第三阶段总结
在第三阶段主要是学习到了unikernel,和基于unikernel的宏内核和hypervisor。通过做一些练习来学习这些部分的内容。中间的一次lab让优化内存分配组件,因为自己的知识不足,未能完成。希望能在第四阶段更好的学习。
axhal中平台架构的boot程序的_start函数,参数为OpenSBI传入的两个参数,一个是hartid用于识别CPU,一个是dtb_ptr传入DTB的指针。然后进入axruntime初始化应用运行时的环境,即根据feature条件编译各组件框架
SBI配置FW_TEXT_START,BIOS负责把SBI加载到内存的起始位置
0x8000 0000存放SBI,SBI会跳转到以0x8020 0000起始的内核代码,存放.bss、.data、.rodata、.text段。
axhal中的linker_riscv64-qemu-virt.lds指导rust的链接器来实现段布局
一阶段:即上面提到_start函数中的初始化MMU,将物理地址空间恒等映射,再添偏移量。
二阶段:重建映射,一阶段的映射并没有添加权限进行管理。若启用”paging”的feature,首先会调用axmm中的init_memory_management(),进行创建内核空间(new_kernel_aspace()),将根页表地址写入stap寄存器(axhal::paging::set_kernel_page_table_root)。
启用”multitask”的feature,执行axtask::init_scheduler(),会进行就绪队列的初始化,以及系统timers的初始化。
“init_vruntime”在os启动调度的时候决定调度顺序,”nice”则是优先级,优先级越大”vruntime”增长越慢,从而达到高优先。
当时间片结束后,当前任务将被为设为可抢占,当前任务释放控制权,加入就绪队列。并且如果外部条件满足抢占,则会将就绪队列中的队首弹出并切换到该任务
axmm::new_user_aspace
load_user_app
init_user_stack
task::spawn_user_task
user_task.join
页表管理内核地址空间和用户地址空间
内核地址空间只有高端(高地址)存放内核代码数据
用户地址空间高端存放内核,但这部分的页表项设为用户不可见,只有陷入内核态之后才能访问。低端地址存放应用
每个用户地址空间高端的内核均相同,只有存放应用的区域不同
地址空间后端Backend:
Linear:目标物理地址空间已经存在,直接建立映射关系,物理页帧必须连续
Alloc:仅建立空映射,当真正被访问时将会触发缺页异常,然后在缺页响应函数内部完成物理页帧的申请和补齐映射,也就是Lazy方式。物理页帧通常情况下不连续
代码段加载无偏移。
数据段加载到虚拟地址空间分为.data、.bss。但.bss在ELF文件中为节省空间紧凑存储不做存放,仅做标记位置和长度。内核直接预留空间并清零
当发生缺页异常时,由aspace的handle_page_fault来完成对物理页帧的申请与映射
首先检查发生页面错误的虚拟地址 vaddr 是否在当前虚拟地址范围 va_range 内。
然后找到vaddr的区域area,进入area的后端,缺页异常通常由后端Alloc的Lazy策略造成,故进入Alloc分支调用handle_page_fault_alloc对页表remap完成页表映射
虚拟化基于RISCV64的S特权级的H扩展,Host将在HS特权级下进行VM_ENTRY以及VM_EXIT
S特权模式进行H扩展后,原有的s[xxx]寄存器组作用不变,将新增hs[xxx]和vs[xxx]
设置hstatus的SPV位(指示特权级模式的来源,1为VS,0为U)SPVP位(指示HS对V模式下地址空间是否由操作权限)
启动Guest之前,设置Guest的sstatus,设置初始特权级为Supervisor
设置sepc为OS启动入口地址VM_ENTRY,地址为0x8020 0000
run_guest切换:保存Host上下文,将Guest上下文(第一次切换为伪造的上下文)载入寄存器组
VM_EXIT返回Host:保存Guest上下文,将Host上下文载入寄存器组
Hypervisor负责基于Host物理地址空间HPA面向Guest映射Guest物理地址空间GPA
Guest会认为GPA是实际的物理地址空间,它基于satp映射内部的GVA虚拟空间
启用RISC64指令集的G扩展:
低端区域留给设备空间和DMA
0x8000 0000在Host中是存放SBI的,但是虚拟机没有M模式,是无法访问SBI,所以这部分进行保留
0x8020 0000存放内核
高于内核的地址用作物理内存区
实现流程:
最后在Host和Guest环境循环切换,支持虚拟机持续运行
VCPU的准备:
set_entry(VM_ENTRY)设置sepc来配置入口地址0x8020 0000set_ept_root向hgatp设置模式(SV39)和根页表的页帧axhal::irq::register_handler 通过update_timer在中断向量表中注册对应的中断响应函数,更新时钟。然后axtask::on_timer_tick()触发定时任务
第三阶段由于最近比较忙,我只做了unikernel部分的内容,其他部分后续会继续学习和补充。
这一部分的exercises不算难,但是通过学习,对unikernel的理解加深了很多。老师的ppt非常清晰,直观地感受到了组件化内核的特点。
通过这一阶段的学习,我更加理解了组件化内核的优势,如减少内核中的冗余部分,提高系统的灵活性和可维护性。与传统操作系统相比,Unikernel 的模块化设计有助于减少资源占用。
到宏内核的特点就是:
用户空间降级方式:伪造返回现场到新任务, sret
过程:
将调度属性和资源属性分离,从而复用调度组件

用的是linkme这个库linkme 是一个 Rust 的库,主要用于在编译期将数据链接到程序的特定部分(如全局变量),从而实现类似插件或模块化的功能。它可以动态扩展程序的功能,而无需显式修改原始代码。以下是对 linkme 的详细介绍,包括其用法和原理。
linkme 提供了一种机制,使多个 Rust 模块中的静态变量可以被聚合到一个全局列表中。常见的使用场景包括:
Cargo.toml 中添加:1 | `[dependencies] linkme = "0.3"` |
使用 #[linkme::distributed_slice] 定义一个全局的切片,用于收集静态变量。例如:
1 | use linkme::distributed_slice; |
这里,MY_SLICE 是一个切片,它的类型是 fn(),表示可以存放多个函数指针。
在其他模块中,使用 #[distributed_slice] 将元素插入到切片中:
1 | use linkme::distributed_slice; |
在程序中,你可以遍历切片的所有元素,并执行对应逻辑:
1 | fn main() { |
得到
1 | First function |
linkme 的实现基于 Rust 的链接器特性和目标平台的支持。以下是其工作原理:
#[distributed_slice] 宏定义了一个全局符号,分配了一段内存区域,专门用于存储相关的元素。#[distributed_slice] 添加元素时,linkme 会将这些元素放置到编译产物的特定段(section)中。内存管理方式:

其他的和rcore很像,最后会在backend中处理映射
lazy映射:先map出虚拟地址但是没有关联物理地址,在page fault后在处理函数中多次嵌套调用handle,最后在aspace中完成关联
mmap的实现和page fault的处理很像,
hypervisor和虚拟机的区别是:支撑其物理运行的体系结构和其虚拟运行的环境是否一样(同构). 所以hypervisor比虚拟机更加高效.
我的理解,hypervisor也是一种类似于OS软件,如果是U的指令可以直接执行,如果需要特权级就在hypervisor中捕获处理.
hypervisor的扩展指令也是为了加速这个过程
资源管理:
panic将系统shut,所以需要去掉panic改成(ax_println!),然后将sepc+4跳转到下一个指令,再设置一下a0,a1的值就可以了


主要学习了两段映射
第二的部分有两个模式
透传:直接把宿主物理机(即qemu)的pflash透传给虚拟机。(快 捆绑设备)
模拟:模拟一个pflash,当读取的时候传递(慢 不依赖硬件)
切换
具体的汇编:

将pflash.img写入img的/sbin/下后,在 h_2_0/src/main.rc 中将其read出来,然后将第一页的内容填充到buf中,aspace.write进去就可
实验课正在做
总的思路是:通过关键的寄存器hvip中的VSTIP(时钟中断)来向hypervisor响应虚拟机的设置时钟中断,然后当时钟中断来的时候退出vm,并重新设置时钟中断hvip,回到vm处理.
主要是flash这种设备的处理,这个在前一个的实验中已经解决了.
虚拟设备管理:通过mmio,注册device的地址,当发生page fault的时候判断一下,如果是在mem中则正常处理,如果是在device则去对应的设备处理.
如果希望只有通过println宏打印出来的文字有颜色,就应该选择在println定义的地方进行修改,即在axstd中修改
在/arceos/ulib/axstd/src/macros.rs中找到println宏的定义,进行颜色的添加
以下是修改前的输出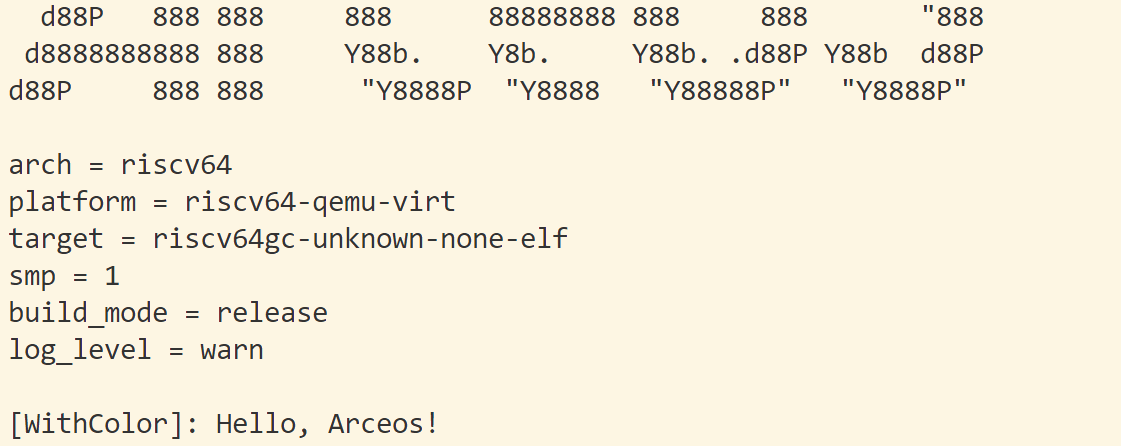
以下是修改后的输出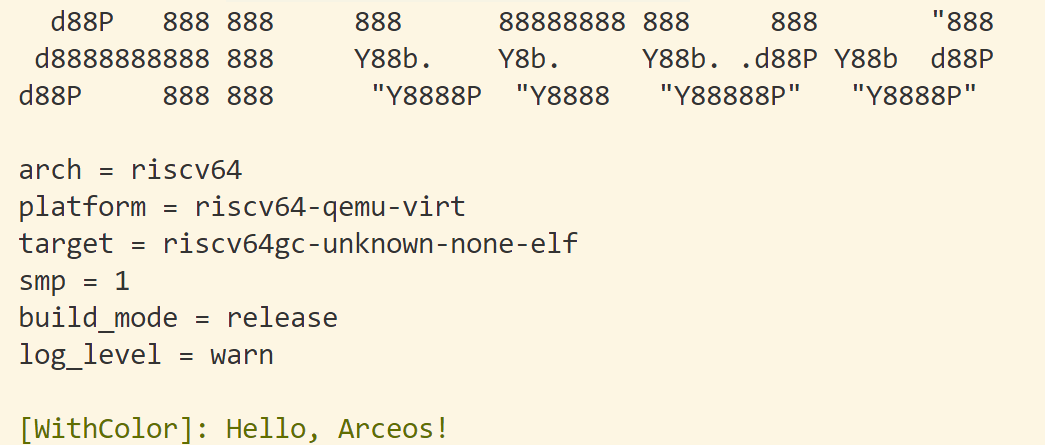
如果希望包括启动信息在内的内容都以某个颜色打印,就需要修改更底层的位置,即修改axhal
找到了axhal中调用输入输出的地方,进行颜色的添加
修改后的输出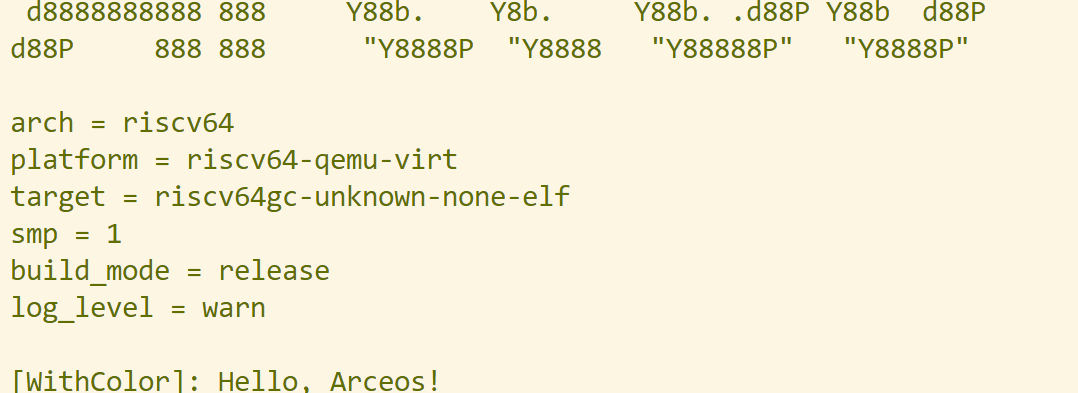
hashbrown 是一个高性能的哈希集合和哈希映射库,提供了 Rust 标准库中 HashMap 和 HashSet 的实现。实际上,Rust 标准库的哈希集合和哈希映射类型(如 std::collections::HashMap 和 std::collections::HashSet)在底层就依赖于 hashbrown。
将hashbrown::HashMap引进就可以了
建立以下路径的文件
/arceos/ulib/axstd/src/collections/mod.rs
添加引用
1 | pub use hashbrown::HashMap; |
然后得到结果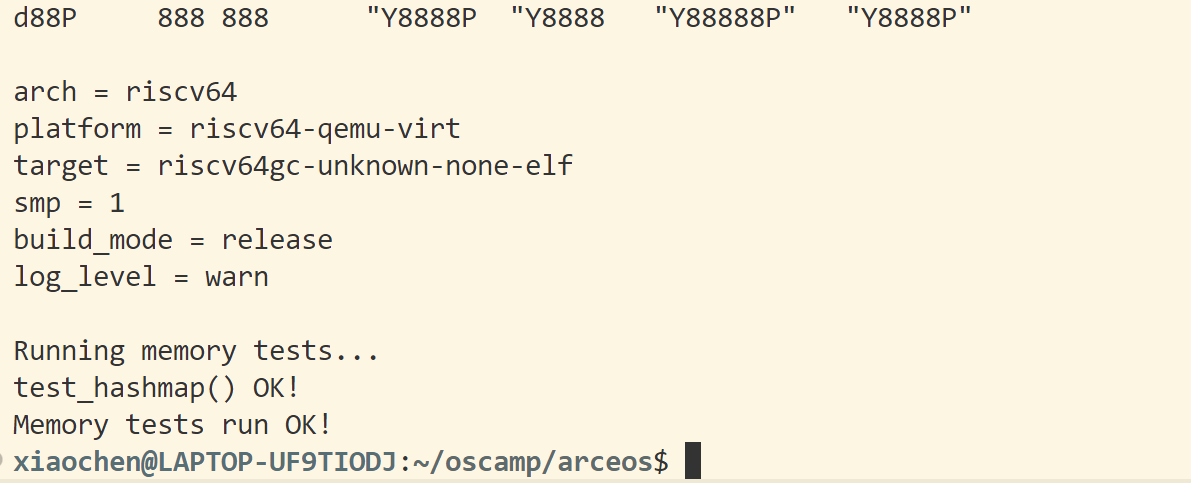
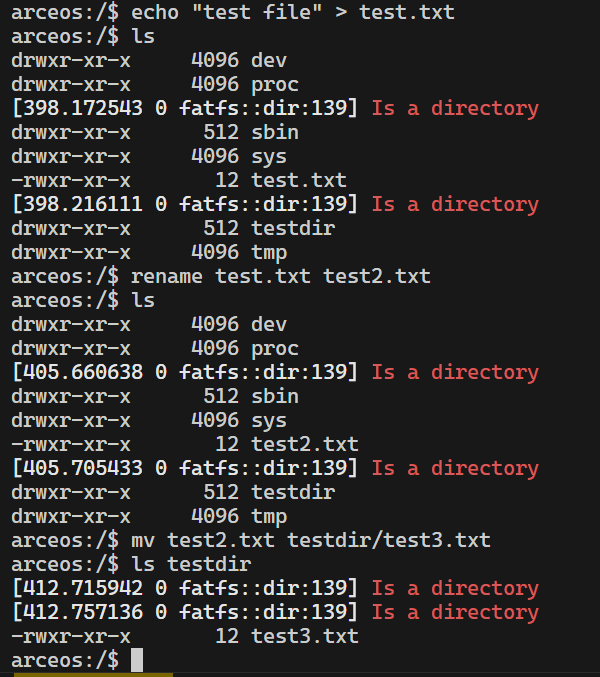
底层已经提供了rename有关的接口,直接调用就实现了rename
关于mv,可以分两种情况,mv的是文件还是文件夹:
如果是文件,其实mv的本质就是rename,将文件夹的路径修改到文件名的前面
如果是文件夹,我认为可以递归文件夹下的所有文件和文件夹,进行rename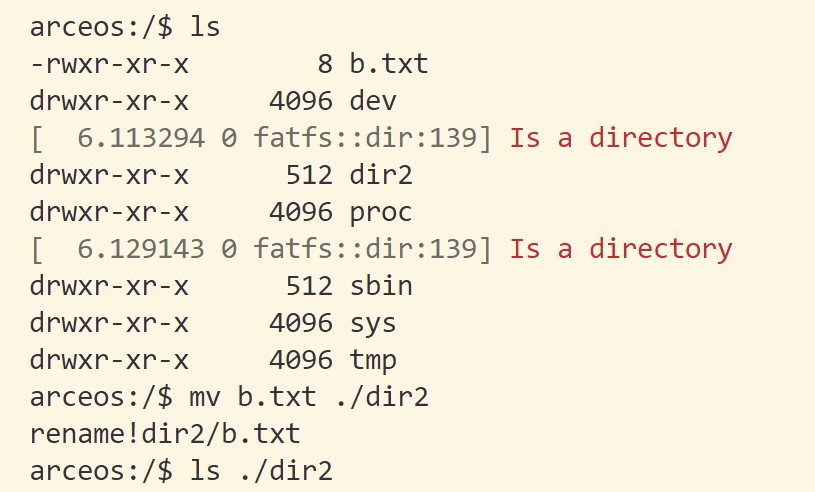
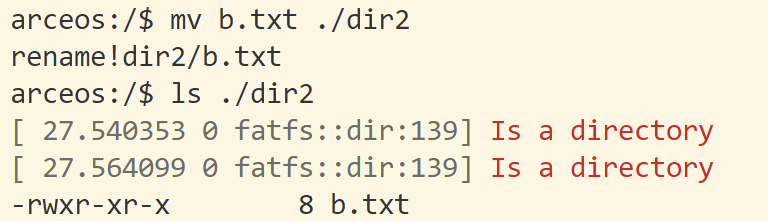
根据给的图示完善结构体,
1 | pub struct EarlyAllocator <const PAGE_SIZE: usize>{ |
alloc时,先对现有的b_pos向上取整对齐,再加上新分配的长度
对于页分配,就多考虑一个页面大小
这个月因为一些工作的原因并没有很好的完成课程的学习挑战这些内容,对于课程只看完了宏内核部分。但是我认为我学到了我感兴趣的部分。对于这部分我学习的感受就是是对于之前的os开发的进一步学习,对于unikernel的组件就是之前rustos实现的部分的更加具体的模块化。(虽然我还是在涉及内存以及地址的部分有些不明白)
对比裸机 这样的组件化操作系统可以更快的添加功能 适配硬件
对比RTOS 可以更加灵活的做删减 比如替换使用的调度算法
更像是一种进化的裸机 所有操作系统都是为了应用而存在的
为应用的功能拆解出各种需要的模块 再拼装成一个只为了这个应用而存在的系统
所有的使用的模块都算作是系统无关的
只有你使用这些系统无关的模块所构成的就是一个系统有关的系统
说到底就是可替换和不可替换的
对于一些模块的功能是不可替换的 就可以说是系统相关的
而对于一部分模块来说就是 可有可无根据需要的特性去选择的就是系统无关的
感觉就像是发展又发展了回去 一开始都是专业的产品 后面开始做通用性的产品当达到一定程度后又开始专业化
那就说明这个是一个高度定制化的系统
目的应该就是在性能更低的平台 来实现更为定制的功能
所以我理解就是 一个定制产品 而不是一个需要很多额外性能 来在一个通用计算机上实现的产品
那么我认为 这个系统应该要和芯片相绑定的 甚至这个应该更为适合fpga平台
来实现真正意义上的软硬一体
一个从一开始就是为了通用计算设计制造的芯片
我觉得会成为这样定制性系统的瓶颈 如果发展下去
相对于unikernl 宏内核增加了一个用户特权级
这样不同的特权级 让应用更加安全因为不能直接访问到内核内的
多伪造了一个所谓的应用态 调用了一次sret来让系统从特权态进入到用户态
我认为这样扩展出来的宏内核系统 就像是在嵌入式设备中常见的中枢网关
这样扩展ArcOS的内核类型我觉得就像是课里面老师说的对于设备端使用unikernel 对于管理端使用宏内核
我感觉这是在构建一个分布式的场景
unikernel的异构思想 就是将共同的组件作为基础
而将不同内核最大的特性作为独立的组件 这样就类似存在多种内核的系统
通过多种异构的内核 但是其中又使用了共同的模块又能有一定的统一性
或者说后期的维护 可以由一个团队共同维护一个场景
可以避免互相不清楚对方的模块导致无法定位问题所在的地方
组件化内核具有灵活,增量构造等优点。
组件化内核最启发我的是组件化可以用来快速构造应对不同场景的各种模式内核。
不同的功能组件,不同的内核特权级,不同的隔离要求…
组件化内核完全可以快速满足这些要求。
单一特权级,简单高效。
实验要点在于了解在不同层级下修改对应输出语句产生的变化,了解输出都来自于哪些层级。
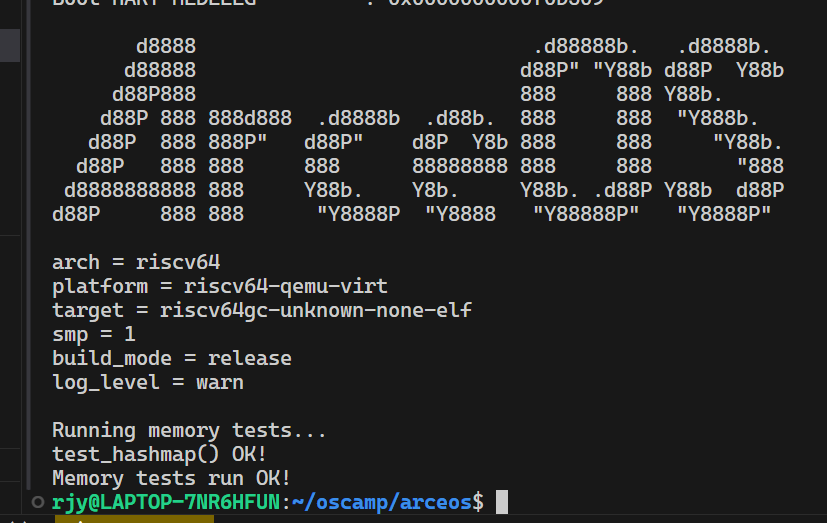
该实验完成对std::hashmap的支持,通过查阅rust的std源码发现rust基于hashbrown。因此引入hashbrown作为hashmap。
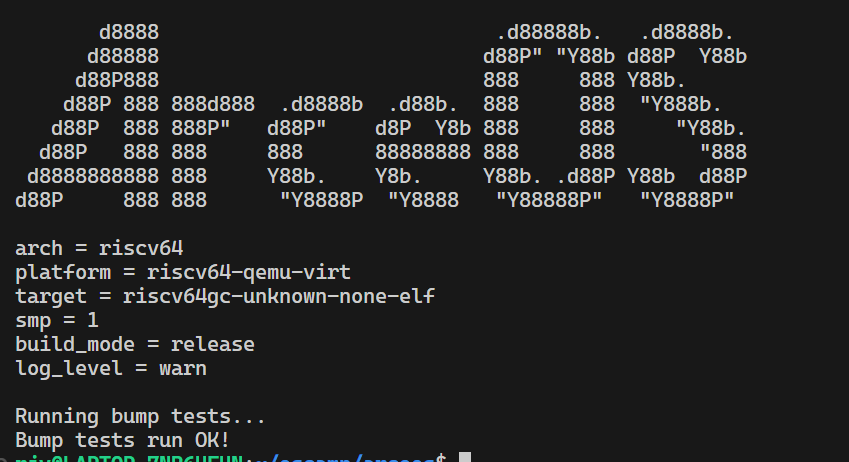
本次实验完成Bump分配算法,此算法较为简单。重点在于实现对应trait。
该实验重点在于了解文件系统对应函数,调用对应函数即可。
注册handle_page_fualt(), 通过aspace中的handle_page_fualt()来处理异常。
该实验是通过仿照linux来完成mmap:
1,阅读linux中的mmap,确定各参数意义:
2,分配内存buf,注意点为分配的空间需要4K对齐;
3,读取文件内容至buf
侧重于虚拟而非模拟,同时保持高效和安全
按实验要求设置对应寄存器值,同时增加spec使guest运行下一条指令。
但不知为何,程序运行会经常卡死,代码未改动情况下运行结果不确定。
将pflash内容写入disk作为文件,与加载guest文件内容类似处理即可。
该lab中的用户程序基本特征为申请n次倍增的内存,之后释放偶数次申请的内存,以此循环。
1,由于物理内存大小为128m,初始即分配全部内存给内存分配器。
2,由于奇偶关系,将内存切分为两个区域。
3,由于倍增关系,将两个区域大小配置为2:1。
非常遗憾也非常懊悔,我这个大三狗由于近两周实在是俗务缠身且不可脱身,因此并未太多参与到rCore的学习中,也仅仅是在第三阶段结束前几天勉强抽空看了一下前几个(前3个)ppt。本人作为一名大三学生,学习这几个 PPT 中的组件化内核设计与实践,感受颇深且困难重重。从基础概念到复杂的技术细节,如内存管理的分页机制、多任务调度算法,再到设备管理框架等,知识量剧增且难度攀升。但我相信如果能跟下去一定是收获满满,从中不仅能拓展操作系统内核知识视野,更能极大提升代码能力,后面也是报名了操作系统内核设计的华东区预赛,希望能抽出更多时间补上第三第四阶段的内容,并在比赛中取得好成绩吧。
主要代码在alt_axalloc里,与axalloc里不同,它在初始化时内部只有一个分配器,并把所有物理内存都分配给它。这个分配器同时实现字节分配器和页分配器的trait,但分配内存时只使用字节分配器里的alloc,页分配器里的alloc_pages没用。
1 | // modules\alt_axalloc\src\lib.rs |
要想正常实现动态内存分配,首先要用#[global_allocator]属实告诉编译器使用哪个分配器实例作为全局分配器。
1 | // modules\alt_axalloc\src\lib.rs |
然后需要为自定义的分配器实现GlobalAlloc trait里的alloc和dealloc方法。查找调用关系:GlonalAlloc::alloc -> GlobalAllocator::alloc -> EarlyAllocator:alloc -> ByteAllocator::alloc,dealloc同理。因此主要修改的代码为modules/bump_allocator里的EarlyAllocator里的ByteAllocator trait的alloca和dealloc方法。
bump的实现参考Writing an OS in Rust : Allocator Designs 分配器设计与实现-CSDN博客
总共可用于分配的堆内存大小是多少?
根据axalloc::global_init(start_vaddr, size) -> GLOBAL_ALLOCATOR.init(start_vaddr, size) 可得size参数的大小即为分配的堆内存大小。查找global_init的使用得axruntime::init_allocator
1 | // axruntime::init_allocator |
由上述代码可得标记为free的内存区域都分配给内存分配器使用。
memory_regions -> platform_regions,当前平台为riscv64
1 | //riscv64_qemu_virt_/mem.rs |
default_free_regions里标记为free,块起始地址为_ekernel,结束地址为PHYS_MEMORY_END。
1 | pub const PHYS_MEMORY_END: usize = PHYS_MEMORY_BASE + PHYS_MEMORY_SIZE; |
定义在config.rs里,查找可得物理内存大小为128m,根据128m查找可得由来为qemu启动时设置的物理内存参数128m。运行时添加LOG=debug参加也可以在输出信息里直观看到分配给分配器的内存,initialize global allocator at: [0xf
fffffc080270000, 0xffffffc088000000), size:131661824。
1 | // GlobalAllocator::alloc |
初始分给字节分配器32KB,当alloc内存不够时,由页分配器再分配页倍数大小的内存。注意分配时要求的内存大小和字节分配器的total_bytes函数返回的值有关,若total_bytes实现不当返回值过大,则一次要求的内存会远远超过实际需要的内存,造成字节分配器分配内存失败,提前终止迭代(我实现的total_bytes返回的是可分配的内存大小,这样每次申请的内存就和需要的内存接近了)。
通过在alloc和dealloc函数里log,分析堆上内存的分配和释放时机,主要和三个变量有关:pool、items和a。a类型是Vec<u8>,可以简单看作是一个内部地址连续的内存块。items和pool类型是Vec<Vec<u8>>,可以看成是存储Vec胖指针的集合。
在主循环里的每一轮先调用alloc_pass申请大量内存,连续申请$a_n\quad (n = 0, 1, 2, \ldots, 14)+\delta$大小的内存块,其中$\delta$表示轮数,$a_n$是首项为32,最大项为524288的以2为公比等比数列,用等比数列的求和公式可得一轮申请的内存块之和大约为1MB。每申请一个内存块便push进items里,items扩容是翻倍,初始申请$4\times32$B大小的内存,扩容的时候先申请$8\times32$B大小的内存,再释放之前申请的。因为一轮循环里总共申请15块内存,items最大容量为$16\times32=384$B。
alloc_pass结束后通过free_pass函数连续释放掉偶数项的内存块。然后将items append进pool里,每一轮循环结束pool就增加$7\times24=168$B大小,pool每次扩容时同样会释放掉之前占用的内存。pool的作用域是整个循环,pool本身及对应奇数项占用的内存在循环结束后才释放,随着循环次数的增加,占用内存越来越大,直到耗光128MB总内存。
我们可以粗略进行分析,如果忽视掉pool和items变量本身的大小(使用bumb算法,items变量最多占用$96+192+384=672$B,pool最多占用$168\times\sum_{n=1}^\delta k$ B)和每次循环递增的$\delta$,每一轮循环释放掉偶数项的总和约为$\frac{2}{3}$ MB,那么理论上最大循环次数约为$128\times3=384$。注意这是在保留奇数项内容正确性,不对奇数项所占内存进行覆写的情况下。
根据上面的分析可知,items能占用的最大空间是有限的,且在每轮循环结束后会全部释放,适合在固定大小的内存区域里使用bumb算法管理。偶数项所占用的内存空间随着$\delta$变化非常缓慢,且同样也会在每轮循环结束前全部释放,同样适合在固定固定大小的内存区域里使用bumb算法管理。同时,items和偶数项都会在全部释放完后再重新分配,所以items和偶数项可以在一块内存里用bumb算法管理。pool和奇数项占用空间是持续增加的,pool会释放,奇数项不会,但为了简单处理一样用bumb算法管理(pool占用内存在轮数较大时存在较大的优化空间)。
分配器初始可用内存为32KB,当分配不够时再向页分配器申请扩容。为了方便划分区域进行管理,在申请第0轮第0项大小的内存时,我们在alloc函数里返回nomemory错误,并在total_bytes函数返回items和偶数项之和的大小来申请足够的内存。在不覆写奇数项情况下,理论最大轮数大约为384,偶数项之和每一项增加15,所以items和偶数项之和为$672+699040+384\times15=704932$B大小,这样分配器初始就能申请向上取整2的n次方和4096的倍数1048576B大小的内存使用。
由初始地址开始,大小为704932B大小的内存区域用来进行items和偶数项的分配和释放。剩下的区域用来进行pool和奇数项的分配和释放,随着奇数项的增加再向页分配器申请新的扩容,直至最终内存耗尽,所有区域内部均使用bumb算法进行管理。注意,每一轮循环里items和偶数项都会在申请完毕后全部释放,奇数项在整个循环期间不释放,所以用bumb管理是合适的。但pool在循环内是会释放的,且随着轮数的增加,空闲内存大小不容忽视,未来可以用更高效的算法来管理pool的内存,还能进一步增加轮数。
先从simple_hv/src/main.rs里的main函数开始运行,此时处于host域。用new_user_aspace创建地址空间,load_vm_image加载要在guest域里运行的内核文件。prepare_guest_context伪造guest上下文件,设置初始特权级为S,sepc值为VM_ENTRY(内核文件的入口地址)。
1 | // Kick off vm and wait for it to exit. |
while循环里将会启动guest并等待它退出。_run_guest在guest.S里,主要功能是保存host上下文和恢复guest上下文,具体细节下次课会讲,最后sret跳转到sepc里的地址,切换到了guest里的内核执行。触发中断后会跳转到_guest_exit里执行,执行完后会进入vmexit_handler函数里执行(执行完_guest_exit后会接着执行_restore_csrs,里面恢复了ra寄存器的值,并在最后使用ret返回到调用_run_guest的下一行)。
1 | //payload/skernel/src/main.rs |
内核程序如上所示,当执行csrr a1, mhartid时,VS态写入了M态的寄存器,触发非法指令异常。ld 10, 64(zero),写入了非法内存地址,触发页错误异常。ecall指令超出VS态执行权限,触发异常。
先触发非法指令异常,在异常函数处理中,我们先需要将sepc+=4(一条指令长度为4字节),以便下次_run_guest里的sret能正确跳转到下条指令执行。然后返回false,以便while循环不退出,继续执行run_guest函数。
这个阶段学得不是很扎实,很多内容都只看了视频,没有完成课后练习,等后面还要进一步回锅。
由于考试和双十一的影响,导致我实际学习三阶段的时间不到一周,到目前为止,勉强把实验做完了(除了最后一个套娃arceos的实验还没有看)。考试自不必多说,至于双十一嘛,是由于外存不够了,要升级一下,然后迁移系统、配置环境什么的。
由于时间较少,而且刚考完一场试,变懒了,所以对ArceOS还没有仔细研究,下面的内容可能较空泛、可能有错误。
在我看来,Unikernel是一个与业务无关的裸机应用,分层、模块化且可扩展,根据业务的需要可以选取需要模块或对模块进行扩展,可以像正常开发linux c应用或std rust应用一样迅速开发裸机应用。
在这一阶段,被迫看了一些关于feature、attribute、条件编译的一些知识,头一次知道原来rust里面还有workspace。
- print_with_color
就加一些特殊的字符
- support_hashmap
看群内大佬讨论,就引了一个库
- alt_alloc
对于这个,一开始还想最初的页是怎么分配来的,后来才想明白这些页已经固定下来了,只要考虑怎么管理就行了。
- shell
对于mv操作,我一开始想的是仅移动指向inode的指针,不拷贝文件,但发现实现有些难,就没有这样做。最终rename和mv都用了rename实现,感觉有些奇怪,但起码测例能过,不愧是arceOS,就是通用。
如果按照上面的理解的话,宏内核是Unikernel上的应用,但是又有些不太对,相比于实现业务目的,它更倾向于是扩展Unikernel,看起来有些像“内核之上不只有应用,还有内核的微内核”。
- page_fault
相比于实现page_fault,我更关注的是linkme这种骚操作。
- sys_map
就find_free_area然后read进去,虽然感觉用find_free_area找到的地方有些不符合man mmap的说明。
在三阶段的实现中,看起来Hypervisor最没用,在裸机之上实现裸机,大部分实现都是透传的,相比于直接运行在裸机上,不仅功能减少了、性能变差了,就连能源的使用也不只是烧电,还烧头发,悲。
还有,感觉可不可以在ArceOS上同时运行宏内核或其他应用和Hypervisor,ASA(ArceOS Subsystem for ArceOS)1.0就在眼前
- simple_hv
改一下guest的sepc,设置一下a0、a1的值
- pflash设备模拟方式
一开始没有搞清gpa映射到hpa时,没有经过host的satp,导致在host中拿着pa当va来用,出现了问题。另外,在完成后,修改了一下pflash的内容,想要读u128转string输出,但是没想到,在对* u128解引用时,它居然会先读u128的高64位,导致映射时页面没对齐。