Rust学习感悟
早在今年寒假时就打算学习Rust,奈何一直没有开工。四月份在群里偶然看到了2024春夏季开源操作系统训练营,这才算是开始了Rust学习之旅。
我的Rust入门学习主要是通过阅读和练习两点。
阅读其一是Rust 语言圣经
-
1. 寻找牛刀,以便小试 ✅ 2024-04-10
- 1.1. 安装 Rust 环境 ✅ 2024-04-10
- 1.2. 墙推 VSCode! ✅ 2024-04-10
- 1.3. 认识 Cargo ✅ 2024-04-10
- 1.4. 不仅仅是 Hello world ✅ 2024-04-10
- 1.5. 下载依赖太慢了? ✅ 2024-04-10
-
2. Rust 基础入门 ✅ 2024-04-20
- 2.1. 变量绑定与解构 ✅ 2024-04-10
- 2.2. 基本类型 ✅ 2024-04-10
- 2.3. 所有权和借用 ✅ 2024-04-11
- 2.4. 复合类型 ✅ 2024-04-11
- 2.5. 流程控制 ✅ 2024-04-12
- 2.6. 模式匹配 ✅ 2024-04-12
- 2.7. 方法 Method ✅ 2024-04-17
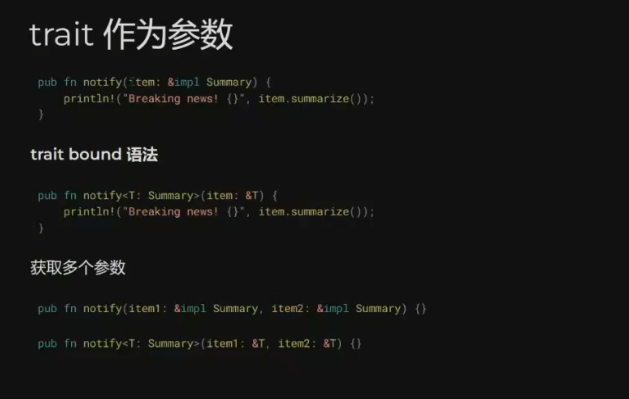
- 2.8. 泛型和特征 ✅ 2024-04-18
- 2.9. 集合类型 ✅ 2024-04-18
- 2.10. 认识生命周期 ✅ 2024-04-18
- 2.11. 返回值和错误处理 ✅ 2024-04-18
- 2.12. 包和模块 ✅ 2024-04-20
- 2.13. 注释和文档 ✅ 2024-04-20
- 2.14. 格式化输出 ✅ 2024-04-20
阅读其二是The Rust Programming Language
Github: GitHub - rust-lang/book: The Rust Programming Language
原版: The Rust Programming Language - The Rust Programming Language
交互版: Experiment Introduction - The Rust Programming Language
-
1. 入门指南 ✅ 2024-04-10
-
2. 写个猜数字游戏 ✅ 2024-04-10
-
3. 常见编程概念 ✅ 2024-04-10
-
4. 认识所有权 ✅ 2024-04-11
-
5. 使用结构体组织相关联的数据 ✅ 2024-04-11
-
6. 枚举和模式匹配 ✅ 2024-04-12
-
7. 使用包、Crate 和模块管理不断增长的项目 ✅ 2024-04-12
-
8. 常见集合 ✅ 2024-04-15
-
9. 错误处理 ✅ 2024-04-16
-
10. 泛型、Trait 和生命周期 ✅ 2024-04-18
-
11. 编写自动化测试 ✅ 2024-04-20
-
12. 一个 I/O 项目:构建命令行程序 ✅ 2024-04-21
-
13. Rust 中的函数式语言功能:迭代器与闭包 ✅ 2024-04-21
-
14. 更多关于 Cargo 和 Crates.io 的内容 ✅ 2024-04-21
-
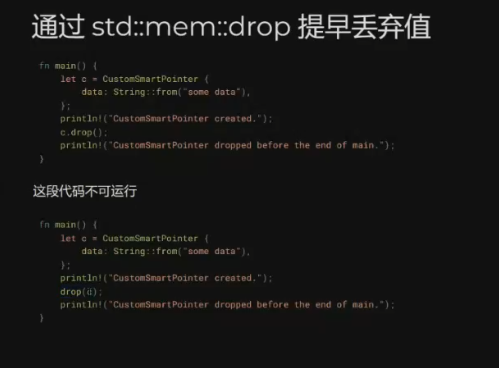
15. 智能指针 ✅ 2024-04-21
-
16. 无畏并发 ✅ 2024-04-21
-
17. Rust 的面向对象编程特性 ✅ 2024-04-21
-
18. 模式与模式匹配 ✅ 2024-04-21
-
19. 高级特征 ✅ 2024-04-21
练习其一是Rust By Practice
Solution: rust-by-practice/solutions at master · sunface/rust-by-practice · GitHub
-
1. 关于 practice.rs ✅ 2024-04-10
-
2. 值得学习的小型项目 ✅ 2024-04-10
-
3. 变量绑定与解构 ✅ 2024-04-10
-
4. 基本类型 ✅ 2024-04-10
-
5. 所有权和借用 ✅ 2024-04-11
-
6. 复合类型 ✅ 2024-04-11
-
7. 流程控制 ✅ 2024-04-12
-
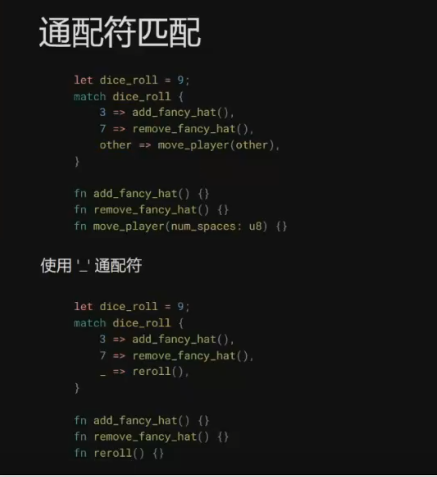
8. 模式匹配 ✅ 2024-04-12
-
9. 方法和关联函数 ✅ 2024-04-17
-
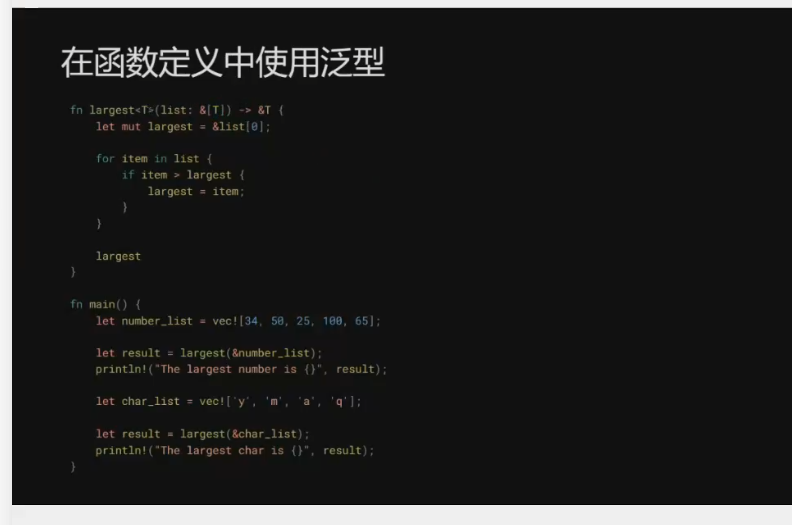
10. 泛型和特征 ✅ 2024-04-18
-
11. 集合类型 ✅ 2024-04-18
-
13. 返回值和 panic! ✅ 2024-04-18
-
14. 包和模块 ✅ 2024-04-20
-
15. 注释和文档 ✅ 2024-04-20
-
16. 格式化输出 ✅ 2024-04-20
练习其二则是训练营第一阶段的rustlings
-
intro ✅ 2024-04-09
-
variables ✅ 2024-04-09
-
functions ✅ 2024-04-11
-
if ✅ 2024-04-11
-
primitive_types ✅ 2024-04-11
-
vecs ✅ 2024-04-16
-
primitive_types ✅ 2024-04-16
-
move_semantics ✅ 2024-04-16
-
structs ✅ 2024-04-16
-
enums ✅ 2024-04-16
-
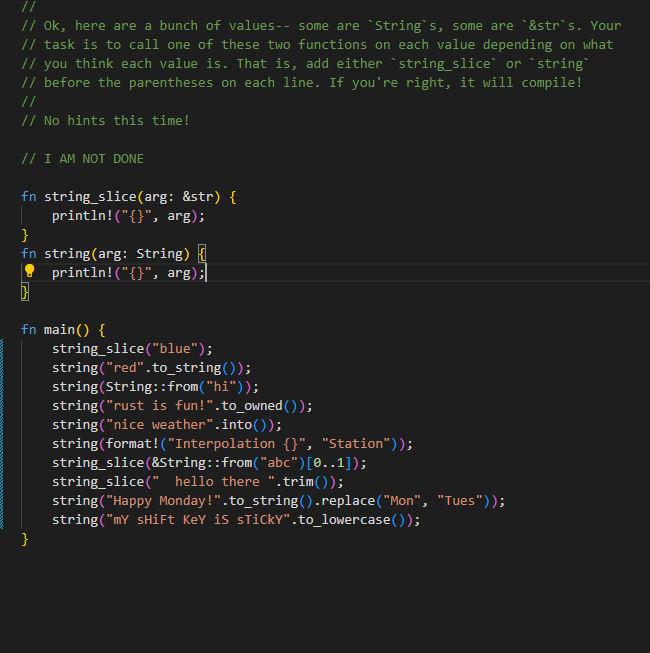
strings ✅ 2024-04-16
-
modules ✅ 2024-04-16
-
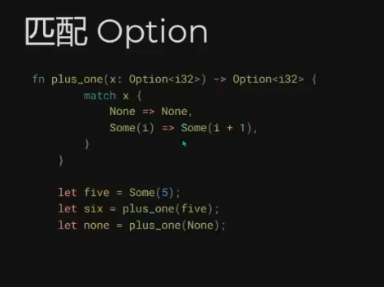
options ✅ 2024-04-16
-
hashmaps ✅ 2024-04-16
-
error_handing ✅ 2024-04-16
-
generics ✅ 2024-04-20
-
lifetimes ✅ 2024-04-20
-
traits ✅ 2024-04-20
-
iterators ✅ 2024-04-20
-
tests ✅ 2024-04-21
-
macros ✅ 2024-04-21
-
threads ✅ 2024-04-21
-
clippy ✅ 2024-04-21
-
conversions ✅ 2024-04-21
-
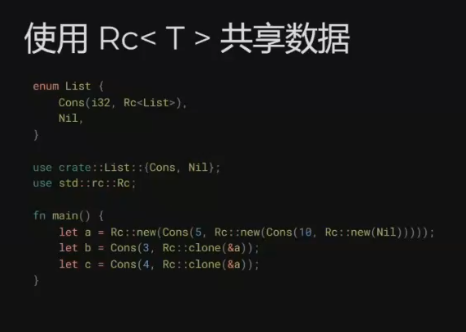
smart_pointers ✅ 2024-04-21
-
quiz ✅ 2024-04-21
-
algorithms ✅ 2024-04-22
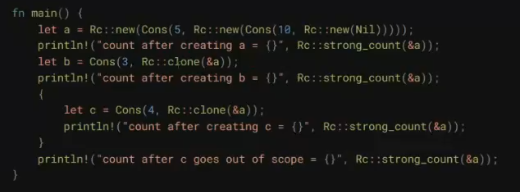
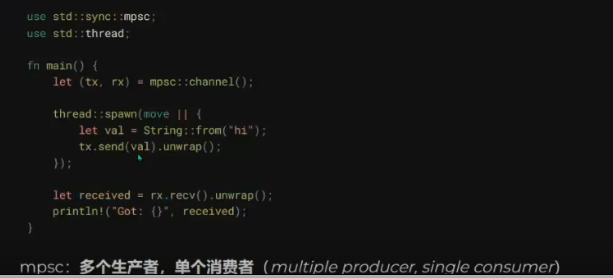
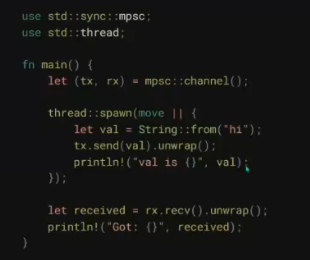
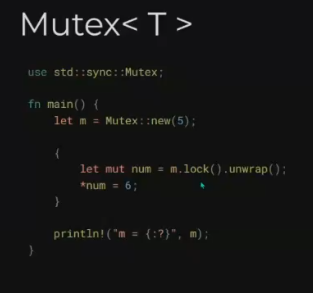
在此过程中,Rust的所有权(Ownership)、生命周期(Lifetimes)、特型(Traits),以及函数式编程中常见的模式匹配(Patterns and Matching)等概念给我留下了深刻的印象。当然,最为深刻的还是Rust的编译器。
我认为在编写极为熟练的代码时,Rust严苛的编译器确实拖慢了我的编码速度(例如写个链表那叫一个费劲),但是从另一方面看,它尽可能地保证了我写出没有歧义的、不会在运行时错误的更健壮的代码。
总的来说,Rust的入门体验还不错,希望在接下来的学习中,我能更进一步地掌握它的特性,以及它在操作系统中内核级代码的应用。