首先构造了一个内核对象框架,作为后面实现的基础。
然后我们实现第一个内核对象 —— Process,它是所有对象的容器,也是将来我们操作对象的入口点。
最后会实现一个稍微复杂但是极其重要的对象 Channel,它是进程间通信(IPC)的基础设施,也是传送对象的唯一管道。
初识内核对象
内核对象简介
在动手编写我们的代码之前,需要首先进行调研和学习,对目标对象有一个全面系统的了解。 而了解一个项目设计的最好方式就是阅读官方提供的手册和文档。
让我们先来阅读一下 Fuchsia 官方文档:内核对象。这个链接是社区翻译的中文版,已经有些年头了。如果读者能够科学上网,推荐直接阅读官方英文版。
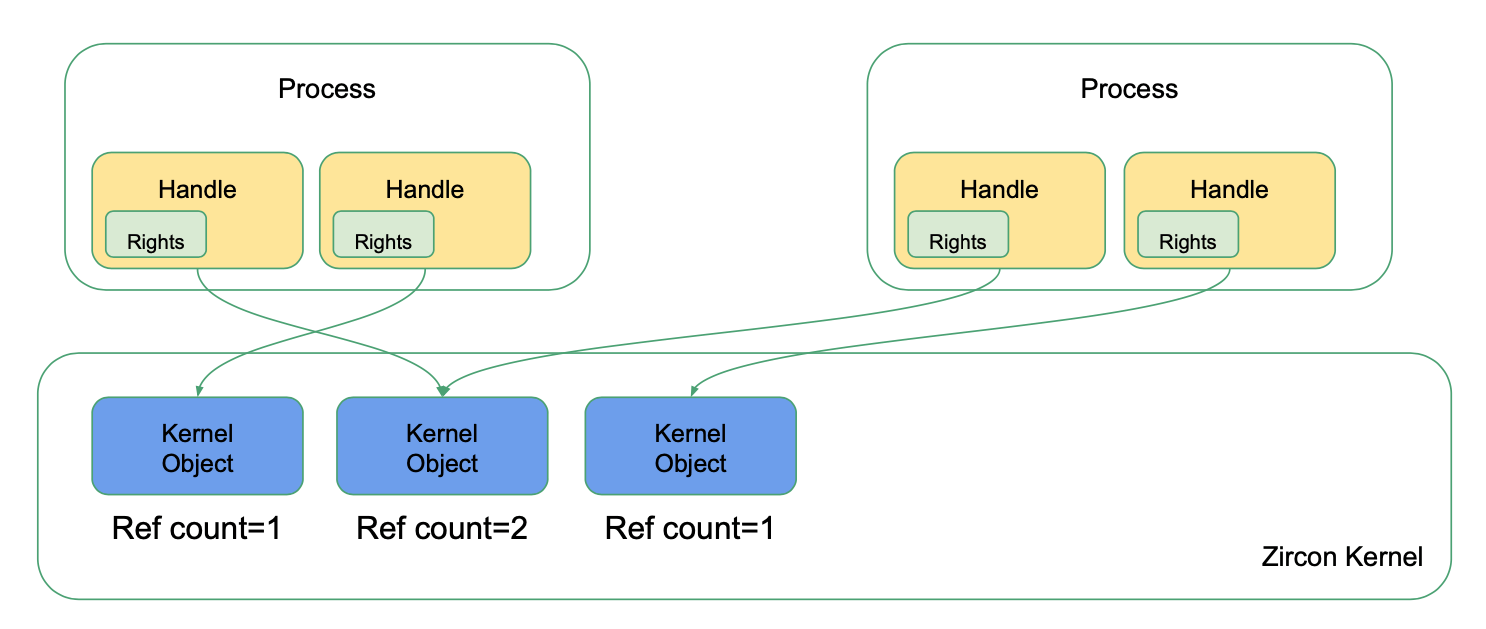
通过阅读文档,我们了解到与内核对象相关的三个重要概念:对象(Object),句柄(Handle),权限(Rights)。它们在 Zircon 内核中的角色和关系如下图所示:
这三个重要概念的定义如下:
- 对象(Object): 具备属性和行为的客体。客体之间可有各种联系。从简单的整数到复杂的操作系统进程等都可看做对象,它不仅仅表示具体的事物,还能表示抽象的规则、计划或事件。
- 句柄(Handle):标识对象的符号,也可看成是一种指向对象的变量(也可称为标识符、引用、ID等)。
- 权限(Rights):是指对象的访问者被允许在对象上执行的操作,即对象的访问权限。当对象访问者打开对象的句柄,该句柄具有对其对象的访问权限的某种组合。
对于Zircon与对象、句柄、权限的关系,可简单地表述为:
- Zircon是一个基于对象的内核,内核资源被抽象封装在不同的 对象 中。
- 用户程序通过 句柄 与内核交互。句柄是对某一对象的引用,并且附加了特定的 权限。
- 对象通过 引用计数 管理生命周期。对于大多数对象,当指向它的最后一个句柄关闭时,对象随之销毁,或进入无法挽回的最终状态。
此外在内核对象的文档中,还列举了一些常用对象。点击链接进去就能查看到这个对象的具体描述,在页面最下方还列举了与这个对象相关的全部系统调用。 进一步查看系统调用的 API 定义,以及它的行为描述,我们就能更深入地了解用户程序操作内核对象的一些细节:
-
创建:每一种内核对象都存在一个系统调用来创建它,例如
zx_channel_create。 创建对象时一般需要传入一个参数选项options,若创建成功则内核会将一个新句柄写入用户指定的内存中。 -
使用:获得对象句柄后可以通过若干系统调用对它进行操作,例如
zx_channel_write。 这类系统调用一般需要传入句柄handle作为第一个参数,内核首先对其进行检查,如果句柄非法或者对象类型与系统调用不匹配就会报错。 接下来内核会检查句柄的权限是否满足操作的要求,例如write操作一般要求句柄具有WRITE权限,如果权限不满足就会继续报错。 -
关闭:当用户程序不再使用对象时,会调用
zx_handle_close关闭句柄。当用户进程退出时,仍处于打开状态的句柄也都会自动关闭。
我们还发现,有一类 Object 系统调用是对所有内核对象都适用的。 这表明所有内核对象都有一些公共属性,例如 ID、名称等等。每一种内核对象也会有自己特有的属性。
其中一些 Object 系统调用和信号相关。Zircon 每个内核对象都附带有 32 个 信号(Signals),它们代表了不同类型的事件。 与传统 Unix 系统的信号不同,它不能异步地打断用户程序运行,而只能由用户程序主动地阻塞等待在某个对象的某些信号上面。 信号是 Zircon 内核中很重要的机制,不过这部分在前期不会涉及,我们留到第五章再具体实现。
以上我们了解了 Zircon 内核对象的相关概念和使用方式。接下来在这一节中,我们将用 Rust 实现内核对象的基本框架,以方便后续快速实现各种具体类型的内核对象。 从传统面向对象语言的视角看,我们只是在实现一个基类。但由于 Rust 语言模型的限制,这件事情需要用到一些特殊的技巧。
建立项目
首先我们需要安装 Rust 工具链。在 Linux 或 macOS 系统下,只需要用一个命令下载安装 rustup 即可:
$ curl https://sh.rustup.rs -sSf | sh
具体安装方法可以参考官方文档。
接下来我们用 cargo 创建一个 Rust 库项目:
$ cargo new --lib zcore
$ cd zcore
我们将在这个 crate 中实现所有的内核对象,以库(lib)而不是可执行文件(bin)的形式组织代码,后面我们会依赖单元测试保证代码的正确性。
由于我们会用到一些不稳定(unstable)的语言特性,需要使用 nightly 版本的工具链。在项目根目录下创建一个 rust-toolchain 文件,指明使用的工具链版本:
{{#include ../../code/ch01-01/rust-toolchain}}
这个程序库目前是在你的 Linux 或 macOS 上运行,但有朝一日它会成为一个真正的 OS 在裸机上运行。
为此我们需要移除对标准库的依赖,使其成为一个不依赖当前 OS 功能的库。在 lib.rs 的第一行添加声明:
// src/lib.rs
#![no_std]
extern crate alloc;
现在我们可以尝试运行一下自带的单元测试,编译器可能会自动下载并安装工具链:
$ cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.52s
Running target/debug/deps/zcore-dc6d43637bc5df7a
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
实现 KernelObject 接口
所有的内核对象有一系列共同的属性和方法,我们称对象的方法为对象的公共接口(Interface)。 同一种方法在不同类型的对象中可能会有不同的行为,在面向对象语言中我们称其为多态(Polymorphism)。
Rust 是一门部分面向对象的语言,我们通常用它的 trait 实现接口和多态。
首先创建一个 KernelObject trait 作为内核对象的公共接口:
use alloc::string::String;
// src/object/mod.rs
/// 内核对象公共接口
pub trait KernelObject: Send + Sync {
/// 获取对象 ID
fn id(&self) -> KoID;
/// 获取对象类型名
fn type_name(&self) -> &str;
/// 获取对象名称
fn name(&self) -> String;
/// 设置对象名称
fn set_name(&self, name: &str);
}
/// 对象 ID 类型
pub type KoID = u64;
这里的 Send + Sync 是一个约束所有 KernelObject 都要满足的前提条件,即它必须是一个并发对象。
所谓并发对象指的是可以安全地被多线程共享访问。事实上我们的内核本身就是一个共享地址空间的多线程程序,在裸机上每个 CPU 核都可以被视为一个并发执行的线程。
由于内核对象可能被多个线程同时访问,因此它必须是并发对象。
实现一个空对象
接下来我们实现一个最简单的空对象 DummyObject,并为它实现 KernelObject 接口:
// src/object/object.rs
use spin::Mutex;
/// 空对象
#[derive(Debug)]
pub struct DummyObject {
id: KoID,
inner: Mutex<DummyObjectInner>,
}
/// `DummyObject` 的内部可变部分
#[derive(Default, Debug)]
struct DummyObjectInner {
name: String,
}
为了有效地支持操作系统中的并行和并发处理,我们这里采用了一种内部可变性的设计模式:将对象的所有可变的部分封装到一个内部对象 DummyObjectInner 中,并在原对象中用可保证互斥访问的自旋锁 Mutex 把它包起来,剩下的其它字段都是不可变的。
Mutex 会用最简单的方式帮我们处理好并发访问问题:如果有其他人正在访问,我就在这里忙等。
数据被 Mutex 包起来之后需要首先使用 lock() 拿到锁之后才能访问。此时并发访问已经安全,因此被包起来的结构自动具有了 Send + Sync 特性。
使用自旋锁引入了新的依赖库 spin ,需要在 Cargo.toml 中加入以下声明:
[dependencies]
spin = "0.7"
然后我们为新对象实现构造函数:
// src/object/object.rs
use alloc::sync::Arc;
use core::sync::atomic::*;
impl DummyObject {
/// 创建一个新 `DummyObject`
pub fn new() -> Arc<Self> {
Arc::new(DummyObject {
id: Self::new_koid(),
inner: Default::default(),
})
}
/// 生成一个唯一的 ID
fn new_koid() -> KoID {
static NEXT_KOID: AtomicU64 = AtomicU64::new(1024);
NEXT_KOID.fetch_add(1, Ordering::SeqCst)
}
}
根据文档描述,每个内核对象都有唯一的 ID。为此我们需要实现一个全局的 ID 分配方法。这里采用的方法是用一个静态变量存放下一个待分配 ID 值,每次分配就原子地 加1。
ID 类型使用 u64,保证了数值空间足够大,在有生之年都不用担心溢出问题。在 Zircon 中 ID 从 1024 开始分配,1024 以下保留作内核内部使用。
另外注意这里 new 函数返回类型不是 Self 而是 Arc<Self>,这是的 Arc 为了以后方便并行处理而做的统一约定。
最后我们为它实现 KernelObject 的基本接口:
// src/object/object.rs
impl KernelObject for DummyObject {
fn id(&self) -> KoID {
self.id
}
fn type_name(&self) -> &str {
"DummyObject"
}
fn name(&self) -> String {
self.inner.lock().name.clone()
}
fn set_name(&self, name: &str) {
self.inner.lock().name = String::from(name);
}
}
到此为止,我们已经迈出了万里长征第一步,实现了一个最简单的功能。有实现,就要有测试!即使最简单的代码也要保证它的行为符合我们预期。 只有对现有代码进行充分测试,在未来做添加和修改的时候,我们才有信心不会把事情搞砸。俗话讲"万丈高楼平地起",把地基打好才能盖摩天大楼。
为了证明上面代码的正确性,我们写一个简单的单元测试,替换掉自带的 it_works 函数:
// src/object/object.rs
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn dummy_object() {
let o1 = DummyObject::new();
let o2 = DummyObject::new();
assert_ne!(o1.id(), o2.id());
assert_eq!(o1.type_name(), "DummyObject");
assert_eq!(o1.name(), "");
o1.set_name("object1");
assert_eq!(o1.name(), "object1");
}
}
$ cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.53s
Running target/debug/deps/zcore-ae1be84852989b13
running 1 test
test tests::dummy_object ... ok
大功告成!让我们用 cargo fmt 命令格式化一下代码,然后记得 git commit 及时保存进展。
实现接口到具体类型的向下转换
在系统调用中,用户进程会传入一个内核对象的句柄,然后内核会根据系统调用的类型,尝试将其转换成特定类型的对象。
于是这里产生了一个很重要的需求:将接口 Arc<dyn KernelObject> 转换成具体类型的结构 Arc<T> where T: KernelObject。
这种操作在面向对象语言中称为向下转换(downcast)。
在大部分编程语言中,向下转换都是一件非常轻松的事情。例如在 C/C++ 中,我们可以这样写:
struct KernelObject {...};
struct DummyObject: KernelObject {...};
KernelObject *base = ...;
// C 风格:强制类型转换
DummyObject *dummy = (DummyObject*)(base);
// C++ 风格:动态类型转换
DummyObject *dummy = dynamic_cast<DummyObject*>(base);
但在 Rust 中,由于其 trait 模型的限制,向下转换并不是一件容易的事情。
虽然标准库中提供了 Any trait,部分实现了动态类型的功能,但实际操作起来却困难重重。
不信邪的同学可以自己折腾一下:
use std::any::Any; use std::sync::Arc; fn main() {} trait KernelObject: Any + Send + Sync {} fn downcast_v1<T: KernelObject>(object: Arc<dyn KernelObject>) -> Arc<T> { object.downcast::<T>().unwrap() } fn downcast_v2<T: KernelObject>(object: Arc<dyn KernelObject>) -> Arc<T> { let object: Arc<dyn Any + Send + Sync + 'static> = object; object.downcast::<T>().unwrap() }
当然这个问题也困扰了 Rust 社区中的很多人。目前已经有人提出了一套不错的解决方案,就是我们接下来要引入的 downcast-rs 库:
[dependencies]
downcast-rs = { version = "1.2.0", default-features = false }
(题外话:这个库原来是不支持 no_std 的,zCore 有这个需求,于是就顺便帮他实现了一把)
按照downcast-rs 文档的描述,我们要为自己的接口实现向下转换,只需以下修改:
// src/object/mod.rs
use core::fmt::Debug;
use downcast_rs::{impl_downcast, DowncastSync};
pub trait KernelObject: DowncastSync + Debug {...}
impl_downcast!(sync KernelObject);
其中 DowncastSync 代替了原来的 Send + Sync,Debug 用于出错时输出调试信息。
impl_downcast! 宏用来帮我们自动生成转换函数,然后就可以用 downcast_arc 来对 Arc 做向下转换了。我们直接来测试一把:
// src/object/object.rs
#[test]
fn downcast() {
let dummy = DummyObject::new();
let object: Arc<dyn KernelObject> = dummy;
let _result: Arc<DummyObject> = object.downcast_arc::<DummyObject>().unwrap();
}
$ cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.47s
Running target/debug/deps/zcore-ae1be84852989b13
running 2 tests
test object::downcast ... ok
test object::tests::dummy_object ... ok
模拟继承:用宏自动生成接口实现代码
上面我们已经完整实现了一个内核对象,代码看起来很简洁。但当我们要实现更多对象的时候,就会发现一个问题: 这些对象拥有一些公共属性,接口方法也有共同的实现。 在传统 OOP 语言中,我们通常使用 继承(inheritance) 来复用这些公共代码:子类 B 可以继承父类 A,然后自动拥有父类的所有字段和方法。
继承是一个很强大的功能,但在长期实践中人们也逐渐发现了它的弊端。有兴趣的读者可以看一看知乎上的探讨:面向对象编程的弊端是什么?。
经典著作《设计模式》中就鼓励大家使用组合代替继承。而一些现代的编程语言,如 Go 和 Rust,甚至直接抛弃了继承。在 Rust 中,通常使用组合结构和 Deref trait 来部分模拟继承。
继承野蛮,trait 文明。 —— 某 Rust 爱好者
接下来我们模仿 downcast-rs 库的做法,使用一种基于宏的代码生成方案,来实现 KernelObject 的继承。
当然这只是抛砖引玉,如果读者自己实现了,或者了解到社区中有更好的解决方案,也欢迎指出。
具体做法是这样的:
- 使用一个 struct 来提供所有的公共属性和方法,作为所有子类的第一个成员。
- 为子类实现 trait 接口,所有方法直接委托给内部 struct 完成。这部分使用宏来自动生成模板代码。
而所谓的内部 struct,其实就是我们上面实现的 DummyObject。为了更好地体现它的功能,我们给他改个名叫 KObjectBase:
// src/object/mod.rs
/// 内核对象核心结构
pub struct KObjectBase {
/// 对象 ID
pub id: KoID,
inner: Mutex<KObjectBaseInner>,
}
/// `KObjectBase` 的内部可变部分
#[derive(Default)]
struct KObjectBaseInner {
name: String,
}
接下来我们把它的构造函数改为实现 Default trait,并且公共属性和方法都指定为 pub:
// src/object/mod.rs
impl Default for KObjectBase {
/// 创建一个新 `KObjectBase`
fn default() -> Self {
KObjectBase {
id: Self::new_koid(),
inner: Default::default(),
}
}
}
impl KObjectBase {
/// 生成一个唯一的 ID
fn new_koid() -> KoID {...}
/// 获取对象名称
pub fn name(&self) -> String {...}
/// 设置对象名称
pub fn set_name(&self, name: &str) {...}
}
最后来写一个魔法的宏!
// src/object/mod.rs
/// 为内核对象 struct 自动实现 `KernelObject` trait 的宏。
#[macro_export] // 导出宏,可在 crate 外部使用
macro_rules! impl_kobject {
// 匹配类型名,并可以提供函数覆盖默认实现
($class:ident $( $fn:tt )*) => {
// 为对象实现 KernelObject trait,方法直接转发到内部 struct
impl KernelObject for $class {
fn id(&self) -> KoID {
// 直接访问内部的 pub 属性
self.base.id
}
fn type_name(&self) -> &str {
// 用 stringify! 宏将输入转成字符串
stringify!($class)
}
// 注意宏里面的类型要写完整路径,例如:alloc::string::String
fn name(&self) -> alloc::string::String {
self.base.name()
}
fn set_name(&self, name: &str){
// 直接访问内部的 pub 方法
self.base.set_name(name)
}
// 可以传入任意数量的函数,覆盖 trait 的默认实现
$( $fn )*
}
// 为对象实现 Debug trait
impl core::fmt::Debug for $class {
fn fmt(
&self,
f: &mut core::fmt::Formatter<'_>,
) -> core::result::Result<(), core::fmt::Error> {
// 输出对象类型、ID 和名称
f.debug_tuple(&stringify!($class))
.field(&self.id())
.field(&self.name())
.finish()
}
}
};
}
轮子已经造好了!让我们看看如何用它方便地实现一个内核对象,仍以 DummyObject 为例:
// src/object/mod.rs
/// 空对象
pub struct DummyObject {
// 其中必须包含一个名为 `base` 的 `KObjectBase`
base: KObjectBase,
}
// 使用刚才的宏,声明其为内核对象,自动生成必要的代码
impl_kobject!(DummyObject);
impl DummyObject {
/// 创建一个新 `DummyObject`
#[allow(dead_code)]
pub fn new() -> Arc<Self> {
Arc::new(DummyObject {
base: KObjectBase::default(),
})
}
}
是不是方便了很多?最后按照惯例,用单元测试检验实现的正确性:
// src/object/mod.rs
#[test]
fn impl_kobject() {
use alloc::format;
let dummy = DummyObject::new();
let object: Arc<dyn KernelObject> = dummy;
assert_eq!(object.type_name(), "DummyObject");
assert_eq!(object.name(), "");
object.set_name("dummy");
assert_eq!(object.name(), "dummy");
assert_eq!(
format!("{:?}", object),
format!("DummyObject({}, \"dummy\")", object.id())
);
let _result: Arc<DummyObject> = object.downcast_arc::<DummyObject>().unwrap();
}
有兴趣的读者可以继续探索使用功能更强大的 过程宏(proc_macro),进一步简化实现新内核对象所需的模板代码。 如果能把上面的代码块缩小成下面这两行,就更加完美了:
#[KernelObject]
pub struct DummyObject;
总结
在这一节中我们用 Rust 语言实现了 Zircon 最核心的内核对象概念。在此过程中涉及到 Rust 的一系列语言特性和设计模式:
- 使用 trait 实现接口
- 使用 内部可变性 模式实现并发对象
- 基于社区解决方案实现 trait 到 struct 的 向下转换
- 使用组合模拟继承,并使用 宏 实现模板代码的自动生成
由于 Rust 独特的面向对象编程特性,我们在实现内核对象的过程中遇到了一定的挑战。 不过万事开头难,解决这些问题为整个项目打下了坚实基础,后面实现新的内核对象就会变得简单很多。
在下一节中,我们将介绍内核对象相关的另外两个概念:句柄和权限,并实现内核对象的存储和访问。
对象管理器:Process 对象
句柄——操作内核对象的桥梁
在1.1中我们用Rust语言实现了一个最核心的内核对象,在本小节我们将逐步了解与内核对象相关的三个重要概念中的其他两个:句柄(Handle)和权限(Rights)。
句柄是允许用户程序引用内核对象引用的一种内核结构,它可以被认为是与特定内核对象的会话或连接。
通常情况下,多个进程通过不同的句柄同时访问同一个对象。对象可能有多个句柄(在一个或多个进程中)引用它们。但单个句柄只能绑定到单个进程或绑定到内核。
定义句柄
在 object 模块下定义一个子模块:
// src/object/mod.rs
mod handle;
pub use self::handle::*;
定义句柄:
// src/object/handle.rs
use super::{KernelObject, Rights};
use alloc::sync::Arc;
/// 内核对象句柄
#[derive(Clone)]
pub struct Handle {
pub object: Arc<dyn KernelObject>,
pub rights: Rights,
}
一个Handle包含object和right两个字段,object是实现了KernelObjectTrait的内核对象,Rights是该句柄的权限,我们将在下面提到它。
ArcArc<T> 的创建或复制而增加,并当 Arc<T> 生命周期结束被回收时减少。当这个计数变为零之后,这个计数变量本身以及被引用的变量都会从堆上被回收。
我们为什么要在这里使用Arc智能指针呢?
绝大多数内核对象的析构都发生在句柄数量为 0 时,也就是最后一个指向内核对象的Handle被关闭,该对象也随之消亡,抑或进入一种无法撤销的最终状态。很明显,这与Arc
控制句柄的权限——Rights
上文的Handle中有一个字段是rights,也就是句柄的权限。顾名思义,权限规定该句柄对引用的对象可以进行何种操作。
当不同的权限和同一个对象绑定在一起时,也就形成了不同的句柄。
定义权限
在 object 模块下定义一个子模块:
// src/object/mod.rs
mod rights;
pub use self::rights::*;
权限就是u32的一个数字
// src/object/rights.rs
use bitflags::bitflags;
bitflags! {
/// 句柄权限
pub struct Rights: u32 {
const DUPLICATE = 1 << 0;
const TRANSFER = 1 << 1;
const READ = 1 << 2;
const WRITE = 1 << 3;
const EXECUTE = 1 << 4;
...
}
bitflags 是一个 Rust 中常用来比特标志位的 crate 。它提供了 一个 bitflags! 宏,如上面的代码段所展示的那样,借助 bitflags! 宏我们将一个 u32 的 rights 包装为一个 Rights 结构体。注意,在使用之前我们需要引入该 crate 的依赖:
Cargo.toml
[dependencies]
bitflags = "1.2"
定义好权限之后,我们回到句柄相关方法的实现。
首先是最简单的部分,创建一个handle,很显然我们需要提供两个参数,分别是句柄关联的内核对象和句柄的权限。
impl Handle {
/// 创建一个新句柄
pub fn new(object: Arc<dyn KernelObject>, rights: Rights) -> Self {
Handle { object, rights }
}
}
测试
好啦,让我们来测试一下!
#[cfg(test)]
mod tests {
use super::*;
use crate::object::DummyObject;
#[test]
fn new_obj_handle() {
let obj = DummyObject::new();
let handle1 = Handle::new(obj.clone(), Rights::BASIC);
}
}
句柄存储的载体——Process
实现完了句柄之后,我们开始考虑,句柄是存储在哪里的呢?
通过前面的讲解,很明显Process拥有内核对象句柄,也就是说,句柄存储在Process中,所以我们先来实现一个Process:
实现空的process对象
// src/task/process.rs
/// 进程对象
pub struct Process {
base: KObjectBase,
inner: Mutex<ProcessInner>,
}
// 宏的作用:补充
impl_kobject!(Process);
struct ProcessInner {
handles: BTreeMap<HandleValue, Handle>,
}
pub type HandleValue = u32;
handles使用BTreeMap存储的key是HandleValue,value就是句柄。通过HandleValue实现对句柄的增删操作。HandleValue实际上就是u32类型是别名。
把内部对象ProcessInner用自旋锁Mutex包起来,保证了互斥访问,因为Mutex会帮我们处理好并发问题,这一点已经在1.1节中详细说明。
接下来我们实现创建一个Process的方法:
impl Process {
/// 创建一个新的进程对象
pub fn new() -> Arc<Self> {
Arc::new(Process {
base: KObjectBase::default(),
inner: Mutex::new(ProcessInner {
handles: BTreeMap::default(),
}),
})
}
}
单元测试
我们已经实现了创建一个Process的方法,下面我们写一个单元测试:
#[test]
fn new_proc() {
let proc = Process::new();
assert_eq!(proc.type_name(), "Process");
assert_eq!(proc.name(), "");
proc.set_name("proc1");
assert_eq!(proc.name(), "proc1");
assert_eq!(
format!("{:?}", proc),
format!("Process({}, \"proc1\")", proc.id())
);
let obj: Arc<dyn KernelObject> = proc;
assert_eq!(obj.type_name(), "Process");
assert_eq!(obj.name(), "proc1");
obj.set_name("proc2");
assert_eq!(obj.name(), "proc2");
assert_eq!(
format!("{:?}", obj),
format!("Process({}, \"proc2\")", obj.id())
);
}
Process相关方法
插入句柄
在Process中添加一个新的handle,返回值是一个handleValue,也就是u32:
pub fn add_handle(&self, handle: Handle) -> HandleValue {
let mut inner = self.inner.lock();
let value = (0 as HandleValue..)
.find(|idx| !inner.handles.contains_key(idx))
.unwrap();
// 插入BTreeMap
inner.handles.insert(value, handle);
value
}
移除句柄
删除Process中的一个句柄:
pub fn remove_handle(&self, handle_value: HandleValue) {
self.inner.lock().handles.remove(&handle_value);
}
根据句柄查找内核对象
// src/task/process.rs
impl Process {
/// 根据句柄值查找内核对象,并检查权限
pub fn get_object_with_rights<T: KernelObject>(
&self,
handle_value: HandleValue,
desired_rights: Rights,
) -> ZxResult<Arc<T>> {
let handle = self
.inner
.lock()
.handles
.get(&handle_value)
.ok_or(ZxError::BAD_HANDLE)?
.clone();
// check type before rights
let object = handle
.object
.downcast_arc::<T>()
.map_err(|_| ZxError::WRONG_TYPE)?;
if !handle.rights.contains(desired_rights) {
return Err(ZxError::ACCESS_DENIED);
}
Ok(object)
}
}
ZxResult
ZxResult是表示Zircon状态的i32值,值空间划分如下:
- 0:ok
- 负值:由系统定义(也就是这个文件)
- 正值:被保留,用于协议特定的错误值,永远不会被系统定义。
pub type ZxResult<T> = Result<T, ZxError>;
#[allow(non_camel_case_types, dead_code)]
#[repr(i32)]
#[derive(Debug, Clone, Copy)]
pub enum ZxError {
OK = 0,
...
/// 一个不指向handle的特定的handle value
BAD_HANDLE = -11,
/// 操作主体对于执行这个操作来说是错误的类型
/// 例如: 尝试执行 message_read 在 thread handle.
WRONG_TYPE = -12,
// 权限检查错误
// 调用者没有执行该操作的权限
ACCESS_DENIED = -30,
}
ZxResult
单元测试
目前为止,我们已经实现了Process最基础的方法,下面我们来运行一个单元测试:
fn proc_handle() {
let proc = Process::new();
let handle = Handle::new(proc.clone(), Rights::DEFAULT_PROCESS);
let handle_value = proc.add_handle(handle);
let object1: Arc<Process> = proc
.get_object_with_rights(handle_value, Rights::DEFAULT_PROCESS)
.expect("failed to get object");
assert!(Arc::ptr_eq(&object1, &proc));
proc.remove_handle(handle_value);
}
总结
在这一节中我们实现了内核对象的两个重要的概念,句柄(Handle)和权限(Rights),同时实现了句柄存储的载体——Process,并且实现了Process的基本方法,这将是我们继续探索zCore的基础。
在下一节中,我们将介绍内核对象的传输器——管道(Channel)。
对象传送器:Channel 对象
概要
通道(Channel)是由一定数量的字节数据和一定数量的句柄组成的双向消息传输。
用于IPC的内核对象
Zircon中用于IPC的内核对象主要有Channel、Socket和FIFO。这里我们主要介绍一下前两个。
进程间通信(IPC,Inter-Process Communication),指至少两个进程或线程间传送数据或信号的一些技术或方法。进程是计算机系统分配资源的最小单位(进程是分配资源最小的单位,而线程是调度的最小单位,线程共用进程资源)。每个进程都有自己的一部分独立的系统资源,彼此是隔离的。为了能使不同的进程互相访问资源并进行协调工作,才有了进程间通信。举一个典型的例子,使用进程间通信的两个应用可以被分类为客户端和服务器,客户端进程请求数据,服务端回复客户端的数据请求。有一些应用本身既是服务器又是客户端,这在分布式计算中,时常可以见到。这些进程可以运行在同一计算机上或网络连接的不同计算机上。
Socket和Channel都是双向和双端的IPC相关的Object。创建Socket或Channel将返回两个不同的Handle,分别指向Socket或Channel的两端。与channel的不同之处在于,socket仅能传输数据(而不移动句柄),而channel可以传递句柄。
Socket是面向流的对象,可以通过它读取或写入以一个或多个字节为单位的数据。Channel是面向数据包的对象,并限制消息的大小最多为64K(如果有改变,可能会更小),以及最多1024个Handle挂载到同一消息上(如果有改变,同样可能会更小)。
当Handle被写入到Channel中时,在发送端Process中将会移除这些Handle。同时携带Handle的消息从Channel中被读取时,该Handle也将被加入到接收端Process中。在这两个时间点之间时,Handle将同时存在于两端(以保证它们指向的Object继续存在而不被销毁),除非Channel写入方向一端被关闭,这种情况下,指向该端点的正在发送的消息将被丢弃,并且它们包含的任何句柄都将被关闭。
Channel
Channel是唯一一个能传递handle的IPC,其他只能传递消息。通道有两个端点endpoints,对于代码实现来说,通道是虚拟的,我们实际上是用通道的两个端点来描述一个通道。两个端点各自要维护一个消息队列,在一个端点写消息,实际上是把消息写入另一个端点的消息队列队尾;在一个端点读消息,实际上是从当前端点的消息队列的队头读出一个消息。
消息通常含有data和handles两部分,我们这里将消息封装为MessagePacket结构体,结构体中含有上述两个字段:
#[derive(Default)]
pub struct MessagePacket {
/// message packet携带的数据data
pub data: Vec<u8>,
/// message packet携带的句柄Handle
pub handles: Vec<Handle>,
}
实现空的Channel对象
在src目录下创建一个ipc目录,在ipc模块下定义一个子模块channel:
// src/ipc/mod.rs
use super::*;
mod channel;
pub use self::channel::*;
在ipc.rs中引入crate:
// src/ipc/channel.rs
use {
super::*,
crate::error::*,
crate::object::*,
alloc::collections::VecDeque,
alloc::sync::{Arc, Weak},
spin::Mutex,
};
把在上面提到的MessagePacket结构体添加到该文件中。
下面我们添加Channel结构体:
// src/ipc/channel.rs
pub struct Channel {
base: KObjectBase,
peer: Weak<Channel>,
recv_queue: Mutex<VecDeque<T>>,
}
type T = MessagePacket;
peer代表当前端点所在管道的另一个端点,两端的结构体分别持有对方的Weak引用,并且两端的结构体将分别通过Arc引用,作为内核对象而被内核中的其他数据结构引用,这一部分我们将在创建Channel实例时提到。
recv_queue代表当前端点维护的消息队列,它使用VecDeque来存放MessagePacket,可以通过pop_front()、push_back等方法在队头弹出数据和在队尾压入数据。
用使用宏自动实现 KernelObject trait ,使用channel类型名,并添加两个函数。
impl_kobject!(Channel
fn peer(&self) -> ZxResult<Arc<dyn KernelObject>> {
let peer = self.peer.upgrade().ok_or(ZxError::PEER_CLOSED)?;
Ok(peer)
}
fn related_koid(&self) -> KoID {
self.peer.upgrade().map(|p| p.id()).unwrap_or(0)
}
);
实现创建Channel的方法
下面我们来实现创建一个Channel的方法:
impl Channel {
#[allow(unsafe_code)]
pub fn create() -> (Arc<Self>, Arc<Self>) {
let mut channel0 = Arc::new(Channel {
base: KObjectBase::default(),
peer: Weak::default(),
recv_queue: Default::default(),
});
let channel1 = Arc::new(Channel {
base: KObjectBase::default(),
peer: Arc::downgrade(&channel0),
recv_queue: Default::default(),
});
// no other reference of `channel0`
unsafe {
Arc::get_mut_unchecked(&mut channel0).peer = Arc::downgrade(&channel1);
}
(channel0, channel1)
}
该方法的返回值是两端点结构体(Channel)的Arc引用,这将作为内核对象被内核中的其他数据结构引用。两个端点互相持有对方Weak指针,这是因为一个端点无需引用计数为0,只要strong_count为0就可以被清理掉,即使另一个端点指向它。
rust 语言并没有提供垃圾回收 (GC, Garbage Collection ) 的功能, 不过它提供了最简单的引用计数包装类型
Rc,这种引用计数功能也是早期 GC 常用的方法, 但是引用计数不能解决循环引用。那么如何 fix 这个循环引用呢?答案是Weak指针,只增加引用逻辑,不共享所有权,即不增加 strong reference count。由于Weak指针指向的对象可能析构了,所以不能直接解引用,要模式匹配,再 upgrade。
下面我们来分析一下这个unsafe代码块:
unsafe {
Arc::get_mut_unchecked(&mut channel0).peer = Arc::downgrade(&channel1);
}
由于两端的结构体将分别通过 Arc 引用,作为内核对象而被内核中的其他数据结构使用。因此,在同时初始化两端的同时,将必须对某一端的 Arc 指针进行获取可变引用的操作,即get_mut_unchecked接口。当 Arc 指针的引用计数不为 1 时,这一接口是非常不安全的,但是在当前情境下,我们使用这一接口进行IPC 对象的初始化,安全性是可以保证的。
单元测试
下面我们写一个单元测试,来验证我们写的create方法:
#[test]
fn test_basics() {
let (end0, end1) = Channel::create();
assert!(Arc::ptr_eq(
&end0.peer().unwrap().downcast_arc().unwrap(),
&end1
));
assert_eq!(end0.related_koid(), end1.id());
drop(end1);
assert_eq!(end0.peer().unwrap_err(), ZxError::PEER_CLOSED);
assert_eq!(end0.related_koid(), 0);
}
实现数据传输
Channel中的数据传输,可以理解为MessagePacket在两个端点之间的传输,那么谁可以读写消息呢?
有一个句柄与通道端点相关联,持有该句柄的进程被视为所有者(owner)。所以是(持有与通道端点关联句柄的)进程可以读取或写入消息,或将通道端点发送到另一个进程。
当MessagePacket被写入通道时,它们会从发送进程中删除。当从通道读取MessagePacket时,MessagePacket的句柄被添加到接收进程中。
read
获取当前端点的recv_queue,从队头中读取一条消息,如果能读取到消息,返回Ok,否则返回错误信息。
pub fn read(&self) -> ZxResult<T> {
let mut recv_queue = self.recv_queue.lock();
if let Some(_msg) = recv_queue.front() {
let msg = recv_queue.pop_front().unwrap();
return Ok(msg);
}
if self.peer_closed() {
Err(ZxError::PEER_CLOSED)
} else {
Err(ZxError::SHOULD_WAIT)
}
}
write
先获取当前端点对应的另一个端点的Weak指针,通过upgrade接口升级为Arc指针,从而获取到对应的结构体对象。在它的recv_queue队尾push一个MessagePacket。
pub fn write(&self, msg: T) -> ZxResult {
let peer = self.peer.upgrade().ok_or(ZxError::PEER_CLOSED)?;
peer.push_general(msg);
Ok(())
}
fn push_general(&self, msg: T) {
let mut send_queue = self.recv_queue.lock();
send_queue.push_back(msg);
}
单元测试
下面我们写一个单元测试,验证我们上面写的read和write两个方法:
#[test]
fn read_write() {
let (channel0, channel1) = Channel::create();
// write a message to each other
channel0
.write(MessagePacket {
data: Vec::from("hello 1"),
handles: Vec::new(),
})
.unwrap();
channel1
.write(MessagePacket {
data: Vec::from("hello 0"),
handles: Vec::new(),
})
.unwrap();
// read message should success
let recv_msg = channel1.read().unwrap();
assert_eq!(recv_msg.data.as_slice(), b"hello 1");
assert!(recv_msg.handles.is_empty());
let recv_msg = channel0.read().unwrap();
assert_eq!(recv_msg.data.as_slice(), b"hello 0");
assert!(recv_msg.handles.is_empty());
// read more message should fail.
assert_eq!(channel0.read().err(), Some(ZxError::SHOULD_WAIT));
assert_eq!(channel1.read().err(), Some(ZxError::SHOULD_WAIT));
}
总结
在这一节中我们实现了唯一一个可以传递句柄的对象传输器——Channel,我们先了解的Zircon中主要的IPC内核对象,再介绍了Channel如何创建和实现read和write函数的细节。
本章我们学习了中最核心的几个内核对象,在下一章中,我们将学习Zircon的任务管理体系和进程、线程管理的对象。
任务管理
本章我们来实现第一类内核对象:任务管理(Tasks)。
任务对象主要包括:线程 Thread,进程 Process,作业 Job。以及一些辅助性的对象,例如负责暂停任务执行的 SuspendToken 和负责处理异常的 Exception。
为了能够真实表现线程对象的行为,我们使用 Rust async 运行时 async_std 中的用户态协程来模拟内核线程。
这样就可以在用户态的单元测试中检验实现的正确性。
考虑到未来这个 OS 会跑在裸机环境中,将会有不同的内核线程的实现,我们创建一个特殊的硬件抽象层(Hardware Abstraction Layer,HAL),来屏蔽底层平台的差异,对上提供一个统一的接口。
这个 HAL 的接口未来会根据需要进行扩充。
本章中我们只会实现运行一个程序所必需的最小功能子集,剩下的部分则留到跑起用户程序之后再按需实现。
Zircon 任务管理体系
线程(Thread)表示包含进程(Proess)所拥有的地址空间中的多个执行控制流(CPU寄存器,堆栈等)。进程属于作业(Job),作业定义了各种资源限制。作业一直由父级作业(parent Jobs)拥有,一直到根作业(Root Job)为止,根作业是内核在启动时创建并传递给userboot(第一个开始执行的用户进程)。
如果没有作业句柄(Job Handle),则进程中的线程无法创建另一个进程或另一个作业。
程序加载由内核层以上的用户空间工具和协议提供。
一些相关的系统调用:
zx_process_create(), zx_process_start(), zx_thread_create(), zx_thread_start()
进程管理:Process 与 Job 对象
介绍 Process 与 Job 的整体设计
实现 Process 和 Job 对象的基本框架,支持树状结构
作业Job
概要
作业是一组进程,可能还包括其他(子)作业。作业用于跟踪执行内核操作的特权(即使用各种选项进行各种syscall),以及跟踪和限制基本资源(例如内存,CPU)的消耗。每个进程都属于一个作业。作业也可以嵌套,并且除根作业外的每个作业都属于一个(父)作业。
描述
作业是包含以下内容的对象:
- 对父作业的引用
- 一组子作业(每个子作业的父作业既是这个作业)
- 一组成员进程
- 一套策略(Policy)
由多个进程组成的“应用程序”可作为单个实体,被作业基于一套策略进行控制。
作业策略Job Policy
策略policy 可在Kernel运行时动态修改系统的各种配置(setting)。作业策略主要涉及作业安全性和资源使用的条件(Condition)限制。
策略的行为PolicyAction
策略的行为包括:
- Allow 允许条件
- Deny 拒绝条件
- AllowException 通过 debugt port 生成异常,异常处理完毕后可恢复执行且运行条件
- DenyException 通过 debugt port 生成异常,异常处理完毕后可恢复执行
- Kill 杀死进程
应用策略时的条件 PolicyCondition
应用策略时的条件包括:
- BadHandle: 此作业下的某个进程正在尝试发出带有无效句柄的syscall。在这种情况下,
PolicyAction::Allow并且PolicyAction::Deny是等效的:如果syscall返回,它将始终返回错误ZX_ERR_BAD_HANDLE。 - WrongObject:此作业下的某个进程正在尝试发出带有不支持该操作的句柄的syscall。
- VmarWx:此作业下的进程正在尝试映射具有写执行访问权限的地址区域。
- NewAny:代表上述所有ZX_NEW条件的特殊条件,例如NEW_VMO,NEW_CHANNEL,NEW_EVENT,NEW_EVENTPAIR,NEW_PORT,NEW_SOCKET,NEW_FIFO和任何将来的ZX_NEW策略。这将包括不需要父对象来创建的所有新内核对象。
- NewVMO:此作业下的某个进程正在尝试创建新的vm对象。
- NewChannel:此作业下的某个进程正在尝试创建新通道。
- NewEvent:此作业下的一个进程正在尝试创建一个新事件。
- NewEventPair:此作业下的某个进程正在尝试创建新的事件对。
- NewPort:此作业下的进程正在尝试创建新端口。
- NewSocket:此作业下的进程正在尝试创建新的套接字。
- NewFIFO:此工作下的一个进程正在尝试创建一个新的FIFO。
- NewTimer:此作业下的某个进程正在尝试创建新的计时器。
- NewProcess:此作业下的进程正在尝试创建新进程。
- NewProfile:此作业下的一个进程正在尝试创建新的配置文件。
- AmbientMarkVMOExec:此作业下的某个进程正在尝试使用带有ZX_HANDLE_INVALID的zx_vmo_replace_as_executable()作为第二个参数,而不是有效的ZX_RSRC_KIND_VMEX。
进程Process
进程是传统意义上程序的一个运行实例,包含一组指令和数据,这些指令将由一个或多个线程执行,并拥有一组资源。在具体实现上,进程包括如下内容:
- Handles :大部分是进程用到的资源对象的句柄
- Virtual Memory Address Regions:进程所在的内存地址空间
- Threads:进程包含的线程组
进程包含在作业(Job)的管理范畴之中。从资源和权限限制以及生命周期控制的角度来看,允许将由多个进程组成的应用程序视为一个实体(即作业)。
生命周期(lifetime)
进程有自己的生命周期,从开始创建到直到被强制终止或程序退出为止。可通过调用Process::create()创建一个进程,并调用Process::start()开始执行 。该进程在以下情况下停止执行:
- 最后一个线程终止或退出
- 进程调用
Process::exit() - 父作业(parent job)终止了该过程
- 父作业(parent job)被销毁(destroied)
注:Process::start()不能被调用两次。新线程不能被添加到已启动的进程。
线程管理:Thread 对象
线程对象是代表分时CPU的执行上下文的一种结构。线程对象与特定的进程对象相关联,该进程对象为线程对象执行中涉及的I/O和计算提供提供必要的内存和其他对象的句柄。
生命期
线程是通过调用Thread::create()创建的,但只有在调用Thread::create()或Process::start()时才开始执行。这两个系统调用的参数都是要执行的初始例程的入口。
传递给Process::start()的线程应该是在一个进程上开始执行的第一个线程。
下列情况都可导致一个线程终止执行:
- 通过调用
CurrentThread::exit() - 当父进程终止时
- 通过调用
Task::kill() - 在生成没有处理程序或处理程序决定终止线程的异常之后。
从入口例程返回并不终止执行。入口点的最后一个动作应该是调用CurrentThread::exit()。
关闭一个线程的最后一个句柄并不终止执行。为了强行杀死一个没有可用句柄的线程,可以使用KernelObject::get_child()来获得该线程的句柄。但这种方法是非常不可取的。杀死一个正在执行的线程可能会使进程处于损坏的状态。
本地线程总是分离的(detached)。也就是说,不需要join()操作来做一个干净的终止(clean termination)。但一些内核之上的运行系统,如C11或POSIX可能需要线程被连接(be joined)。
信号
线程提供以下信号:
- THREAD_TERMINATED
- THREAD_SUSPENDED
- THREAD_RUNNING
当一个线程启动执行时,THREAD_RUNNING被设定。当它被暂停时,THREAD_RUNNING被取消,THREAD_SUSPENDED被设定。当线程恢复时,THREAD_SUSPENDED被取消,THREAD_RUNNING被设定。当线程终止时,THREAD_RUNNING和THREAD_SUSPENDED都被置位,THREAD_TERMINATED也被置位。
注意,信号经过“或”运算后进入KernelObject::wait_signal()函数系列所保持的状态 ,因此当它们返回时,你可能会看到所要求的信号的任何组合。
线程状态(ThreadState)
状态转移:创建 -> 运行 -> 暂停 -> 退出,最好有个状态机的图
实现 ThreadState,最好能加一个单元测试来验证转移过程
#![allow(unused)] fn main() { pub enum ThreadState { New, \\该线程已经创建,但还没有开始运行 Running, \\该线程正在正常运行用户代码 Suspended, \\由于zx_task_suspend()而暂停 Blocked, \\在一个系统调用中或处理一个异常而阻塞 Dying, \\线程正在被终止的过程中,但还没有停止运行 Dead, \\该线程已停止运行 BlockedException, \\该线程在一个异常中被阻塞 BlockedSleeping, \\该线程在zx_nanosleep()中被阻塞 BlockedFutex, \\该线程在zx_futex_wait()中被阻塞 BlockedPort, \\该线程在zx_port_wait()中被被阻塞 BlockedChannel, \\该线程在zx_channel_call()中被阻塞 BlockedWaitOne, \\该线程在zx_object_wait_one()中被阻塞 BlockedWaitMany, \\该线程在zx_object_wait_many()中被阻塞 BlockedInterrupt, \\该线程在zx_interrupt_wait()中被阻塞 BlockedPager, \\被Pager阻塞 (目前没用到???) } }
线程寄存器上下文
定义 ThreadState,实现 read_state,write_state
Async 运行时和 HAL 硬件抽象层
简单介绍 async-std 的异步机制
介绍 HAL 的实现方法:弱链接
实现 hal_thread_spawn
线程启动
将 HAL 接入 Thread::start,编写单元测试验证能启动多线程
内存管理
Zircon 内存管理模型
Zircon 中有两个跟内存管理有关的对象 VMO(Virtual Memory Object)和 VMAR (Virtual Memory Address Region)。VMO 主要负责管理物理内存页面,VMAR 主要负责进程虚拟内存管理。当创建一个进程的时候,需要使用到内存的时候,都需要创建一个 VMO,然后将这个 VMO map 到 VMAR上面。
物理内存:VMO 对象
VMO 简介
根据文档梳理 VMO 的主要特性
虚拟拟内存对象(Virtual Memory Objects, VMO)代表一组物理内存页面,或 潜在的页面(将根据需要延迟创建/填充)。
它们可以通过 zx_vmar_map()被映射到一个进程(Process)的地址空间,也可通过 zx_vmar_unmap()来解除映射。可以使用zx_vmar_protect()来调整映射页面的权限。
也可以直接使用zx_vmo_read()来读取VMO和通过使用 zx_vmo_write()来写入 VMO。因此,通过诸如“创建 VMO,将数据集写入其中,然后将其交给另一个进程使用”等一次性(one-shot )操作,可以避免将它们映射到地址空间的开销。
实现 VMO 对象框架
实现 VmObject 结构,其中定义 VmObjectTrait 接口,并提供三个具体实现 Paged, Physical, Slice
VmObject 结构体
#![allow(unused)] fn main() { // vm/vmo/mod.rs pub struct VmObject { base: KObjectBase, resizable: bool, trait_: Arc<dyn VMObjectTrait>, inner: Mutex<VmObjectInner>, } impl_kobject!(VmObject); #[derive(Default)] struct VmObjectInner { parent: Weak<VmObject>, children: Vec<Weak<VmObject>>, mapping_count: usize, content_size: usize, } }
trait_ 指向实现了 VMObjectTrait 的对象,它由三个具体实现,分别是 VMObjectPage, VMObjectPhysical, VMObjectSlice。VMObjectPaged 是按页分配内存,VMObjectSlice 主要用于共享内存,VMObjectPhysical 在 zCore-Tutorial 中暂时不会使用到。
mapping_count 表示这个 VmObject 被 map 到几个 VMAR 中。
content_size 是分配的物理内存的大小。
VmObjectTrait 定义了一组 VMObject* 共有的方法
#![allow(unused)] fn main() { pub trait VMObjectTrait: Sync + Send { /// Read memory to `buf` from VMO at `offset`. fn read(&self, offset: usize, buf: &mut [u8]) -> ZxResult; /// Write memory from `buf` to VMO at `offset`. fn write(&self, offset: usize, buf: &[u8]) -> ZxResult; /// Resets the range of bytes in the VMO from `offset` to `offset+len` to 0. fn zero(&self, offset: usize, len: usize) -> ZxResult; /// Get the length of VMO. fn len(&self) -> usize; /// Set the length of VMO. fn set_len(&self, len: usize) -> ZxResult; /// Commit a page. fn commit_page(&self, page_idx: usize, flags: MMUFlags) -> ZxResult<PhysAddr>; /// Commit pages with an external function f. /// the vmo is internally locked before it calls f, /// allowing `VmMapping` to avoid deadlock fn commit_pages_with( &self, f: &mut dyn FnMut(&mut dyn FnMut(usize, MMUFlags) -> ZxResult<PhysAddr>) -> ZxResult, ) -> ZxResult; /// Commit allocating physical memory. fn commit(&self, offset: usize, len: usize) -> ZxResult; /// Decommit allocated physical memory. fn decommit(&self, offset: usize, len: usize) -> ZxResult; /// Create a child VMO. fn create_child(&self, offset: usize, len: usize) -> ZxResult<Arc<dyn VMObjectTrait>>; /// Append a mapping to the VMO's mapping list. fn append_mapping(&self, _mapping: Weak<VmMapping>) {} /// Remove a mapping from the VMO's mapping list. fn remove_mapping(&self, _mapping: Weak<VmMapping>) {} /// Complete the VmoInfo. fn complete_info(&self, info: &mut VmoInfo); /// Get the cache policy. fn cache_policy(&self) -> CachePolicy; /// Set the cache policy. fn set_cache_policy(&self, policy: CachePolicy) -> ZxResult; /// Count committed pages of the VMO. fn committed_pages_in_range(&self, start_idx: usize, end_idx: usize) -> usize; /// Pin the given range of the VMO. fn pin(&self, _offset: usize, _len: usize) -> ZxResult { Err(ZxError::NOT_SUPPORTED) } /// Unpin the given range of the VMO. fn unpin(&self, _offset: usize, _len: usize) -> ZxResult { Err(ZxError::NOT_SUPPORTED) } /// Returns true if the object is backed by a contiguous range of physical memory. fn is_contiguous(&self) -> bool { false } /// Returns true if the object is backed by RAM. fn is_paged(&self) -> bool { false } } }
read() 和 write() 用于读和写,zero() 用于清空一段内存。
比较特别的是:fn commit_page(&self, page_idx: usize, flags: MMUFlags) -> ZxResult<PhysAddr>;,fn commit(&self, offset: usize, len: usize) -> ZxResult; 和 fn commit(&self, offset: usize, len: usize) -> ZxResult; 主要用于分配物理内存,因为一些内存分配策略,物理内存并不一定是马上分配的,所以需要 commit 来分配一块内存。
pin 和 unpin 在这里主要用于增加和减少引用计数。
VmObject 实现了不同的 new 方法,它们之间的差别在于实现 trait_ 的对象不同。
#![allow(unused)] fn main() { impl VmObject { /// Create a new VMO backing on physical memory allocated in pages. pub fn new_paged(pages: usize) -> Arc<Self> { Self::new_paged_with_resizable(false, pages) } /// Create a new VMO, which can be resizable, backing on physical memory allocated in pages. pub fn new_paged_with_resizable(resizable: bool, pages: usize) -> Arc<Self> { let base = KObjectBase::new(); Arc::new(VmObject { resizable, trait_: VMObjectPaged::new(pages), inner: Mutex::new(VmObjectInner::default()), base, }) } /// Create a new VMO representing a piece of contiguous physical memory. pub fn new_physical(paddr: PhysAddr, pages: usize) -> Arc<Self> { Arc::new(VmObject { base: KObjectBase::new(), resizable: false, trait_: VMObjectPhysical::new(paddr, pages), inner: Mutex::new(VmObjectInner::default()), }) } /// Create a VM object referring to a specific contiguous range of physical frame. pub fn new_contiguous(pages: usize, align_log2: usize) -> ZxResult<Arc<Self>> { let vmo = Arc::new(VmObject { base: KObjectBase::new(), resizable: false, trait_: VMObjectPaged::new_contiguous(pages, align_log2)?, inner: Mutex::new(VmObjectInner::default()), }); Ok(vmo) } } }
通过 pub fn create_child(self: &Arc<Self>, resizable: bool, offset: usize, len: usize) 可以创建一个 VMObject 的快照副本。
#![allow(unused)] fn main() { impl VmObject { /// Create a child VMO. pub fn create_child( self: &Arc<Self>, resizable: bool, offset: usize, len: usize, ) -> ZxResult<Arc<Self>> { // Create child VmObject let base = KObjectBase::with_name(&self.base.name()); let trait_ = self.trait_.create_child(offset, len)?; let child = Arc::new(VmObject { base, resizable, trait_, inner: Mutex::new(VmObjectInner { parent: Arc::downgrade(self), ..VmObjectInner::default() }), }); // Add child VmObject to this VmObject self.add_child(&child); Ok(child) } /// Add child to the list fn add_child(&self, child: &Arc<VmObject>) { let mut inner = self.inner.lock(); // 判断这个 child VmObject 是否还是存在,通过获取子对象的强引用数来判断 inner.children.retain(|x| x.strong_count() != 0); // downgrade 将 Arc 转为 Weak inner.children.push(Arc::downgrade(child)); } } }
HAL:用文件模拟物理内存
初步介绍 mmap,引出用文件模拟物理内存的思想
创建文件并用 mmap 线性映射到进程地址空间
实现 pmem_read, pmem_write
mmap
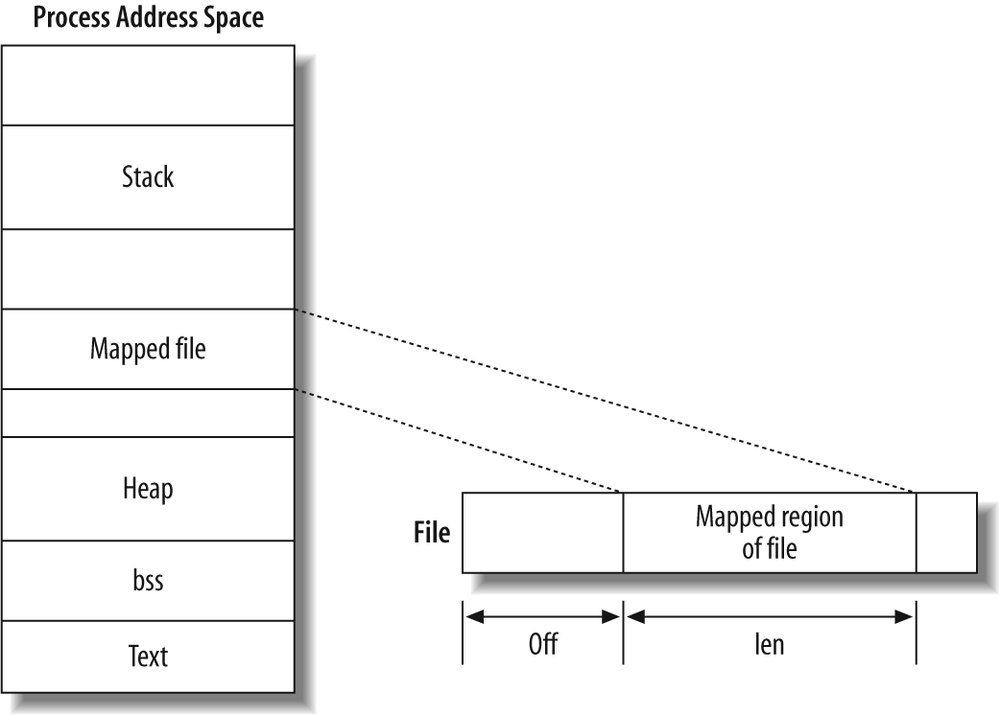
mmap是一种内存映射文件的方法,将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址一一对应的关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。因此,新建一个文件,然后调用 mmap,其实就相当于分配了一块物理内存,因此我们可以用文件来模拟物理内存。
分配地址空间
创建一个文件用于 mmap 系统调用。
#![allow(unused)] fn main() { fn create_pmem_file() -> File { let dir = tempdir().expect("failed to create pmem dir"); let path = dir.path().join("pmem"); // workaround on macOS to avoid permission denied. // see https://jiege.ch/software/2020/02/07/macos-mmap-exec/ for analysis on this problem. #[cfg(target_os = "macos")] std::mem::forget(dir); let file = OpenOptions::new() .read(true) .write(true) .create(true) .open(&path) .expect("failed to create pmem file"); file.set_len(PMEM_SIZE as u64) .expect("failed to resize file"); trace!("create pmem file: path={:?}, size={:#x}", path, PMEM_SIZE); let prot = libc::PROT_READ | libc::PROT_WRITE; // 调用 mmap (这个不是系统调用)进行文件和内存之间的双向映射 mmap(file.as_raw_fd(), 0, PMEM_SIZE, phys_to_virt(0), prot); file } }
mmap:
#![allow(unused)] fn main() { /// Mmap frame file `fd` to `vaddr`. fn mmap(fd: libc::c_int, offset: usize, len: usize, vaddr: VirtAddr, prot: libc::c_int) { // 根据不同的操作系统去修改权限 // workaround on macOS to write text section. #[cfg(target_os = "macos")] let prot = if prot & libc::PROT_EXEC != 0 { prot | libc::PROT_WRITE } else { prot }; // 调用 mmap 系统调用,ret 为返回值 let ret = unsafe { let flags = libc::MAP_SHARED | libc::MAP_FIXED; libc::mmap(vaddr as _, len, prot, flags, fd, offset as _) } as usize; trace!( "mmap file: fd={}, offset={:#x}, len={:#x}, vaddr={:#x}, prot={:#b}", fd, offset, len, vaddr, prot, ); assert_eq!(ret, vaddr, "failed to mmap: {:?}", Error::last_os_error()); } }
最后创建一个全局变量保存这个分配的内存
#![allow(unused)] fn main() { lazy_static! { static ref FRAME_FILE: File = create_pmem_file(); } }
pmem_read 和 pmem_write
#![allow(unused)] fn main() { /// Read physical memory from `paddr` to `buf`. #[export_name = "hal_pmem_read"] pub fn pmem_read(paddr: PhysAddr, buf: &mut [u8]) { trace!("pmem read: paddr={:#x}, len={:#x}", paddr, buf.len()); assert!(paddr + buf.len() <= PMEM_SIZE); ensure_mmap_pmem(); unsafe { (phys_to_virt(paddr) as *const u8).copy_to_nonoverlapping(buf.as_mut_ptr(), buf.len()); } } /// Write physical memory to `paddr` from `buf`. #[export_name = "hal_pmem_write"] pub fn pmem_write(paddr: PhysAddr, buf: &[u8]) { trace!("pmem write: paddr={:#x}, len={:#x}", paddr, buf.len()); assert!(paddr + buf.len() <= PMEM_SIZE); ensure_mmap_pmem(); unsafe { buf.as_ptr() .copy_to_nonoverlapping(phys_to_virt(paddr) as _, buf.len()); } } /// Ensure physical memory are mmapped and accessible. fn ensure_mmap_pmem() { FRAME_FILE.as_raw_fd(); } }
ensure_mmap_pmem() 确保物理内存已经映射
copy_to_nonoverlapping(self, dst *mut T, count: usize) 将 self 的字节序列拷贝到 dst 中,source 和 destination 是不互相重叠的。(phys_to_virt(paddr) as *const u8).copy_to_nonoverlapping(buf.as_mut_ptr(), buf.len()); 通过 phys_to_virt(paddr) 将 paddr 加上 PMEM_BASE 转为虚拟地址,然后将里面的字节拷贝到 buf 里面。
实现物理内存 VMO
用 HAL 实现 VmObjectPhysical 的方法,并做单元测试 物理内存 VMO 结构体:
#![allow(unused)] fn main() { pub struct VMObjectPhysical { paddr: PhysAddr, pages: usize, /// Lock this when access physical memory. data_lock: Mutex<()>, inner: Mutex<VMObjectPhysicalInner>, } struct VMObjectPhysicalInner { cache_policy: CachePolicy, } }
这里比较奇怪的是 data_lock 这个字段,这个字段里 Mutex 的泛型类型是一个 unit type,其实相当于它是没有“值”的,它只是起到一个锁的作用。
#![allow(unused)] fn main() { impl VMObjectTrait for VMObjectPhysical { fn read(&self, offset: usize, buf: &mut [u8]) -> ZxResult { let _ = self.data_lock.lock(); // 先获取锁 assert!(offset + buf.len() <= self.len()); kernel_hal::pmem_read(self.paddr + offset, buf); // 对一块物理内存进行读 Ok(()) } } }
实现切片 VMO
实现 VmObjectSlice,并做单元测试 VMObjectSlice 中的 parent 用于指向一个实际的 VMO 对象,比如:VMObjectPaged,这样通过 VMObjectSlice 就可以实现对 VMObjectPaged 的共享。
#![allow(unused)] fn main() { pub struct VMObjectSlice { /// Parent node. parent: Arc<dyn VMObjectTrait>, /// The offset from parent. offset: usize, /// The size in bytes. size: usize, } impl VMObjectSlice { pub fn new(parent: Arc<dyn VMObjectTrait>, offset: usize, size: usize) -> Arc<Self> { Arc::new(VMObjectSlice { parent, offset, size, }) } fn check_range(&self, offset: usize, len: usize) -> ZxResult { if offset + len >= self.size { return Err(ZxError::OUT_OF_RANGE); } Ok(()) } } }
VMObjectSlice 实现的读写,第一步是 check_range ,第二步是调用 parent 中的读写方法。
#![allow(unused)] fn main() { impl VMObjectTrait for VMObjectSlice { fn read(&self, offset: usize, buf: &mut [u8]) -> ZxResult { self.check_range(offset, buf.len())?; self.parent.read(offset + self.offset, buf) } } }
物理内存:按页分配的 VMO
简介
说明一下:Zircon 的官方实现中为了高效支持写时复制,使用了复杂精巧的树状数据结构,但它同时也引入了复杂性和各种 Bug。 我们在这里只实现一个简单版本,完整实现留给读者自行探索。
介绍 commit 操作的意义和作用
commit_page 和 commit_pages_with 函数的作用:用于检查物理页帧是否已经分配。
HAL:物理内存管理
在 HAL 中实现 PhysFrame 和最简单的分配器
kernel-hal
#![allow(unused)] fn main() { #[repr(C)] pub struct PhysFrame { // paddr 物理地址 paddr: PhysAddr, } impl PhysFrame { // 分配物理页帧 #[linkage = "weak"] #[export_name = "hal_frame_alloc"] pub fn alloc() -> Option<Self> { unimplemented!() } #[linkage = "weak"] #[export_name = "hal_frame_alloc_contiguous"] pub fn alloc_contiguous_base(_size: usize, _align_log2: usize) -> Option<PhysAddr> { unimplemented!() } pub fn alloc_contiguous(size: usize, align_log2: usize) -> Vec<Self> { PhysFrame::alloc_contiguous_base(size, align_log2).map_or(Vec::new(), |base| { (0..size) .map(|i| PhysFrame { paddr: base + i * PAGE_SIZE, }) .collect() }) } pub fn alloc_zeroed() -> Option<Self> { Self::alloc().map(|f| { pmem_zero(f.addr(), PAGE_SIZE); f }) } pub fn alloc_contiguous_zeroed(size: usize, align_log2: usize) -> Vec<Self> { PhysFrame::alloc_contiguous_base(size, align_log2).map_or(Vec::new(), |base| { pmem_zero(base, size * PAGE_SIZE); (0..size) .map(|i| PhysFrame { paddr: base + i * PAGE_SIZE, }) .collect() }) } pub fn addr(&self) -> PhysAddr { self.paddr } #[linkage = "weak"] #[export_name = "hal_zero_frame_paddr"] pub fn zero_frame_addr() -> PhysAddr { unimplemented!() } } impl Drop for PhysFrame { #[linkage = "weak"] #[export_name = "hal_frame_dealloc"] fn drop(&mut self) { unimplemented!() } } }
kernel-hal-unix
通过下面的代码可以构造一个页帧号。(PAGE_SIZE..PMEM_SIZE).step_by(PAGE_SIZE).collect() 可以每隔 PAGE_SIZE 生成一个页帧的开始位置。
#![allow(unused)] fn main() { lazy_static! { static ref AVAILABLE_FRAMES: Mutex<VecDeque<usize>> = Mutex::new((PAGE_SIZE..PMEM_SIZE).step_by(PAGE_SIZE).collect()); } }
分配一块物理页帧就是从 AVAILABLE_FRAMES 中通过 pop_front 弹出一个页号
#![allow(unused)] fn main() { impl PhysFrame { #[export_name = "hal_frame_alloc"] pub fn alloc() -> Option<Self> { let ret = AVAILABLE_FRAMES .lock() .unwrap() .pop_front() .map(|paddr| PhysFrame { paddr }); trace!("frame alloc: {:?}", ret); ret } #[export_name = "hal_zero_frame_paddr"] pub fn zero_frame_addr() -> PhysAddr { 0 } } impl Drop for PhysFrame { #[export_name = "hal_frame_dealloc"] fn drop(&mut self) { trace!("frame dealloc: {:?}", self); AVAILABLE_FRAMES.lock().unwrap().push_back(self.paddr); } } }
辅助结构:BlockRange 迭代器
实现 BlockRange
在按页分配内存的 VMObjectPaged 的读和写的方法中会使用到一个 BlockIter 迭代器。BlockIter 主要用于将一段内存分块,每次返回这一块的信息也就是 BlockRange。
BlockIter
#![allow(unused)] fn main() { #[derive(Debug, Eq, PartialEq)] pub struct BlockRange { pub block: usize, pub begin: usize, // 块内地址开始位置 pub end: usize, // 块内地址结束位置 pub block_size_log2: u8, } /// Given a range and iterate sub-range for each block pub struct BlockIter { pub begin: usize, pub end: usize, pub block_size_log2: u8, } }
block_size_log2 是 log 以2为底 block size, 比如:block size 大小为4096,则 block_size_log2 为 12。block 是块编号。
#![allow(unused)] fn main() { impl BlockRange { pub fn len(&self) -> usize { self.end - self.begin } pub fn is_full(&self) -> bool { self.len() == (1usize << self.block_size_log2) } pub fn is_empty(&self) -> bool { self.len() == 0 } pub fn origin_begin(&self) -> usize { (self.block << self.block_size_log2) + self.begin } pub fn origin_end(&self) -> usize { (self.block << self.block_size_log2) + self.end } } impl Iterator for BlockIter { type Item = BlockRange; fn next(&mut self) -> Option<<Self as Iterator>::Item> { if self.begin >= self.end { return None; } let block_size_log2 = self.block_size_log2; let block_size = 1usize << self.block_size_log2; let block = self.begin / block_size; let begin = self.begin % block_size; // 只有最后一块需要计算块内最后的地址,其他的直接返回块的大小 let end = if block == self.end / block_size { self.end % block_size } else { block_size }; self.begin += end - begin; Some(BlockRange { block, begin, end, block_size_log2, }) } } }
实现按页分配的 VMO
实现 for_each_page, commit, read, write 函数
按页分配的 VMO 结构体如下:
#![allow(unused)] fn main() { pub struct VMObjectPaged { inner: Mutex<VMObjectPagedInner>, } /// The mutable part of `VMObjectPaged`. #[derive(Default)] struct VMObjectPagedInner { /// Physical frames of this VMO. frames: Vec<PhysFrame>, /// Cache Policy cache_policy: CachePolicy, /// Is contiguous contiguous: bool, /// Sum of pin_count pin_count: usize, /// All mappings to this VMO. mappings: Vec<Weak<VmMapping>>, } }
VMObjectPage 有两个 new 方法
#![allow(unused)] fn main() { impl VMObjectPaged { /// Create a new VMO backing on physical memory allocated in pages. pub fn new(pages: usize) -> Arc<Self> { let mut frames = Vec::new(); frames.resize_with(pages, || PhysFrame::alloc_zeroed().unwrap()); // 分配 pages 个页帧号,并将这些页帧号的内存清零 Arc::new(VMObjectPaged { inner: Mutex::new(VMObjectPagedInner { frames, ..Default::default() }), }) } /// Create a list of contiguous pages pub fn new_contiguous(pages: usize, align_log2: usize) -> ZxResult<Arc<Self>> { let frames = PhysFrame::alloc_contiguous_zeroed(pages, align_log2 - PAGE_SIZE_LOG2); if frames.is_empty() { return Err(ZxError::NO_MEMORY); } Ok(Arc::new(VMObjectPaged { inner: Mutex::new(VMObjectPagedInner { frames, contiguous: true, ..Default::default() }), })) } } }
VMObjectPaged 的读和写用到了一个非常重要的函数 for_each_page 。首先它先构造了一个 BlockIter 迭代器,然后调用传入的函数进行读或者写。
#![allow(unused)] fn main() { impl VMObjectPagedInner { /// Helper function to split range into sub-ranges within pages. /// /// ```text /// VMO range: /// |----|----|----|----|----| /// /// buf: /// [====len====] /// |--offset--| /// /// sub-ranges: /// [===] /// [====] /// [==] /// ``` /// /// `f` is a function to process in-page ranges. /// It takes 2 arguments: /// * `paddr`: the start physical address of the in-page range. /// * `buf_range`: the range in view of the input buffer. fn for_each_page( &mut self, offset: usize, buf_len: usize, mut f: impl FnMut(PhysAddr, Range<usize>), ) { let iter = BlockIter { begin: offset, end: offset + buf_len, block_size_log2: 12, }; for block in iter { // 获取这一块开始的物理地址 let paddr = self.frames[block.block].addr(); // 这块物理地址的范围 let buf_range = block.origin_begin() - offset..block.origin_end() - offset; f(paddr + block.begin, buf_range); } } } }
read 和 write 函数,一个传入的是 kernel_hal::pmem_read ,另外一个是 kernel_hal::pmem_write
#![allow(unused)] fn main() { impl VMObjectTrait for VMObjectPaged { fn read(&self, offset: usize, buf: &mut [u8]) -> ZxResult { let mut inner = self.inner.lock(); if inner.cache_policy != CachePolicy::Cached { return Err(ZxError::BAD_STATE); } inner.for_each_page(offset, buf.len(), |paddr, buf_range| { kernel_hal::pmem_read(paddr, &mut buf[buf_range]); }); Ok(()) } fn write(&self, offset: usize, buf: &[u8]) -> ZxResult { let mut inner = self.inner.lock(); if inner.cache_policy != CachePolicy::Cached { return Err(ZxError::BAD_STATE); } inner.for_each_page(offset, buf.len(), |paddr, buf_range| { kernel_hal::pmem_write(paddr, &buf[buf_range]); }); Ok(()) } } }
commit 函数
#![allow(unused)] fn main() { impl VMObjectTrait for VMObjectPaged { fn commit_page(&self, page_idx: usize, _flags: MMUFlags) -> ZxResult<PhysAddr> { let inner = self.inner.lock(); Ok(inner.frames[page_idx].addr()) } fn commit_pages_with( &self, f: &mut dyn FnMut(&mut dyn FnMut(usize, MMUFlags) -> ZxResult<PhysAddr>) -> ZxResult, ) -> ZxResult { let inner = self.inner.lock(); f(&mut |page_idx, _| Ok(inner.frames[page_idx].addr())) } } }
VMO 复制
实现 create_child 函数
create_child 是将原 VMObjectPaged 的内容拷贝一份
#![allow(unused)] fn main() { // object/vm/vmo/paged.rs impl VMObjectTrait for VMObjectPaged { fn create_child(&self, offset: usize, len: usize) -> ZxResult<Arc<dyn VMObjectTrait>> { assert!(page_aligned(offset)); assert!(page_aligned(len)); let mut inner = self.inner.lock(); let child = inner.create_child(offset, len)?; Ok(child) } /// Create a snapshot child VMO. fn create_child(&mut self, offset: usize, len: usize) -> ZxResult<Arc<VMObjectPaged>> { // clone contiguous vmo is no longer permitted // https://fuchsia.googlesource.com/fuchsia/+/e6b4c6751bbdc9ed2795e81b8211ea294f139a45 if self.contiguous { return Err(ZxError::INVALID_ARGS); } if self.cache_policy != CachePolicy::Cached || self.pin_count != 0 { return Err(ZxError::BAD_STATE); } let mut frames = Vec::with_capacity(pages(len)); for _ in 0..pages(len) { frames.push(PhysFrame::alloc().ok_or(ZxError::NO_MEMORY)?); } for (i, frame) in frames.iter().enumerate() { if let Some(src_frame) = self.frames.get(pages(offset) + i) { kernel_hal::frame_copy(src_frame.addr(), frame.addr()) } else { kernel_hal::pmem_zero(frame.addr(), PAGE_SIZE); } } // create child VMO let child = Arc::new(VMObjectPaged { inner: Mutex::new(VMObjectPagedInner { frames, ..Default::default() }), }); Ok(child) } } // kernel-hal-unix/sr/lib.rs /// Copy content of `src` frame to `target` frame #[export_name = "hal_frame_copy"] pub fn frame_copy(src: PhysAddr, target: PhysAddr) { trace!("frame_copy: {:#x} <- {:#x}", target, src); assert!(src + PAGE_SIZE <= PMEM_SIZE && target + PAGE_SIZE <= PMEM_SIZE); ensure_mmap_pmem(); unsafe { let buf = phys_to_virt(src) as *const u8; buf.copy_to_nonoverlapping(phys_to_virt(target) as _, PAGE_SIZE); } } /// Zero physical memory at `[paddr, paddr + len)` #[export_name = "hal_pmem_zero"] pub fn pmem_zero(paddr: PhysAddr, len: usize) { trace!("pmem_zero: addr={:#x}, len={:#x}", paddr, len); assert!(paddr + len <= PMEM_SIZE); ensure_mmap_pmem(); unsafe { core::ptr::write_bytes(phys_to_virt(paddr) as *mut u8, 0, len); } } }
虚拟内存:VMAR 对象
VMAR 简介
虚拟内存地址区域(Virtual Memory Address Regions ,VMARs)为管理进程的地址空间提供了一种抽象。在进程创建时,将Root VMAR 的句柄提供给进程创建者。该句柄指的是跨越整个地址空间的 VMAR。这个空间可以通过zx_vmar_map()和 zx_vmar_allocate()接口来划分 。 zx_vmar_allocate()可用于生成新的 VMAR(称为子区域或子区域),可用于将地址空间的各个部分组合在一起。
实现 VMAR 对象框架
定义 VmAddressRange,VmMapping
实现 create_child, map, unmap, destroy 函数,并做单元测试验证地址空间分配
VmAddressRegion
#![allow(unused)] fn main() { pub struct VmAddressRegion { flags: VmarFlags, base: KObjectBase, addr: VirtAddr, size: usize, parent: Option<Arc<VmAddressRegion>>, page_table: Arc<Mutex<dyn PageTableTrait>>, /// If inner is None, this region is destroyed, all operations are invalid. inner: Mutex<Option<VmarInner>>, } #[derive(Default)] struct VmarInner { children: Vec<Arc<VmAddressRegion>>, mappings: Vec<Arc<VmMapping>>, } }
构造一个根节点 VMAR,这个 VMAR 是每个进程都拥有的。
#![allow(unused)] fn main() { impl VmAddressRegion { /// Create a new root VMAR. pub fn new_root() -> Arc<Self> { let (addr, size) = { use core::sync::atomic::*; static VMAR_ID: AtomicUsize = AtomicUsize::new(0); let i = VMAR_ID.fetch_add(1, Ordering::SeqCst); (0x2_0000_0000 + 0x100_0000_0000 * i, 0x100_0000_0000) }; Arc::new(VmAddressRegion { flags: VmarFlags::ROOT_FLAGS, base: KObjectBase::new(), addr, size, parent: None, page_table: Arc::new(Mutex::new(kernel_hal::PageTable::new())), //hal PageTable inner: Mutex::new(Some(VmarInner::default())), }) } } }
我们的内核同样需要一个根 VMAR
#![allow(unused)] fn main() { /// The base of kernel address space /// In x86 fuchsia this is 0xffff_ff80_0000_0000 instead pub const KERNEL_ASPACE_BASE: u64 = 0xffff_ff02_0000_0000; /// The size of kernel address space pub const KERNEL_ASPACE_SIZE: u64 = 0x0000_0080_0000_0000; /// The base of user address space pub const USER_ASPACE_BASE: u64 = 0; // pub const USER_ASPACE_BASE: u64 = 0x0000_0000_0100_0000; /// The size of user address space pub const USER_ASPACE_SIZE: u64 = (1u64 << 47) - 4096 - USER_ASPACE_BASE; impl VmAddressRegion { /// Create a kernel root VMAR. pub fn new_kernel() -> Arc<Self> { let kernel_vmar_base = KERNEL_ASPACE_BASE as usize; let kernel_vmar_size = KERNEL_ASPACE_SIZE as usize; Arc::new(VmAddressRegion { flags: VmarFlags::ROOT_FLAGS, base: KObjectBase::new(), addr: kernel_vmar_base, size: kernel_vmar_size, parent: None, page_table: Arc::new(Mutex::new(kernel_hal::PageTable::new())), inner: Mutex::new(Some(VmarInner::default())), }) } } }
VmAddressMapping
VmAddressMapping 用于建立 VMO 和 VMAR 之间的映射。
#![allow(unused)] fn main() { /// Virtual Memory Mapping pub struct VmMapping { /// The permission limitation of the vmar permissions: MMUFlags, vmo: Arc<VmObject>, page_table: Arc<Mutex<dyn PageTableTrait>>, inner: Mutex<VmMappingInner>, } #[derive(Debug, Clone)] struct VmMappingInner { /// The actual flags used in the mapping of each page flags: Vec<MMUFlags>, addr: VirtAddr, size: usize, vmo_offset: usize, } }
map 和 unmap 实现内存映射和解映射
#![allow(unused)] fn main() { impl VmMapping { /// Map range and commit. /// Commit pages to vmo, and map those to frames in page_table. /// Temporarily used for development. A standard procedure for /// vmo is: create_vmo, op_range(commit), map fn map(self: &Arc<Self>) -> ZxResult { self.vmo.commit_pages_with(&mut |commit| { let inner = self.inner.lock(); let mut page_table = self.page_table.lock(); let page_num = inner.size / PAGE_SIZE; let vmo_offset = inner.vmo_offset / PAGE_SIZE; for i in 0..page_num { let paddr = commit(vmo_offset + i, inner.flags[i])?; //通过 PageTableTrait 的 hal_pt_map 进行页表映射 //调用 kernel-hal的方法进行映射 } Ok(()) }) } fn unmap(&self) { let inner = self.inner.lock(); let pages = inner.size / PAGE_SIZE; // TODO inner.vmo_offset unused? // 调用 kernel-hal的方法进行解映射 } } }
HAL:用 mmap 模拟页表
实现页表接口 map, unmap, protect
在 kernel-hal 中定义了一个页表和这个页表具有的方法。
#![allow(unused)] fn main() { /// Page Table #[repr(C)] pub struct PageTable { table_phys: PhysAddr, } impl PageTable { /// Get current page table #[linkage = "weak"] #[export_name = "hal_pt_current"] pub fn current() -> Self { unimplemented!() } /// Create a new `PageTable`. #[allow(clippy::new_without_default)] #[linkage = "weak"] #[export_name = "hal_pt_new"] pub fn new() -> Self { unimplemented!() } } impl PageTableTrait for PageTable { /// Map the page of `vaddr` to the frame of `paddr` with `flags`. #[linkage = "weak"] #[export_name = "hal_pt_map"] fn map(&mut self, _vaddr: VirtAddr, _paddr: PhysAddr, _flags: MMUFlags) -> Result<()> { unimplemented!() } /// Unmap the page of `vaddr`. #[linkage = "weak"] #[export_name = "hal_pt_unmap"] fn unmap(&mut self, _vaddr: VirtAddr) -> Result<()> { unimplemented!() } /// Change the `flags` of the page of `vaddr`. #[linkage = "weak"] #[export_name = "hal_pt_protect"] fn protect(&mut self, _vaddr: VirtAddr, _flags: MMUFlags) -> Result<()> { unimplemented!() } /// Query the physical address which the page of `vaddr` maps to. #[linkage = "weak"] #[export_name = "hal_pt_query"] fn query(&mut self, _vaddr: VirtAddr) -> Result<PhysAddr> { unimplemented!() } /// Get the physical address of root page table. #[linkage = "weak"] #[export_name = "hal_pt_table_phys"] fn table_phys(&self) -> PhysAddr { self.table_phys } /// Activate this page table #[cfg(target_arch = "riscv64")] #[linkage = "weak"] #[export_name = "hal_pt_activate"] fn activate(&self) { unimplemented!() } #[linkage = "weak"] #[export_name = "hal_pt_unmap_cont"] fn unmap_cont(&mut self, vaddr: VirtAddr, pages: usize) -> Result<()> { for i in 0..pages { self.unmap(vaddr + i * PAGE_SIZE)?; } Ok(()) } } }
在 kernel-hal-unix 中实现了 PageTableTrait,在 map 中调用了 mmap。
#![allow(unused)] fn main() { impl PageTableTrait for PageTable { /// Map the page of `vaddr` to the frame of `paddr` with `flags`. #[export_name = "hal_pt_map"] fn map(&mut self, vaddr: VirtAddr, paddr: PhysAddr, flags: MMUFlags) -> Result<()> { debug_assert!(page_aligned(vaddr)); debug_assert!(page_aligned(paddr)); let prot = flags.to_mmap_prot(); mmap(FRAME_FILE.as_raw_fd(), paddr, PAGE_SIZE, vaddr, prot); Ok(()) } /// Unmap the page of `vaddr`. #[export_name = "hal_pt_unmap"] fn unmap(&mut self, vaddr: VirtAddr) -> Result<()> { self.unmap_cont(vaddr, 1) } } }
实现内存映射
用 HAL 实现上面 VMAR 留空的部分,并做单元测试验证内存映射
#![allow(unused)] fn main() { impl VmMapping { /// Map range and commit. /// Commit pages to vmo, and map those to frames in page_table. /// Temporarily used for development. A standard procedure for /// vmo is: create_vmo, op_range(commit), map fn map(self: &Arc<Self>) -> ZxResult { self.vmo.commit_pages_with(&mut |commit| { let inner = self.inner.lock(); let mut page_table = self.page_table.lock(); let page_num = inner.size / PAGE_SIZE; let vmo_offset = inner.vmo_offset / PAGE_SIZE; for i in 0..page_num { let paddr = commit(vmo_offset + i, inner.flags[i])?; //通过 PageTableTrait 的 hal_pt_map 进行页表映射 page_table .map(inner.addr + i * PAGE_SIZE, paddr, inner.flags[i]) .expect("failed to map"); } Ok(()) }) } fn unmap(&self) { let inner = self.inner.lock(); let pages = inner.size / PAGE_SIZE; // TODO inner.vmo_offset unused? self.page_table .lock() .unmap_cont(inner.addr, pages) .expect("failed to unmap") } } }
用户程序
zCore采用的是微内核的设计风格。微内核设计的一个复杂问题是”如何引导初始用户空间进程“。通常这是通过让内核实现最小版本的文件系统读取和程序加载来实现的引导。
Zircon 用户程序
用户态启动流程
流程概要
kernel
-> userboot (decompress bootsvc LZ4 format)
-> bootsvc (可执行文件bin/component_manager)
-> component_manager
-> sh / device_manager
ZBI(Zircon Boot Image)
ZBI是一种简单的容器格式,它内嵌了许多可由引导加载程序 BootLoader传递的项目内容,包括硬件特定的信息、提供引导选项的内核“命令行”以及RAM磁盘映像(通常是被压缩的)。ZBI中包含了初始文件系统 bootfs,内核将 ZBI 完整传递给 userboot,由它负责解析并对其它进程提供文件服务。
bootfs
基本的bootfs映像可满足用户空间程序运行需要的所有依赖:
+ 可执行文件
+ 共享库
+ 数据文件
以上列出的内容还可实现设备驱动或更高级的文件系统,从而能够从存储设备或网络设备上访问读取更多的代码和数据。
在系统自引导结束后,bootfs中的文件就会成为一个挂载在根目录/boot上的只读文件系统树(并由bootsvc提供服务)。随后userboot将从bootfs加载第一个真正意义上的用户程序。
zCore程序(ELF加载与动态链接)
zCore内核不直接参与正常程序的加载,而是提供了一些用户态程序加载时可用的模块。如虚拟内存对象(VMO)、进程(processes)、虚拟地址空间(VMAR)和线程(threads)。
ELF 格式以及系统应用程序二进制接口(system ABI)
标准的zCore用户空间环境提供了动态链接器以及基于ELF的执行环境,能够运行ELF格式的格式机器码可执行文件。zCore进程只能通过zCore vDSO使用系统调用。内核采用基于ELF系统常见的程序二进制接口(ABI)提供了vDSO。
具备适当功能的用户空间代码可通过系统调用直接创建进程和加载程序,而不用ELF。但是zCore的标准ABI使用了这里所述的ELF。有关ELF文件格式的背景知识如下:
ELF文件类型
“ET_REL”代表此ELF文件为可重定位文件
“ET_EXEC“代表ELF文件为可执行文件
“ET_DYN”代表此ELF文件为动态链接库
“ET_CORE”代表此ELF文件是核心转储文件
传统ELF程序文件加载
可执行链接格式(Executable and Linking Format, ELF)最初由 UNIX 系统实验室开发并发布,并成为大多数类Unix系统的通用标准可执行文件格式。在这些系统中,内核使用POSIX(可移植操作系统接口)execve API将程序加载与文件系统访问集成在一起。该类系统加载ELF程序的方式会有一些不同,但大多遵循以下模式:
-
内核按照名称加载文件,并检查它是ELF还是系统支持的其他类型的文件。
-
内核根据ELF文件的
PT_LOAD程序头来映射ELF映像。对于ET_EXEC文件,系统会将程序中的各段(Section)放到p_vaddr中所指定内存中的固定地址。对于ET_DYN文件,系统将加载程序第一个PT_LOAD的基地址,然后根据它们的p_vaddr相对于第一个section的p_vaddr放置后面的section。 通常来说该基地址是通过地址随机化(ASLR)来产生的。 -
若ELF文件中有一个
PT_INTERP(Program interpreter)程序头, 它的部分内容(ELF文件中p_offset和p_filesz给出的一些字节)被当做为一个文件名,改文件名用于寻找另一个称为“ELF解释器”的ELF文件。上述这种ELF文件是ET_DYN文件。内核采用同样的方式将该类ELF文件加载,但是所加载的地址是自定的。该ELF“解释器”通常指的是被命名为/lib/ld.so.1或者是/lib/ld-linux.so.2的ELF动态链接器。 -
内核为初始的线程设置了寄存器和堆栈的内容,并在PC寄存器已指向特定程序入口处(Entry Point)的情况下启动线程。
- 程序入口处(Entry Point)指的是ELF文件头中
e_entry的值,它会根据程序基地址(base address)做相应的调整。如果这是一个带有PT_INTERP的ELF文件,则它的入口点不在它本身,而是被设置在动态链接器中。 - 内核通过设置寄存器和堆栈来使得程序能够接收特定的参数,环境变量以及其它有实际用途的辅助向量。寄存器和堆栈的设置方法遵循了一种汇编级别的协议方式。若ELF文件运行时依赖动态链接,即带有
PT_INTERP。则寄存器和堆栈中将包括来自该可执行文件的ELF文件头中的基地址、入口点和程序头部表地址信息,这些信息可允许动态链接器在内存中找到该可执行文件的ELF动态链接元数据,以实现动态链接。当动态链接启动完成后,动态链接器将跳转到该可执行文件的入口点地址。
#![allow(unused)] fn main() { pub fn sys_process_start( &self, proc_handle: HandleValue, thread_handle: HandleValue, entry: usize, stack: usize, arg1_handle: HandleValue, arg2: usize, ) -> ZxResult { info!("process.start: proc_handle={:?}, thread_handle={:?}, entry={:?}, stack={:?}, arg1_handle={:?}, arg2={:?}", proc_handle, thread_handle, entry, stack, arg1_handle, arg2 ); let proc = self.thread.proc(); let process = proc.get_object_with_rights::<Process>(proc_handle, Rights::WRITE)?; let thread = proc.get_object_with_rights::<Thread>(thread_handle, Rights::WRITE)?; if !Arc::ptr_eq(&thread.proc(), &process) { return Err(ZxError::ACCESS_DENIED); } let arg1 = if arg1_handle != INVALID_HANDLE { let arg1 = proc.remove_handle(arg1_handle)?; if !arg1.rights.contains(Rights::TRANSFER) { return Err(ZxError::ACCESS_DENIED); } Some(arg1) } else { None }; process.start(&thread, entry, stack, arg1, arg2, self.spawn_fn)?; Ok(()) } } - 程序入口处(Entry Point)指的是ELF文件头中
zCore的程序加载受到了传统方式的启发,但是有一些不同。在传统模式中,需要在加载动态链接器之前加载可执行文件的一个关键原因是,动态链接器随机化选择的基地址(base address)不能与ET_EXEC可执行文件使用的固定地址相交。zCore从根本上并不支持ET_EXEC格式ELF文件的固定地址程序加载,它只支持位置无关的可执行文件或PIE(ET_DYN格式的ELF文件)
VmarExt trait实现
zCore底层的API不支持文件系统。zCore程序文件的加载通过虚拟内存对象(VMO)以及channel使用的进程间通信机制来完成。
程序的加载基于如下一些前提: + 获得一个包含可执行文件的虚拟内存对象(VMO)的句柄。
zircon-object\src\util\elf_loader.rs
fn make_vmo(elf: &ElfFile, ph: ProgramHeader) -> ZxResult<Arc<VmObject>> {
assert_eq!(ph.get_type().unwrap(), Type::Load);
let page_offset = ph.virtual_addr() as usize % PAGE_SIZE;
let pages = pages(ph.mem_size() as usize + page_offset);
let vmo = VmObject::new_paged(pages);
let data = match ph.get_data(&elf).unwrap() {
SegmentData::Undefined(data) => data,
_ => return Err(ZxError::INVALID_ARGS),
};
vmo.write(page_offset, data)?;
Ok(vmo)
}
- 程序执行参数列表。
- 程序执行环境变量列表。
- 存在一个初始的句柄列表,每个句柄都有一个句柄信息项。
USERBOOT
使用userboot的原因
在Zircon中,内嵌在ZBI中的RAM磁盘映像通常采用LZ4格式压缩。解压后将继续得到bootfs格式的磁盘镜像。这是一种简单的只读文件系统格式,它只列出文件名。且对于每个文件,可分别列出它们在BOOTFS映像中的偏移量和大小(这两个值都必须是页面对齐的,并且限制在32位)。
由于kernel中没有包含任何可用于解压缩LZ4格式的代码,也没有任何用于解析BOOTFS格式的代码。所有这些工作都是由称为userboot的第一个用户空间进程完成的。
zCore中未找到解压缩bootfs的相关实现,
但是能够在scripts/gen-prebuilt.sh中找到ZBI中确实有bootfs的内容
且现有的zCore实现中有关所载入的ZBI方式如下:
zircon-loader/src/lib.rs
#![allow(unused)] fn main() { // zbi let zbi_vmo = { let vmo = VmObject::new_paged(images.zbi.as_ref().len() / PAGE_SIZE + 1); vmo.write(0, images.zbi.as_ref()).unwrap(); vmo.set_name("zbi"); vmo }; }
userboot是什么
userboot是一个普通的用户空间进程。它只能像任何其他进程一样通过vDSO执行标准的系统调用,并受完整vDSO执行制度的约束。
唯一一个由内核态“不规范地”创建的用户进程
userboot具体实现的功能有:
读取channel中的cmdline、handles
解析zbi
解压BOOTFS
选定下一个程序启动 自己充当loader,然后“死亡”
用“规范的方式”启动下一个程序
userboot被构建为一个ELF动态共享对象(DSO,dynamic shared object),使用了与vDSO相同的布局。与vDSO一样,userboot的ELF映像在编译时就被嵌入到内核中。其简单的布局意味着加载它不需要内核在引导时解析ELF的文件头。内核只需要知道三件事:
- 只读段
segment的大小 - 可执行段
segment的大小 userboot入口点的地址。
这些值在编译时便可从userboot ELF映像中提取,并在内核代码中用作常量。
kernel如何启用userboot
与任何其他进程一样,userboot必须从已经映射到其地址空间的vDSO开始,这样它才能进行系统调用。内核将userboot和vDSO映射到第一个用户进程,然后在userboot的入口处启动它。
userboot如何在vDSO中取得系统调用
当内核将userboot映射到第一个用户进程时,会像正常程序那样,在内存中选择一个随机地址进行加载。而在映射userboot的vDSO时,并不采用上述随机的方式,而是将vDSO映像直接放在内存中userboot的映像之后。这样一来,vDSO代码与userboot的偏移量总是固定的。
在编译阶段中,系统调用的入口点符号表会从vDSO ELF映像中提取出来,随后写入到链接脚本的符号定义中。利用每个符号在vDSO映像中相对固定的偏移地址,可在链接脚本提供的_end符号的固定偏移量处,定义该符号。通过这种方式,userboot代码可以直接调用到放在内存中,其映像本身之后的,每个确切位置上的vDSO入口点。
相关代码:
zircon-loader/src/lib.rs
#![allow(unused)] fn main() { pub fn run_userboot(images: &Images<impl AsRef<[u8]>>, cmdline: &str) -> Arc<Process> { ... // vdso let vdso_vmo = { let elf = ElfFile::new(images.vdso.as_ref()).unwrap(); let vdso_vmo = VmObject::new_paged(images.vdso.as_ref().len() / PAGE_SIZE + 1); vdso_vmo.write(0, images.vdso.as_ref()).unwrap(); let size = elf.load_segment_size(); let vmar = vmar .allocate_at( userboot_size, size, VmarFlags::CAN_MAP_RXW | VmarFlags::SPECIFIC, PAGE_SIZE, ) .unwrap(); vmar.map_from_elf(&elf, vdso_vmo.clone()).unwrap(); #[cfg(feature = "std")] { let offset = elf .get_symbol_address("zcore_syscall_entry") .expect("failed to locate syscall entry") as usize; let syscall_entry = &(kernel_hal_unix::syscall_entry as usize).to_ne_bytes(); // fill syscall entry x3 vdso_vmo.write(offset, syscall_entry).unwrap(); vdso_vmo.write(offset + 8, syscall_entry).unwrap(); vdso_vmo.write(offset + 16, syscall_entry).unwrap(); } vdso_vmo }; ... } }
bootsvc
bootsvc 通常是usermode加载的第一个程序(与userboot不同,userboot是由内核加载的)。bootsvc提供了几种系统服务:
-
包含bootfs(/boot)内容的文件系统服务(初始的bootfs映像包含用户空间系统需要运行的所有内容:
- 可执行文件
- 共享库和数据文件(包括设备驱动程序或更高级的文件系统的实现)
-
从bootfs加载的加载程序服务
-
bin/component_manager
-
sh / device_manager
用户程序的组成
内核不直接参与用户程序的加载工作(第一个进程除外)
用户程序强制使用 PIC 和 PIE(位置无关代码)
内存地址空间组成:Program, Stack, vDSO, Dylibs
通过 Channel 传递启动信息和句柄
系统调用的跳板:vDSO
介绍 vDSO 的作用
vDSO(virtual Dynamic Shared Object),Zircon vDSO 是 Zircon 内核访问系统调用的唯一方法(作为系统调用的跳板)。它之所以是虚拟的,是因为它不是从文件系统中的ELF文件加载的,而是由内核直接提供的vDSO镜像。
zCore/src/main.rs
#[cfg(feature = "zircon")] fn main(ramfs_data: &[u8], cmdline: &str) { use zircon_loader::{run_userboot, Images}; let images = Images::<&[u8]> { userboot: include_bytes!("../../prebuilt/zircon/x64/userboot.so"), vdso: include_bytes!("../../prebuilt/zircon/x64/libzircon.so"), zbi: ramfs_data, }; let _proc = run_userboot(&images, cmdline); run(); }
它是一个用户态运行的代码,被封装成prebuilt/zircon/x64/libzircon.so文件。这个.so 文件装载不是放在文件系统中,而是由内核提供。它被整合在内核image中。
vDSO映像在编译时嵌入到内核中。内核将它作为只读VMO公开给用户空间。内核启动时,会通过计算得到它所在的物理页。当program loader设置了一个新进程后,使该进程能够进行系统调用的唯一方法是:program loader在新进程的第一个线程开始运行之前,将vDSO映射到新进程的虚拟地址空间(地址随机)。因此,在启动其他能够进行系统调用的进程的每个进程自己本身都必须能够访问vDSO的VMO。
zircon-loader/src/lib.rs#line167
#![allow(unused)] fn main() { proc.start(&thread, entry, sp, Some(handle), 0, thread_fn) .expect("failed to start main thread"); proc }
zircon-object/src/task/process.rs#line189
#![allow(unused)] fn main() { thread.start(entry, stack, handle_value as usize, arg2, thread_fn) }
vDSO被映射到新进程的同时会将映像的base address通过arg2参数传递给新进程中的第一个线程。通过这个地址,可以在内存中找到ELF的文件头,该文件头指向可用于查找系统调用符号名的其他ELF程序模块。
如何修改 vDSO 源码(libzircon)将 syscall 改为函数调用
有关代码
- 参考仓库README.MD
···解析代码依赖的compile_commands.json将会随build过程生成到out文件夹···
如何生成imgs(VDSO,ZBI)
-
clone Zircon代码仓库(从fuchsia官方目录中分离出来的zircon代码):
$ git clone https://github.com/PanQL/zircon.git -
关于Zircon的编译运行
为了减小仓库体积,我们将prebuilt目录进行了大幅调整;因此运行之前请下载google预编译好的clang,解压后放到某个权限合适的位置,然后在代码的这个位置将绝对目录修改为对应位置。 clang下载链接: -
当前只支持在Mac OS及Linux x64上进行编译。
默认的make run和make build是针对x64架构的,如果希望编译运行arm架构的zircon,那么需要:- 修改out/args.gn中的
legacy-image-x64为legacy-image-arm64 - 重新
make build make runarm
- 修改out/args.gn中的
-
配合zCore中的有关脚本与补丁文件
- scripts/gen-prebuilt.sh
- scripts/zircon-libos.patch
- https://github.com/PanQL/zircon/blob/master/system/ulib/zircon/syscall-entry.h
- https://github.com/PanQL/zircon/blob/master/system/ulib/zircon/syscalls-x86-64.S
- zircon-loader/src/lib.rs#line 83-93
#![allow(unused)] fn main() { #[cfg(feature = "std")] { let offset = elf .get_symbol_address("zcore_syscall_entry") .expect("failed to locate syscall entry") as usize; let syscall_entry = &(kernel_hal_unix::syscall_entry as usize).to_ne_bytes(); // fill syscall entry x3 vdso_vmo.write(offset, syscall_entry).unwrap(); vdso_vmo.write(offset + 8, syscall_entry).unwrap(); vdso_vmo.write(offset + 16, syscall_entry).unwrap(); } }
加载 vDSO 时修改 vDSO 代码段,填入跳转地址
第一个用户程序:userboot
实现 zircon-loader 中的 run_userboot 函数
能够进入用户态并在第一个系统调用时跳转回来
从bootfs加载第一个真正意义上的用户程序。
主要相关代码:
zircon-loader/src/lib.rs zircon-object/src/util/elf_loader.rs
当userboot解压完毕ZBI中的bootfs后,userboot将继续从bootfs载入程序文件运行。
Zircon中具体的实现流程如下:
-
userboot检查从内核接收到的环境字符串,这些字符串代表了一定的内核命令行。zircon-loader/src/main.rs
#[async_std::main] async fn main() { kernel_hal_unix::init(); init_logger(); let opt = Opt::from_args(); let images = open_images(&opt.prebuilt_path).expect("failed to read file"); let proc: Arc<dyn KernelObject> = run_userboot(&images, &opt.cmdline); drop(images); proc.wait_signal(Signal::USER_SIGNAL_0).await; }在Zircon中:
- 若该字符串内容为
userboot=file,那么该file将作为第一个真正的用户进程加载。 - 若没有这样的选项,则
userboot将选择的默认文为bin/bootsvc。该文件可在bootfs中找到。
而在zCore的实现中:
- ..
- 若该字符串内容为
-
为了加载上述文件,userboot实现了一个功能齐全的ELF程序加载器
zircon_object::util::elf_loader::load_from_elf#![allow(unused)] fn main() { // userboot let (entry, userboot_size) = { let elf = ElfFile::new(images.userboot.as_ref()).unwrap(); let size = elf.load_segment_size(); let vmar = vmar .allocate(None, size, VmarFlags::CAN_MAP_RXW, PAGE_SIZE) .unwrap(); vmar.load_from_elf(&elf).unwrap(); (vmar.addr() + elf.header.pt2.entry_point() as usize, size) }; } -
然后userboot以随机地址加载vDSO。它使用标准约定启动新进程,并给它传递一个channel句柄和vDSO基址。
zircon_object::util::elf_loader::map_from_elf
上下文切换
本节介绍 trapframe-rs 中 fncall.rs 的魔法实现
保存和恢复通用寄存器
定义 UserContext 结构体
#![allow(unused)] fn main() { pub struct UserContext { pub general: GeneralRegs, pub trap_num: usize, pub error_code: usize, } }
#![allow(unused)] fn main() { pub struct GeneralRegs { pub rax: usize, pub rbx: usize, pub rcx: usize, pub rdx: usize, pub rsi: usize, pub rdi: usize, pub rbp: usize, pub rsp: usize, pub r8: usize, pub r9: usize, pub r10: usize, pub r11: usize, pub r12: usize, pub r13: usize, pub r14: usize, pub r15: usize, pub rip: usize, pub rflags: usize, pub fsbase: usize, pub gsbase: usize, } }
Usercontext保存了用户执行的上下文,包括跳转到用户态之后程序的第一条指令的地址,如果程序首次从内核态进入用户态执行,则rip指向用户进程的第一条指令的地址。
保存 callee-saved 寄存器到栈上,恢复 UserContext 寄存器,进入用户态,反之亦然
#![allow(unused)] fn main() { syscall_fn_return: save callee-saved registers push r15 push r14 push r13 push r12 push rbp push rbx push rdi SAVE_KERNEL_STACK mov rsp, rdi POP_USER_FSBASE pop trap frame (struct GeneralRegs) pop rax pop rbx pop rcx pop rdx pop rsi pop rdi pop rbp pop r8 # skip rsp pop r8 pop r9 pop r10 pop r11 pop r12 pop r13 pop r14 pop r15 pop r11 # r11 = rip. FIXME: don't overwrite r11! popfq # pop rflags mov rsp, [rsp - 8*11] # restore rsp jmp r11 # restore rip }
弹出的寄存器恰好对应了GeneralRegs的结构,通过在rust的unsafe代码块中调用syscall_fn_return函数,并且传递Usercontext结构体的指针到rdi中,可以创造出程序进入用户态的运行环境。
找回内核上下文:线程局部存储 与 FS 寄存器
在用户程序跳转回内核代码的那一刻,如何在不破坏用户寄存器的情况下切换回内核栈?
进入用户态前,将内核栈指针保存在内核 glibc 的 TLS 区域中。为此我们需要查看 glibc 源码,找到一个空闲位置。
Linux 和 macOS 下如何分别通过系统调用设置 fsbase / gsbase
测试
编写单元测试验证上述过程
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use crate::*; #[cfg(target_os = "macos")] global_asm!(".set _dump_registers, dump_registers"); // Mock user program to dump registers at stack. global_asm!( r#" dump_registers: push r15 push r14 push r13 push r12 push r11 push r10 push r9 push r8 push rsp push rbp push rdi push rsi push rdx push rcx push rbx push rax add rax, 10 add rbx, 10 add rcx, 10 add rdx, 10 add rsi, 10 add rdi, 10 add rbp, 10 add r8, 10 add r9, 10 add r10, 10 add r11, 10 add r12, 10 add r13, 10 add r14, 10 add r15, 10 call syscall_fn_entry "# ); #[test] fn run_fncall() { extern "sysv64" { fn dump_registers(); } let mut stack = [0u8; 0x1000]; let mut cx = UserContext { general: GeneralRegs { rax: 0, rbx: 1, rcx: 2, rdx: 3, rsi: 4, rdi: 5, rbp: 6, rsp: stack.as_mut_ptr() as usize + 0x1000, r8: 8, r9: 9, r10: 10, r11: 11, r12: 12, r13: 13, r14: 14, r15: 15, rip: dump_registers as usize, rflags: 0, fsbase: 0, // don't set to non-zero garbage value gsbase: 0, }, trap_num: 0, error_code: 0, }; cx.run_fncall(); // check restored registers let general = unsafe { *(cx.general.rsp as *const GeneralRegs) }; assert_eq!( general, GeneralRegs { rax: 0, rbx: 1, rcx: 2, rdx: 3, rsi: 4, rdi: 5, rbp: 6, // skip rsp r8: 8, r9: 9, r10: 10, // skip r11 r12: 12, r13: 13, r14: 14, r15: 15, ..general } ); // check saved registers assert_eq!( cx.general, GeneralRegs { rax: 10, rbx: 11, rcx: 12, rdx: 13, rsi: 14, rdi: 15, rbp: 16, // skip rsp r8: 18, r9: 19, r10: 20, // skip r11 r12: 22, r13: 23, r14: 24, r15: 25, ..cx.general } ); assert_eq!(cx.trap_num, 0x100); assert_eq!(cx.error_code, 0); } } }
macOS 的麻烦:动态二进制修改
由于 macOS 用户程序无法修改 fs 寄存器,当运行相关指令时会访问非法内存地址触发段错误。
我们需要实现段错误信号处理函数,并在其中动态修改用户程序指令,将 fs 改为 gs。
Zircon 系统调用
目录位于
zCore/zircon-syscall
从userboot运行起来到实现调用syscall的简要函数调用流程如下:
- run_userboot ->
- proc.start ->
- thread_fn ->
- new_thread ->
- handle_syscall ->
- syscall ->
- sys_handle_close() (举例某一具体的syscall运行,该syscall可用于实现
close a handle的功能)
获取系统调用参数
从寄存器中获取参数
不同的计算机体系结构获得参数的方式不同
以下区分
x86_64以及aarch64
调用syscall需要从寄存器收集两种参数:
+ num : 系统调用号
+ args : 具体某一系统调用的参数
#![allow(unused)] fn main() { async fn handle_syscall(thread: &CurrentThread, regs: &mut GeneralRegs) { #[cfg(target_arch = "x86_64")] let num = regs.rax as u32; #[cfg(target_arch = "aarch64")] let num = regs.x16 as u32; // LibOS: Function call ABI #[cfg(feature = "std")] #[cfg(target_arch = "x86_64")] let args = unsafe { let a6 = (regs.rsp as *const usize).read(); let a7 = (regs.rsp as *const usize).add(1).read(); [ regs.rdi, regs.rsi, regs.rdx, regs.rcx, regs.r8, regs.r9, a6, a7, ] }; // RealOS: Zircon syscall ABI #[cfg(not(feature = "std"))] #[cfg(target_arch = "x86_64")] let args = [ regs.rdi, regs.rsi, regs.rdx, regs.r10, regs.r8, regs.r9, regs.r12, regs.r13, ]; // ARM64 #[cfg(target_arch = "aarch64")] let args = [ regs.x0, regs.x1, regs.x2, regs.x3, regs.x4, regs.x5, regs.x6, regs.x7, ]; let mut syscall = Syscall { regs, thread, thread_fn, }; let ret = syscall.syscall(num, args).await as usize; #[cfg(target_arch = "x86_64")] { syscall.regs.rax = ret; } #[cfg(target_arch = "aarch64")] { syscall.regs.x0 = ret; } } }
系统调用上下文与处理函数
定义 Syscall 结构体
保存上下文信息
zCore/zircon-syscall/src/lib.rs#L52
#![allow(unused)] fn main() { /// 系统调用的结构(存储关于创建系统调用的信息) pub struct Syscall<'a> { /// store the regs statues pub regs: &'a mut GeneralRegs, /// the thread making a syscall pub thread: &'a CurrentThread, /// new thread function pub thread_fn: ThreadFn, } }
实现 syscall 函数
zCore/zircon-syscall/src/lib.rs#L59
- 检查系统调用号
sys_type是否合法 - 获取传递给具体某一系统调用的参数
args - 若syscall函数输入的系统调用号合法,则进一步根据系统调用号匹配具体系统调用处理函数
- 传入对应系统调用所需的参数,并运行之
- 检查系统调用的返回值
ret是否符合预期
#![allow(unused)] fn main() { pub async fn syscall(&mut self, num: u32, args: [usize; 8]) -> isize { ... // 1. 检查系统调用号`sys_type`是否合法 let sys_type = match Sys::try_from(num) { Ok(t) => t, Err(_) => { error!("invalid syscall number: {}", num); return ZxError::INVALID_ARGS as _; } }; ... // 2. 获取传递给具体系统调用参数 let [a0, a1, a2, a3, a4, a5, a6, a7] = args; // 3. 若syscall函数输入的系统调用号合法 // 则进一步根据系统调用号匹配具体系统调用处理函数 let ret = match sys_type { // 4. 传入对应系统调用所需的参数,并运行之 Sys::HANDLE_CLOSE => self.sys_handle_close(a0 as _), Sys::HANDLE_CLOSE_MANY => self.sys_handle_close_many(a0.into(), a1 as _), Sys::HANDLE_DUPLICATE => self.sys_handle_duplicate(a0 as _, a1 as _, a2.into()), Sys::HANDLE_REPLACE => self.sys_handle_replace(a0 as _, a1 as _, a2.into()), ... // 更多系统调用匹配的分支 Sys::CLOCK_GET => self.sys_clock_get(a0 as _, a1.into()), Sys::CLOCK_READ => self.sys_clock_read(a0 as _, a1.into()), Sys::CLOCK_ADJUST => self.sys_clock_adjust(a0 as _, a1 as _, a2 as _), Sys::CLOCK_UPDATE => self.sys_clock_update(a0 as _, a1 as _, a2.into()), Sys::TIMER_CREATE => self.sys_timer_create(a0 as _, a1 as _, a2.into()), ... }; ... // 5. 检查系统调用的返回值`ret`是否符合预期 match ret { Ok(_) => 0, Err(err) => err as isize, } } }
系统调用号匹配信息位于
zCore/zircon-syscall/src/consts.rs#L8
#![allow(unused)] fn main() { pub enum SyscallType { BTI_CREATE = 0, BTI_PIN = 1, BTI_RELEASE_QUARANTINE = 2, CHANNEL_CREATE = 3, CHANNEL_READ = 4, CHANNEL_READ_ETC = 5, CHANNEL_WRITE = 6, CHANNEL_WRITE_ETC = 7, CHANNEL_CALL_NORETRY = 8, CHANNEL_CALL_FINISH = 9, CLOCK_GET = 10, CLOCK_ADJUST = 11, CLOCK_GET_MONOTONIC_VIA_KERNEL = 12, ... VMO_CREATE_CONTIGUOUS = 165, VMO_CREATE_PHYSICAL = 166, COUNT = 167, FUTEX_WAKE_HANDLE_CLOSE_THREAD_EXIT = 200, VMAR_UNMAP_HANDLE_CLOSE_THREAD_EXIT = 201, } }
简单实现一个系统调用处理函数(sys_clock_adjust为例)
#![allow(unused)] fn main() { pub fn sys_clock_adjust(&self, resource: HandleValue, clock_id: u32, offset: u64) -> ZxResult { // 1. 记录log信息:info!() info!( "clock.adjust: resource={:#x?}, id={:#x}, offset={:#x}", resource, clock_id, offset ); // 2. 检查参数合法性(需要归纳出每个系统调用的参数值的范围) // missing now // 3. 获取当前进程对象 let proc = self.thread.proc(); // 4. 根据句柄从进程中获取对象 proc.get_object::<Resource>(resource)? .validate(ResourceKind::ROOT)?; match clock_id { ZX_CLOCK_MONOTONIC => Err(ZxError::ACCESS_DENIED), // 5. 调用内河对象API执行具体功能 ZX_CLOCK_UTC => { UTC_OFFSET.store(offset, Ordering::Relaxed); Ok(()) } _ => Err(ZxError::INVALID_ARGS), } } }
一个现有不完全的系统调用实现
sys_clock_get
#![allow(unused)] fn main() { /// Acquire the current time. /// /// + Returns the current time of clock_id via `time`. /// + Returns whether `clock_id` was valid. pub fn sys_clock_get(&self, clock_id: u32, mut time: UserOutPtr<u64>) -> ZxResult { // 记录log信息:info!() info!("clock.get: id={}", clock_id); // 检查参数合法性 // miss match clock_id { ZX_CLOCK_MONOTONIC => { time.write(timer_now().as_nanos() as u64)?; Ok(()) } ZX_CLOCK_UTC => { time.write(timer_now().as_nanos() as u64 + UTC_OFFSET.load(Ordering::Relaxed))?; Ok(()) } ZX_CLOCK_THREAD => { time.write(self.thread.get_time())?; Ok(()) } _ => Err(ZxError::NOT_SUPPORTED), } } }
信号和等待
信号
对象可能有多达 32 个信号(由 zx_signals t 类型和 ZX SIGNAL 定义表示),它们表示有关其当前状态的一条信息。例如,通道和套接字可能是 READABLE 或 WRITABLE 的。进程或线程可能会被终止。等等。
线程可以等待信号在一个或多个对象上变为活动状态。
等待
线程可用于zx_object_wait_one() 等待单个句柄上的信号处于活动状态或 zx_object_wait_many()等待多个句柄上的信号。两个调用都允许超时,即使没有信号挂起,它们也会返回。
超时可能会偏离指定的截止时间,具体取决于计时器的余量。
如果线程要等待大量句柄,使用端口(Port)会更有效,它是一个对象,其他对象可能会绑定到这样的对象,当信号在它们上被断言时,端口会收到一个包含信息的数据包关于未决信号。
事件与事件对
事件(Event)是最简单的对象,除了它的活动信号集合之外没有其他状态。
事件对(Event Pair)是可以相互发出信号的一对事件中的一个。事件对的一个有用属性是,当一对的一侧消失时(它的所有句柄都已关闭),PEER_CLOSED 信号在另一侧被断言。
见:zx_event_create(), 和zx_eventpair_create()。
等待内核对象的信号
信号与等待机制简介
在内核对象中加入信号
定义 Signal 结构体
在 KObjectBase 中加入 signal 和 callbacks 变量,实现 signal 系列函数,并做单元测试
实现信号等待 Future
实现 wait_signal 函数,并做单元测试
利用 select 组合子实现多对象等待
实现 wait_signal_many 函数,并做单元测试
同时等待多个信号:Port 对象
Port 对象简介
同时提及一下 Linux 的 epoll 机制作为对比
实现 Port 对象框架
定义 Port 和 PortPacket 结构体
实现事件推送和等待
实现 KernelObject::send_signal_to_port 和 Port::wait 函数,并做单元测试
实现更多:EventPair, Timer 对象
Event 对象
EventPair 对象
HAL:定时器
实现 timer_now, timer_set,在此基础上实现 SleepFuture
Timer 对象
用户态同步互斥:Futex 对象
Futex 机制简介
Futex 是现代 OS 中用户态同步互斥的唯一底层设施
为什么快:利用共享内存中的原子变量,避免进入内核
Futexes 是内核原语,与用户空间原子操作一起使用以实现高效的同步原语(如Mutexes, Condition Variables等),它只需要在竞争情况(contended case)下才进行系统调用。通常它们实现在标准库中。
实现基础元语:wait 和 wake
实现 wait 和 wake 函数,并做单元测试
实现高级操作
实现 Zircon 中定义的复杂 API
硬件抽象层
zCore 的用户态运行支持
libos 版 zCore(简称uzCore) 的开发与裸机版 zCore (简称bzCore)同步进行,两个版本的 zCore 共用除了HAL 层之外的所有代码。为了支持 uzCore 的正常运行,zCore 在地址空间划分方面对 Zircon /Linux的原有设计进行了一定的修改,并为此对 Fuchsia 的源码进行了简单的修改、重新编译;另外,uzCore 需要的硬件相关层(HAL)将完全由宿主 OS 提供支持,一个合理的 HAL 层接口划分也是为支持 uzCore做出的重要考虑。
HAL 层接口设计
HAL 层的设计是在bzCore 和 uzCore 的开发过程中逐渐演进形成的,在开发过程中将硬件实现相关的接口,比如页表、物理内存分配等进行封装,暴露给上层的内核对象层使用。在 kernel-hal 模块中,给出空的弱链接实现,由 bzCore 或 uzCore 的开发者对相应的接口进行相应的实现,并用设定函数链接名称的方式,替换掉预设的弱链接的空函数。在整个开发过程中,不断对 HAL 层提出需求并实现,目前形成了第一版 HAL 层接口,在设计上能够满足现有的内核对象实现所需要的功能。
对内核对象层而言,所依赖的硬件环境不再是真实硬件环境中能够看到的物理内存、CPU、MMU 等,而是 HAL 暴露给上层的一整套接口。这一点从设计上来说,是 zCore 与 Zircon 存在差异的一点。Zircon 将 x86_64 、ARM64 的硬件架构进行底层封装,但是没有给出一套统一的硬件 API 供上层的内核对象直接使用,在部分内核对象的实现中,仍然需要通过宏等手段对代码进行条件编译,从而支持同时面向两套硬件架构进行开发。而在 zCore 的内核对象层实现中,可以完全不考虑底层硬件接口的实现,使一套内核对象的模块代码可以同时在 bzCore和 uzCore 上运行,之后如果 zCore 进一步支持 RISC-V 64 架构(已初步实现),只需要新增一套 HAL的实现,无需修改上层代码。下面将列出目前的uzCore的HAL层,即kernel-hal-unix的接口。
HAL接口名称 功能描述
- 线程相关
- hal_thread_spawn Thread::spawn创建一个新线程并加入调度
- hal_thread_set_tid Thread::set_tid 设定当前线程的 id
- hal_thread_get_tid Thread::get_tid 获取当前线程的 id
- future
- yield_now暂时让出 CPU,回到async runtime中
- sleep_until 休眠直到定时到达
- YieldFuture 放弃执行的future
- SleepFuture 睡眠且等待被唤醒的future
- SerialFuture 通过serial_read获得字符的future
- 上下文切换相关
- VectorRegs x86相关
- hal_context_run context_run 进入“用户态”运行
- 用户指针相关
- UserPtr 对用户指针的操作:读/写/解引用/访问数组/访问字符串
- IoVec 非连续buffer集合(Vec结构):读/写
- 页表相关
- hal_pt_currentPageTable::current 获取当前页表
- hal_pt_newPageTable::new 新建一个页表
- hal_pt_map PageTable::map 将一个物理页帧映射到一个虚拟地址中
- hal_pt_unmap PageTable::unmap 解映射某个虚拟地址
- hal_pt_protect PageTable::protect 修改vaddr对应的页表项的flags
- hal_pt_query PageTable::query 查询某个虚拟地址对应的页表项状态
- hal_pt_table_phys PageTable::table_phys 获取对应页表的根目录表物理地址
- hal_pt_activate PageTable::activate 激活当前页表
- PageTable::map_many 同时映射多个物理页帧到连续虚拟内存空间
- PageTable::map_cont 同时映射连续的多个物理页帧到虚拟内存空间
- hal_pt_unmap_cont PageTable::unmap_cont 解映射某个虚拟地址开始的一片范围
- MMUFlags 页表项的属性位
- 物理页帧相关
- hal_frame_alloc PhysFrame::alloc 分配一个物理页帧
- hal_frame_alloc_contiguous PhysFrame::alloc_contiguous_base 分配一块连续的物理内存
- PhysFrame::addr 返回物理页帧对应的物理地址
- PhysFrame::alloc_contiguous 分配一块连续的物理内存
- PhysFrame::zero_frame_addr 返回零页的物理地址(一个特殊页,内容永远为全0)
- PhysFrame::drop Drop trait 回收该物理页帧
- hal_pmem_read pmem_read 读取某特定物理页帧的内容到缓冲区
- hal_pmem_write pmem_write 将缓冲区中的内容写入某特定物理页帧
- hal_frame_copy frame_copy 复制物理页帧的内容
- hal_frame_zero frame_zero_in_range 物理页帧清零
- hal_frame_flush frame_flush将物理页帧的数据从 Cache 刷回内存
- 基本I/O外设
- hal_serial_read serial_read 字符串输入
- hal_serial_write serial_write 字符串输出
- hal_timer_now timer_now 获取当前时间
- hal_timer_set timer_set 设置一个时钟,当到达deadline时,会调用 callback 函数
- hal_timer_set_next timer_set_next 设置下一个时钟
- hal_timer_tick timer_tick当时钟中断产生时会调用的时钟函数,触发所有已到时间的 callback
- 中断处理
- hal_irq_handle handle 中断处理例程
- hal_ioapic_set_handle set_ioapic_handle x86相关,对高级中断控制器设置处理例程
- hal_irq_add_handle add_handle 对某中断添加中断处理例程
- hal_ioapic_reset_handle reset_ioapic_handle 重置级中断控制器并设置处理例程
- hal_irq_remove_handle remove_handle 移除某中断的中断处理例程
- hal_irq_allocate_block allocate_block 给某中断分配连续区域
- hal_irq_free_block free_block 给某中断释放连续区域
- hal_irq_overwrite_handler overwrite_handler 覆盖某中断的中断处理例程
- hal_irq_enable enable 使能某中断
- hal_irq_disable disable 屏蔽某中断
- hal_irq_maxinstr maxinstr x86相关,获得IOAPIC的maxinstr???
- hal_irq_configure configure 对某中断进行配置???
- hal_irq_isvalid is_valid 查询某中断是否有效
- 硬件平台相关
- hal_vdso_constants vdso_constants 得到平台相关常量参数
- struct VdsoConstants 平台相关常量:
- hal_vdso_constants vdso_constants 得到平台相关常量参数
max_num_cpus features dcache_line_size ticks_per_second ticks_to_mono_numerator ticks_to_mono_denominator physmem version_string_len version_string
* fetch_fault_vaddr fetch_fault_vaddr 取得出错的地址 ???好像缺了hal_*
* fetch_trap_num fetch_trap_num 取得中断号
* hal_pc_firmware_tables pc_firmware_tables x86相关,取得`acpi_rsdp` 和 `smbios` 的物理地址
* hal_acpi_table get_acpi_table 得到acpi table
* hal_outpd outpd x86相关,对IO Port进行写访问
* hal_inpd inpd x86相关,对IO Port进行读访问
* hal_apic_local_id apic_local_id 得到本地(local) APIC ID
* fill_random 产生随机数,并写入到buffer中
在上述“线程相关”的列表中,列出了 HAL 层的部分接口设计,覆盖线程调度方面。在线程调度方面,Thread 结构体相关的接口主要用于将一个线程加入调度等基本操作。在 zCore 的相关实现中,线程调度的各接口使用 naive-executor 给出的接口以及 trapframe 给出的接口来进行实现,二者都是我们为裸机环境的协程调度与上下文切换所封装的 Rust 库。uzCore 中,线程调度的相关接口依赖于 Rust 的用户态协程支持以及 uzCore 开发者实现的用户态上下文切换。
在内存管理方面,HAL 层将内存管理分为页表操作与物理页帧管理两方面,并以此设计接口。在 zCore 实现中,物理页帧的分配与回收由于需要设计物理页帧分配器,且可分配范围大小与内核刚启动时的内存探测密切相关,我们将其直接在总控模块 zCore 中进行实现。而在 uzCore 中,页表对应操作依赖 mmap 进行模拟,物理页帧的相关操作则直接使用用户态物理内存分配器进行模拟。
在 Zircon 的设计中,内存的初始状态应该设置为全 0,为了在内核对象层满足该要求,我们为 HAL 层设计了零页接口,要求 HAL 层保留一个内容为全 0 的物理页帧,供上层使用。上层负责保证该零页内容不被修改。
修改 VDSO
VDSO 是由内核提供、并只读映射到用户态的动态链接库,以函数接口形式提供系统调用接口。原始的 VDSO 中将会最终使用 syscall 指令从用户态进入内核态。但在 uzCore 环境下,内核和用户程序都运行在用户态,因此需要将 syscall 指令修改为函数调用,也就是将 sysall 指令修改为 call 指令。为此我们修改了 VDSO 汇编代码,将其中的 syscall 替换为 call,提供给 uzCore 使用。在 uzCore 内核初始化环节中,向其中填入 call 指令要跳转的目标地址,重定向到内核中处理 syscall 的特定函数,从而实现模拟系统调用的效果。
调整地址空间范围
在 uzCore 中,使用 mmap 来模拟页表,所有进程共用一个 64 位地址空间。因此,从地址空间范围这一角度来说,运行在 uzCore 上的用户程序所在的用户进程地址空间无法像 Zircon 要求的一样大。对于这一点,我们在为每一个用户进程设置地址空间时,手动进行分配,规定每一个用户进程地址空间的大小为 0x100_0000_0000,从 0x2_0000_0000 开始依次排布。0x0 开始至 0x2_0000_0000 规定为 uzCore 内核所在地址空间,不用于 mmap。图 3.3给出了 uzCore 在运行时若干个用户进程的地址空间分布。
与 uzCore 兼容,zCore 对于用户进程的地址空间划分也遵循同样的设计,但在裸机环境下,一定程度上摆脱了限制,能够将不同用户地址空间分隔在不同的页表中。如图 3.4所示,zCore 中将三个用户进程的地址空间在不同的页表中映射,但是为了兼容 uzCore 的运行,每一个用户进程地址空间中用户程序能够真正访问到的部分都仅有 0x100_0000_0000 大小。
LibOS源代码分析记录
zCore on riscv64的LibOS支持
- LibOS unix模式的入口在linux-loader main.rs:main()
初始化包括kernel_hal_unix,Host文件系统,其中载入elf应用程序的过程与zcore bare模式一样;
重点工作应该在kernel_hal_unix中的内核态与用户态互相切换的处理。
kernel_hal_unix初始化主要包括了,构建Segmentation Fault时SIGSEGV信号的处理函数,当代码尝试使用fs寄存器时会触发信号;
- 为什么要注册这个信号处理函数呢?
根据wrj的说明:由于 macOS 用户程序无法修改 fs 寄存器,当运行相关指令时会访问非法内存地址触发Segmentation Fault。故实现段错误信号处理函数,并在其中动态修改用户程序指令,将 fs 改为 gs
kernel_hal_unix还构造了进入用户态所需的run_fncall() -> syscall_fn_return();
而用户程序需要调用syscall_fn_entry()来返回内核态;
Linux-x86_64平台运行时,用户态和内核态之间的切换运用了 fs base 寄存器;
- Linux 和 macOS 下如何分别通过系统调用设置 fsbase / gsbase 。
这个转换过程调用到了trapframe库,x86_64和aarch64有对应实现,而riscv则需要自己手动实现;
- 关于fs寄存器
查找了下,fs寄存器一般会用于寻址TLS,每个线程有它自己的fs base地址;
fs寄存器被glibc定义为存放tls信息,结构体tcbhead_t就是用来描述tls;
进入用户态前,将内核栈指针保存在内核 glibc 的 TLS 区域中。
可参考一个运行时程序的代码转换工具:https://github.com/DynamoRIO/dynamorio/issues/1568#issuecomment-239819506
- LibOS内核态与用户态的切换
Linux x86_64中,fs寄存器是用户态程序无法设置的,只能通过系统调用进行设置;
例如clone系统调用,通过arch_prctl来设置fs寄存器;指向的struct pthread,glibc中,其中的首个结构是tcbhead_t
计算tls结构体偏移:
经过试验,x86_64平台,int型:4节,指针类型:8节,无符号长整型:8节;
riscv64平台,int型: 4节,指针类型:8节,无符号长整型:8节;
计算tls偏移量时,注意下,在musl中,aarch64和riscv64架构有#define TLS_ABOVE_TP,而x86_64无此定义
- 关于Linux user mode (UML)
"No, UML works only on x86 and x86_64."
https://sourceforge.net/p/user-mode-linux/mailman/message/32782012/