ArceOS Record ArceOS 的设计可以说优雅而不失健壮性,利用rust优秀的包管理机制和crates的特性组件化地搭建OS,将复杂的OS设计解耦,各个模块功能清晰、层次鲜明,
tutorial出于教学的目的,在modules引入了dependence crates;而在主线arceos中,将解耦做到了极致,形成了清晰的Unikernel层次:dependence crates -> kernel modules -> api -> ulib -> app,下为上提供功能,上到下形成层次鲜明的抽象,这种抽象又为异构内核的实现提供支持,以宏内核为例,其既可以使用api提供的功能,又可以复用kernel modules支持更多的功能,这种自由的复用和组织可以为定制化操作系统提供极大的便利和支持,方便基于需求实现特定OS
Tutorial Record Ch0 Hello World Target:让qemu成功跳转到内核入口,执行指令
1 2 3 4 5 6 7 8 9 10 11 12 13 . ├── axorigin │ ├── Cargo.lock │ ├── Cargo.toml │ └── src │ ├── lang_items.rs │ └── main.rs ├── linker.lds ├── Makefile ├── qemu.log ├── README.md └── rust-toolchain.toml
一、启动内核
qemu-riscv启动内核过程
PC初始化为0x1000
qemu在0x1000预先放置ROM,执行其中代码,跳转到0x8000_0000
qemu在0x8000_0000预先放置OpenSBI,由此启动SBI,进行硬件初始化工作,提供功能调用;M-Mode切换到S-Mode,跳转到0x8020_0000
我们将内核加载到0x8020_0000,启动内核
[!CAUTION]
riscv 体系结构及平台设计的简洁性:
RISC-V SBI 规范定义了平台固件应当具备的功能和服务接口,多数情况下 SBI 本身就可以代替传统上固件 BIOS/UEFI + BootLoader 的位置和作用
// qemu-riscv 启动
二、建立内核程序入口 1 2 3 4 5 6 7 [toolchain] profile = "minimal" channel = "nightly" components = ["rust-src" , "llvm-tools-preview" , "rustfmt" , "clippy" ]targets = ["riscv64gc-unknown-none-elf" ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 将内核入口放置在image文件开头 # linker.lds OUTPUT_ARCH(riscv) BASE_ADDRESS = 0x80200000; ENTRY(_start) SECTIONS { . = BASE_ADDRESS; _skernel = .; .text : ALIGN(4K) { _stext = .; // 内核入口标记:*(.text.boot) *(.text.boot) *(.text .text.*) . = ALIGN(4K); _etext = .; } ... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #![no_std] #![no_main] mod lang_items; #[unsafe(no_mangle)] #[unsafe(link_section = ".text.boot" )] unsafe extern "C" fn _start unsafe { core::arch::asm!("wfi" , options(noreturn),); } } use core::panic::PanicInfo;#[panic_handler] fn panic loop {} }
1 2 3 4 5 6 7 8 9 10 11 # 编译axorigin cargo build --manifest-path axorigin/Cargo.toml \ --target riscv64gc-unknown-none-elf --target-dir ./target --release # 将编译得到的ELF文件转为二进制格式 rust-objcopy --binary-architecture=riscv64 --strip-all -O binary \ target/riscv64gc-unknown-none-elf/release/axorigin \ target/riscv64gc-unknown-none-elf/release/axorigin.bin # 运行qemu qemu-system-riscv64 -m 128M -machine virt -bios default -nographic \ -kernel target/riscv64gc-unknown-none-elf/release/axorigin.bin \ -D qemu.log -d in_asm
Ch1 Hello ArceOS Target:以组件化方式解耦Unikernel内核,实现输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 . ├── axconfig │ └── src │ └── lib.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ └── lang_items.rs │ └── riscv64.rs ├── axorigin │ └── src │ └── main.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs └── spinlock └── src ├── lib.rs └── raw.rs
一、Unikernel与组件化
Unikernel:单内核,将应用程序与kernel编译为单一image
Monolithic:内核态,用户态(Linux
Microkernel:仅在内核保留最基础功能,其他服务在用户态
组件化:组件作为模块封装功能,提供接口,各个组件构成操作系统的基本元素;以构建 crate 的方式来构建组件,通过 dependencies+features 的方式组合组件->ArceOS = 组件仓库 + 组合方式
二、解耦Unikernel
根据功能将Unikernel分为系统层(axhal)和应用层(axorigin)
系统层:封装对体系结构和具体硬件的支持和操作,对外提供硬件操作接口
应用层:实现具体功能,在Ch1中为调用axhal提供的console功能,输出信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #[unsafe(no_mangle)] #[unsafe(link_section = ".text.boot" )] unsafe extern "C" fn _start core::arch::asm!(" la a3, _sbss la a4, _ebss ble a4, a3, 2f 1: sd zero, (a3) add a3, a3, 8 blt a3, a4, 1b 2: la sp, boot_stack_top // setup boot stack(定义在linker.lds la a2, {entry} jalr a2 // call rust_entry(hartid, dtb) j ." , entry = sym super::rust_entry, options(noreturn), ) } #![no_std] #![no_main] mod lang_items;mod boot;pub mod console;unsafe extern "C" fn rust_entry usize , _dtb: usize ) { unsafe extern "C" { fn main usize , dtb: usize ); } main(_hartid, _dtb); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 use core::fmt::{Error, Write};struct Console pub fn putchar u8 ) { #[allow(deprecated)] sbi_rt::legacy::console_putchar(c as usize ); } pub fn write_bytes u8 ]) { for c in bytes { putchar(*c); } } impl Write for Console { fn write_str mut self , s: &str ) -> Result <(), Error> { write_bytes(s.as_bytes()); Ok (()) } } pub fn __print_impl Console.write_fmt(args).unwrap(); } #[macro_export] macro_rules! ax_print { ($($arg:tt)*) => { $crate::console::__print_impl(format_args! ($($arg)*)); } } #[macro_export] macro_rules! ax_println { () => { $crate::print! ("\n" ) }; ($($arg:tt)*) => { $crate::console::__print_impl(format_args! ("{}\n" , format_args! ($($arg)*))); } }
将两个组件进行组合,形成可运行Unikernel
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [package] name = "axhal" version = "0.1.0" edition = "2021" [dependencies] sbi-rt = { version = "0.0.2" , features = ["legacy" ] }[package] name = "axorigin" version = "0.1.0" edition = "2021" [dependencies] axhal = { path = "../axhal" }
三、组件测试/模块测试 组件测试相当于 crate 级的测试,直接在 crate 根目录下建立 tests 模块,对组件进行基于公开接口的黑盒测试;模块测试对应于单元测试,在模块内建立子模块tests,对模块的内部方法进行白盒测试
[!CAUTION]
make run 和 make test编译执行环境不同,make run编译目标为riscv架构,运行在qumu上,make test相当于将测试作为应用直接运行于x86 linux(your pc)上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ifeq ($(filter $(MAKECMDGOALS) ,test) ,) RUSTFLAGS := -C link-arg=-T$(LD_SCRIPT) -C link-arg=-no-pie export RUSTFLAGSendif test: cargo test --workspace --exclude "axorigin" -- --nocapture ifeq ($(filter test test_mod,$(MAKECMDGOALS) ) ,) RUSTFLAGS := -C link-arg=-T$(LD_SCRIPT) -C link-arg=-no-pie export RUSTFLAGSendif test_mod: ifndef MOD @printf " $(YELLOW_C) Error$(END_C) : Please specify a module using MOD=<module_name>\n" @printf " Example: make test_mod MOD=axhal\n" else @printf " $(GREEN_C) Testing$(END_C) module: $(MOD)\n " cargo test --package $(MOD) -- --nocapture endif
1 2 3 4 5 6 7 8 9 10 11 12 // ArceOS/Cargo.toml [workspace] resolver = "2" members = [ "axorigin" , "axhal" , ] [profile.release] lto = true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #![no_std] #[cfg(target_arch = "riscv64" )] mod riscv64;#[cfg(target_arch = "riscv64" )] pub use self::riscv64::*;mod lang_items;mod boot;pub mod console;unsafe extern "C" fn rust_entry usize , _dtb: usize ) { unsafe extern "C" { fn main usize , dtb: usize ); } main(_hartid, _dtb); } [target.'cfg (target_arch = "riscv64" )'.dependencies] sbi-rt = { version = "0.0.2" , features = ["legacy" ] }
axhal隔离riscv64环境后:
1 2 3 4 5 6 7 8 9 Cargo.toml | 10 ++++++++++ Makefile | 7 ++++++- axhal/Cargo.toml | 2 +- axhal/src/lib.rs | 15 ++++----------- axhal/src/riscv64.rs | 10 ++++++++++ axhal/src/{ => riscv64}/boot.rs | 0 axhal/src/{ => riscv64}/console.rs | 0 axhal/src/{ => riscv64}/lang_items.rs | 0 8 files changed, 31 insertions(+), 13 deletions(-)
四、添加组件
全局配置组件 axconfig
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #![no_std] pub const PAGE_SHIFT: usize = 12 ;pub const PAGE_SIZE: usize = 1 << PAGE_SHIFT;pub const PHYS_VIRT_OFFSET: usize = 0xffff_ffc0_0000_0000 ;pub const ASPACE_BITS: usize = 39 ;pub const SIZE_1G: usize = 0x4000_0000 ;pub const SIZE_2M: usize = 0x20_0000 ;#[inline] pub const fn align_up usize , align: usize ) -> usize { (val + align - 1 ) & !(align - 1 ) } #[inline] pub const fn align_down usize , align: usize ) -> usize { (val) & !(align - 1 ) } #[inline] pub const fn align_offset usize , align: usize ) -> usize { addr & (align - 1 ) } #[inline] pub const fn is_aligned usize , align: usize ) -> bool { align_offset(addr, align) == 0 } #[inline] pub const fn phys_pfn usize ) -> usize { pa >> PAGE_SHIFT }
自旋锁 SpinRaw
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #![no_std] mod raw;pub use raw::{SpinRaw, SpinRawGuard}use core::cell::UnsafeCell;use core::ops::{Deref, DerefMut};pub struct SpinRaw data: UnsafeCell<T>, } pub struct SpinRawGuard data: *mut T, } unsafe impl <T> Sync for SpinRaw<T> {}unsafe impl <T> Send for SpinRaw<T> {}impl <T> SpinRaw<T> { #[inline(always)] pub const fn new Self { Self { data: UnsafeCell::new(data), } } #[inline(always)] pub fn lock self ) -> SpinRawGuard<T> { SpinRawGuard { data: unsafe { &mut *self .data.get() }, } } } impl <T> Deref for SpinRawGuard<T> { type Target #[inline(always)] fn deref self ) -> &T { unsafe { &*self .data } } } impl <T> DerefMut for SpinRawGuard<T> { #[inline(always)] fn deref_mut mut self ) -> &mut T { unsafe { &mut *self .data } } }
[!NOTE]
UnsafeCell是实现 内部可变性(Interior Mutability) 的核心机制
初始化组件axsync
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #![no_std] mod bootcell;pub use bootcell::BootOnceCell;use core::cell::OnceCell;pub struct BootOnceCell inner: OnceCell<T>, } impl <T> BootOnceCell<T> { pub const fn new Self { Self { inner: OnceCell::new() } } pub fn init self , val: T) { let _ = self .inner.set(val); } pub fn get self ) -> &T { self .inner.get().unwrap() } pub fn is_init self ) -> bool { self .inner.get().is_some() } } unsafe impl <T> Sync for BootOnceCell<T> {}
Ch2 内存管理1 Target:组织Unikernel为四层系统架构,引入虚拟内存和内存分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 # Ch2 Code Framework . ├── axalloc │ └── src │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── lang_items.rs │ │ └── paging.rs │ └── riscv64.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ └── lib.rs ├── axstd │ └── src │ └── lib.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs └── raw.rs
一、内核框架构建
原来的系统只有系统层axhal和应用层axorigin,我们需要另外增加一层管理组织组件的axstd层,它负责了应用和系统的隔离,抽象了系统为应用提供的功能;另外axhal负责了与硬件体系相关的工作,另外一些组件的初始化(硬件体系无关)需要一个位于axhal之上的抽象层来负责,因此引入了axruntime提供运行时管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 mod lang_items;mod boot;pub mod console;mod paging;unsafe extern "C" fn rust_entry usize , dtb: usize ) { extern "C" { fn rust_main usize , dtb: usize ); } rust_main(hartid, dtb); } #![no_std] pub use axhal::ax_println as println;#[no_mangle] pub extern "C" fn rust_main usize , _dtb: usize ) -> ! { extern "C" { fn _skernel fn main } println! ("\nArceOS is starting ..." ); axalloc::early_init(_skernel as usize - 0x100000 , 0x100000 ); unsafe { main(); } loop {} } #![no_std] #![no_main] use axstd::{String , println};#[no_mangle] pub fn main usize , _dtb: usize ) { let s = String ::from("from String" ); println! ("\nHello, ArceOS![{}]" , s); }
二、引入分页机制 为什么需要虚拟内存和分页机制:物理地址空间是硬件平台生产构造时就已经确定的,而虚拟地址空间则是内核可以根据实际需要灵活定义和实时改变的,这是将来内核很多重要机制的基础。按照近年来流行的说法,分页机制赋予了内核“软件定义”地址空间的能力。
内核可以开启CPU的MMU的分页机制,通过MMU提供的地址映射功能,使内核见到的是虚拟地址空间
我们启用Sv39分页机制,这是rCore就涉及的内容,不多赘述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #![no_std] use axconfig::{phys_pfn, PAGE_SHIFT, ASPACE_BITS};const _PAGE_V : usize = 1 << 0 ; const _PAGE_R : usize = 1 << 1 ; const _PAGE_W : usize = 1 << 2 ; const _PAGE_E : usize = 1 << 3 ; const _PAGE_U : usize = 1 << 4 ; const _PAGE_G : usize = 1 << 5 ; const _PAGE_A : usize = 1 << 6 ; const _PAGE_D : usize = 1 << 7 ; const PAGE_TABLE: usize = _PAGE_V;pub const PAGE_KERNEL_RO: usize = _PAGE_V | _PAGE_R | _PAGE_G | _PAGE_A | _PAGE_D;pub const PAGE_KERNEL_RW: usize = PAGE_KERNEL_RO | _PAGE_W;pub const PAGE_KERNEL_RX: usize = PAGE_KERNEL_RO | _PAGE_E;pub const PAGE_KERNEL_RWX: usize = PAGE_KERNEL_RW | _PAGE_E;#[derive(Debug)] pub enum PagingError pub type PagingResult Result <T, PagingError>;const PAGE_PFN_SHIFT: usize = 10 ;const ENTRIES_COUNT: usize = 1 << (PAGE_SHIFT - 3 );#[derive(Clone, Copy)] #[repr(transparent)] pub struct PTEntry u64 );impl PTEntry { pub fn set mut self , pa: usize , flags: usize ) { self .0 = Self::make(phys_pfn(pa), flags); } fn make usize , prot: usize ) -> u64 { ((pfn << PAGE_PFN_SHIFT) | prot) as u64 } } pub struct PageTable 'a > { level: usize , table: &'a mut [PTEntry], } impl PageTable<'_ > { pub fn init usize , level: usize ) -> Self { let table = unsafe { core::slice::from_raw_parts_mut(root_pa as *mut PTEntry, ENTRIES_COUNT) }; Self { level, table } } const fn entry_shift self ) -> usize { ASPACE_BITS - (self .level + 1 ) * (PAGE_SHIFT - 3 ) } const fn entry_size self ) -> usize { 1 << self .entry_shift() } pub const fn entry_index self , va: usize ) -> usize { (va >> self .entry_shift()) & (ENTRIES_COUNT - 1 ) } pub fn map mut self , mut va: usize , mut pa: usize , mut total_size: usize , best_size: usize , flags: usize ) -> PagingResult { let entry_size = self .entry_size(); while total_size >= entry_size { let index = self .entry_index(va); if entry_size == best_size { self .table[index].set(pa, flags); } else { let mut pt = self .next_table_mut(index)?; pt.map(va, pa, entry_size, best_size, flags)?; } total_size -= entry_size; va += entry_size; pa += entry_size; } Ok (()) } fn next_table_mut mut self , _index: usize ) -> PagingResult<PageTable> { unimplemented! (); } }
实现组件page_table后,需要在axhal层init时映射内核空间,并使mmu启用分页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 use axconfig::{SIZE_1G, phys_pfn};use page_table::{PAGE_KERNEL_RWX, PageTable};use riscv::register::satp;unsafe extern "C" { unsafe fn boot_page_table } pub unsafe fn init_boot_page_table let mut pt: PageTable = PageTable::init(boot_page_table as usize , 0 ); let _ = pt.map(0x8000_0000 , 0x8000_0000 , SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX); let _ = pt.map( 0xffff_ffc0_8000_0000 , 0x8000_0000 , SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX, ); } pub unsafe fn init_mmu let page_table_root = boot_page_table as usize ; unsafe { satp::set(satp::Mode::Sv39, 0 , phys_pfn(page_table_root)); riscv::asm::sfence_vma_all(); } } use crate::riscv64::paging;#[no_mangle] #[link_section = ".text.boot" ] unsafe extern "C" fn _start core::arch::asm!(" mv s0, a0 // save hartid mv s1, a1 // save DTB pointer la a3, _sbss la a4, _ebss ble a4, a3, 2f 1: sd zero, (a3) add a3, a3, 8 blt a3, a4, 1b 2: la sp, boot_stack_top // setup boot stack call {init_boot_page_table} // setup boot page table call {init_mmu} // enabel MMU li s2, {phys_virt_offset} // fix up virtual high address add sp, sp, s2 // readjust stack address mv a0, s0 // restore hartid mv a1, s1 // restore DTB pointer la a2, {entry} add a2, a2, s2 // readjust rust_entry address jalr a2 // call rust_entry(hartid, dtb) j ." , init_boot_page_table = sym paging::init_boot_page_table, init_mmu = sym paging::init_mmu, phys_virt_offset = const axconfig::PHYS_VIRT_OFFSET, entry = sym super::rust_entry, options(noreturn), ) }
三、启用动态内存分配 在第一部分的框架代码中我们使用了String,但是String的实现需要动态内存分配支持,这本来是rust std库提供的功能,我们需要实现内核级的动态内存堆管理的支持,因此我们引入了axalloc组件,它的初始化在axruntime中完成。
全局内存分配器 GlobalAllocator 实现 GlobalAlloc Trait,它包含两个功能:字节分配和页分配,分别用于响应对应请求。区分两种请求的策略是,请求分配的大小是页大小的倍数且按页对齐,就视作申请页;否则就是按字节申请分配。我们在GlobalAllocator的下层实现一个early allocator提供底层内存分配的抽象封装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #![no_std] use axconfig::PAGE_SIZE;use core::alloc::Layout;use core::ptr::NonNull;use spinlock::SpinRaw;extern crate alloc;use alloc::alloc::GlobalAlloc;mod early;use early::EarlyAllocator;#[derive(Debug)] pub enum AllocError InvalidParam, MemoryOverlap, NoMemory, NotAllocated, } pub type AllocResult Result <T, AllocError>;#[cfg_attr(not(test), global_allocator)] static GLOBAL_ALLOCATOR: GlobalAllocator = GlobalAllocator::new();struct GlobalAllocator early_alloc: SpinRaw<EarlyAllocator>, } impl GlobalAllocator { pub const fn new Self { Self { early_alloc: SpinRaw::new(EarlyAllocator::uninit_new()), } } pub fn early_init self , start: usize , size: usize ) { self .early_alloc.lock().init(start, size) } } impl GlobalAllocator { fn alloc_bytes self , layout: Layout) -> *mut u8 { if let Ok (ptr) = self .early_alloc.lock().alloc_bytes(layout) { ptr.as_ptr() } else { alloc::alloc::handle_alloc_error(layout) } } fn dealloc_bytes self , ptr: *mut u8 , layout: Layout) { self .early_alloc .lock() .dealloc_bytes(NonNull::new(ptr).expect("dealloc null ptr" ), layout) } fn alloc_pages self , layout: Layout) -> *mut u8 { if let Ok (ptr) = self .early_alloc.lock().alloc_pages(layout) { ptr.as_ptr() } else { alloc::alloc::handle_alloc_error(layout) } } fn dealloc_pages self , _ptr: *mut u8 , _layout: Layout) { unimplemented! (); } } unsafe impl GlobalAlloc for GlobalAllocator { unsafe fn alloc self , layout: Layout) -> *mut u8 { if layout.size() % PAGE_SIZE == 0 && layout.align() == PAGE_SIZE { self .alloc_pages(layout) } else { self .alloc_bytes(layout) } } unsafe fn dealloc self , ptr: *mut u8 , layout: Layout) { if layout.size() % PAGE_SIZE == 0 && layout.align() == PAGE_SIZE { self .dealloc_pages(ptr, layout) } else { self .dealloc_bytes(ptr, layout) } } } pub fn early_init usize , len: usize ) { GLOBAL_ALLOCATOR.early_init(start, len) }
底层内存分配器
[!TIP]
Layout 是 Rust 标准库中定义的一个结构体,用于描述内存分配的 布局要求 ,包含两个核心字段:
size: usizealign: usize
1 2 // 分配一个 16 字节、按 8 字节对齐的内存块 let layout = Layout::from_size_align(16, 8).unwrap();
byte_pos 和 page_pos 的意义EarlyAllocator 通过两个指针管理内存区域:
byte_pos低地址向高地址 分配小粒度内存(字节级)。page_pos高地址向低地址 分配大粒度内存(页级)
设计特点 :
仅在所有字节分配都被释放时(count == 0),才将 byte_pos 重置到 start。
不支持部分释放,适用于 批量分配后一次性释放 的场景(如临时缓冲区)。
page_dealloc为支持
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 #![allow(dead_code)] #[cfg(test)] mod tests;use crate::{AllocError, AllocResult};use axconfig::{PAGE_SIZE, align_down, align_up};use core::alloc::Layout;use core::ptr::NonNull;#[derive(Default)] pub struct EarlyAllocator start: usize , end: usize , count: usize , byte_pos: usize , page_pos: usize , } impl EarlyAllocator { pub fn init mut self , start: usize , size: usize ) { self .start = start; self .end = start + size; self .byte_pos = start; self .page_pos = self .end; } pub const fn uninit_new Self { Self { start: 0 , end: 0 , count: 0 , byte_pos: 0 , page_pos: 0 , } } } impl EarlyAllocator { pub fn alloc_pages mut self , layout: Layout) -> AllocResult<NonNull<u8 >> { assert_eq! (layout.size() % PAGE_SIZE, 0 ); let next = align_down(self .page_pos - layout.size(), layout.align()); if next <= self .byte_pos { alloc::alloc::handle_alloc_error(layout) } else { self .page_pos = next; NonNull::new(next as *mut u8 ).ok_or(AllocError::NoMemory) } } pub fn total_pages self ) -> usize { (self .end - self .start) / PAGE_SIZE } pub fn used_pages self ) -> usize { (self .end - self .page_pos) / PAGE_SIZE } pub fn available_pages self ) -> usize { (self .page_pos - self .byte_pos) / PAGE_SIZE } } impl EarlyAllocator { pub fn alloc_bytes mut self , layout: Layout) -> AllocResult<NonNull<u8 >> { let start = align_up(self .byte_pos, layout.align()); let next = start + layout.size(); if next > self .page_pos { alloc::alloc::handle_alloc_error(layout) } else { self .byte_pos = next; self .count += 1 ; NonNull::new(start as *mut u8 ).ok_or(AllocError::NoMemory) } } pub fn dealloc_bytes mut self , _ptr: NonNull<u8 >, _layout: Layout) { self .count -= 1 ; if self .count == 0 { self .byte_pos = self .start; } } fn total_bytes self ) -> usize { self .end - self .start } fn used_bytes self ) -> usize { self .byte_pos - self .start } fn available_bytes self ) -> usize { self .page_pos - self .byte_pos } }
Ch3 Basic Component Target:增加基础组件,扩展子系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 # Code . ├── axalloc │ └── src │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axdtb │ └── src │ ├── lib.rs │ └── util.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── lang_items.rs │ │ ├── misc.rs │ │ ├── paging.rs │ │ └── time.rs │ └── riscv64.rs ├── axlog │ └── src │ └── lib.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ └── lib.rs ├── axstd │ └── src │ ├── lib.rs │ └── time.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── buddy_allocator │ └── src │ ├── lib.rs │ ├── linked_list │ │ └── tests.rs │ └── linked_list.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs └── raw.rs
一、打破循环依赖 我们希望在ch3引入axlog日志组件,但是这会出现循环依赖,无法通过编译:组件 axruntime 在初始化时,将会初始化 axhal 和 axlog 这两个组件。对于 axhal 和 axlog 这两个组件来说,一方面,axhal 组件需要日志功能,所以依赖 axlog 组件;与此同时,axlog 必须依赖 axhal 提供的标准输出或写文件功能以实现日志输出,所以 axlog 又反过来依赖 axhal。这就在二者之间形成了循环依赖。
我们使用extern ABI的方式声明外部函数,并在crate中直接调用避免循环依赖;创建组件crate_interface使用过程宏封装extern ABI来对这种方式提供抽象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #[crate_interface::def_interface] pub trait LogIf fn write_str str ); fn get_time } struct LogIfImpl #[crate_interface::impl_interface] impl axlog::LogIf for LogIfImpl { fn write_str str ) { console::write_bytes(s.as_bytes()); } fn get_time time::current_time() } } pub fn init extern crate alloc; let now = crate_interface::call_interface!(LogIf::get_time()); let s = alloc::format! ("Logging startup time: {}.{:06}" , now.as_secs(), now.subsec_micros()); crate_interface::call_interface!(LogIf::write_str(s.as_str())); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 #![doc = include_str!("../README.md" )] use proc_macro::TokenStream; use proc_macro2::Span; use quote::{format_ident, quote}; use syn::parse::{Error, Parse, ParseStream, Result }; use syn::punctuated::Punctuated; use syn::{parenthesized, parse_macro_input, Token}; use syn::{Expr, FnArg, ImplItem, ImplItemFn, ItemImpl, ItemTrait, Path, PathArguments, PathSegment, TraitItem, Type}; fn compiler_error err.to_compile_error().into() } #[proc_macro_attribute] pub fn def_interface if !attr.is_empty() { return compiler_error(Error::new( Span::call_site(), "expect an empty attribute: `#[def_interface]`" , )); } let ast = syn::parse_macro_input!(item as ItemTrait); let trait_name = &ast.ident; let vis = &ast.vis; let mut extern_fn_list = vec! []; for item in &ast.items { if let TraitItem::Fn (method) = item { let mut sig = method.sig.clone(); let fn_name = &sig.ident; sig.ident = format_ident!("__{}_{}" , trait_name, fn_name); sig.inputs = syn::punctuated::Punctuated::new(); for arg in &method.sig.inputs { if let FnArg::Typed(_) = arg { sig.inputs.push(arg.clone()); } } let extern_fn = quote! { pub #sig; }; extern_fn_list.push(extern_fn); } } let mod_name = format_ident!("__{}_mod" , trait_name); quote! { #ast #[doc(hidden)] #[allow(non_snake_case)] #vis mod #mod_name { use super::*; extern "Rust" { #(#extern_fn_list)* } } } .into() } #[proc_macro_attribute] pub fn impl_interface if !attr.is_empty() { return compiler_error(Error::new_spanned(...)); } let mut ast = syn::parse_macro_input!(item as ItemImpl); let trait_name = if let Some ((_, path, _)) = &ast.trait_ { &path.segments.last().unwrap().ident } else { ... }; let impl_name = if let Type::Path(path) = &ast.self_ty.as_ref() { path.path.get_ident().unwrap() } else { ... }; for item in &mut ast.items { if let ImplItem::Fn (method) = item { let (attrs, vis, sig, stmts) = (&method.attrs, &method.vis, &method.sig, &method.block.stmts); let fn_name = &sig.ident; let extern_fn_name = format_ident!("__{}_{}" , trait_name, fn_name); let mut new_sig = sig.clone(); new_sig.ident = extern_fn_name.clone(); new_sig.inputs = Punctuated::new(); let mut args = vec! []; let mut has_self = false ; for arg in &sig.inputs { match arg { FnArg::Receiver(_) => has_self = true , FnArg::Typed(ty) => { args.push(ty.pat.clone()); new_sig.inputs.push(arg.clone()); } } } let call_impl = if has_self { quote! { let _impl : #impl_name = #impl_name; _impl .#fn_name(#(#args),*) } } else { quote! { #impl_name::#fn_name(#(#args),*) } }; let item = quote! { #[inline] #(#attrs)* #vis #sig { { #[inline] #[export_name = #extern_fn_name] extern "Rust" #new_sig { #call_impl } } #(#stmts)* } } .into(); *method = syn::parse_macro_input!(item as ImplItemFn); } } quote! { #ast }.into() } #[proc_macro] pub fn call_interface let call = parse_macro_input!(item as CallInterface); let args = call.args; let mut path = call.path.segments; if path.len() < 2 { return compiler_error(...); } let fn_name = path.pop().unwrap(); let trait_name = path.pop().unwrap(); let extern_fn_name = format_ident!("__{}_{}" , trait_name.ident, fn_name.ident); path.push_value(PathSegment { ident: format_ident!("__{}_mod" , trait_name.ident), arguments: PathArguments::None , }); quote! { unsafe { #path::#extern_fn_name(#args) } }.into() } struct CallInterface impl Parse for CallInterface { fn parse Result <Self > { let path: Path = input.parse()?; let args = if input.peek(Token![,]) { input.parse::<Token![,]>()?; input.parse_terminated(Expr::parse, Token![,])? } else if !input.is_empty() { parenthesized!(content in input); content.parse_terminated(Expr::parse, Token![,])? } else { Punctuated::new() }; Ok (CallInterface { path, args }) } }
二、其他组件 axlog 封装并扩展crate.io中的crate - log。按照 crate log 的实现要求,为 定义的全局日志实例 Logger 实现 trait Log 接口。这个外部的 crate log 本身是一个框架,实现了日志的各种通用功能,但是如何对日志进行输出需要基于所在的环境,这个 trait Log 就是通用功能与环境交互的接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 macro_rules! with_color { ($color_code:expr, $($arg:tt)*) => {{ format_args! ("\u{1B}[{}m{}\u{1B}[m" , $color_code as u8 , format_args! ($($arg)*)) }}; } #[repr(u8)] #[allow(dead_code)] enum ColorCode Red = 31 , Green = 32 , Yellow = 33 , Cyan = 36 , White = 37 , BrightBlack = 90 , } impl Log for Logger { #[inline] fn enabled self , _metadata: &Metadata) -> bool { true } fn log self , record: &Record) { let level = record.level(); let line = record.line().unwrap_or(0 ); let path = record.target(); let args_color = match level { Level::Error => ColorCode::Red, Level::Warn => ColorCode::Yellow, Level::Info => ColorCode::Green, Level::Debug => ColorCode::Cyan, Level::Trace => ColorCode::BrightBlack, }; let now = call_interface!(LogIf::get_time); print_fmt(with_color!( ColorCode::White, "[{:>3}.{:06} {path}:{line}] {args}\n" , now.as_secs(), now.subsec_micros(), path = path, line = line, args = with_color!(args_color, "{}" , record.args()), )); } fn flush self ) {} }
axdtb 内核最初启动时从 SBI 得到两个参数分别在 a0 和 a1 寄存器中。其中 a1 寄存器保存的是 dtb 的开始地址,而 dtb 就是 fdt 的二进制形式,它的全称 device tree blob。由于它已经在内存中放置好,内核启动时就可以直接解析它的内容获取信息。我们引入组件axdtb让内核自己解析 fdt 设备树来获得硬件平台的配置情况,作为后面启动过程的基础
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 impl DeviceTree { pub fn parse &self , mut pos: usize , mut addr_cells: usize , mut size_cells: usize , cb: &mut dyn FnMut (String , usize , usize , Vec <(String , Vec <u8 >)>) ) -> DeviceTreeResult<usize > { let buf = unsafe { core::slice::from_raw_parts(self .ptr as *const u8 , self .totalsize) }; if buf.read_be_u32(pos)? != OF_DT_BEGIN_NODE { return Err (DeviceTreeError::ParseError(pos)) } pos += 4 ; let raw_name = buf.read_bstring0(pos)?; pos = align_up(pos + raw_name.len() + 1 , 4 ); let mut props = Vec ::new(); while buf.read_be_u32(pos)? == OF_DT_PROP { let val_size = buf.read_be_u32(pos+4 )? as usize ; let name_offset = buf.read_be_u32(pos+8 )? as usize ; let val_start = pos + 12 ; let val_end = val_start + val_size; let val = buf.subslice(val_start, val_end)?; let prop_name = buf.read_bstring0(self .off_strings + name_offset)?; let prop_name = str ::from_utf8(prop_name)?.to_owned(); if prop_name == "#address-cells" { addr_cells = val.read_be_u32(0 )? as usize ; } else if prop_name == "#size-cells" { size_cells = val.read_be_u32(0 )? as usize ; } props.push((prop_name, val.to_owned())); pos = align_up(val_end, 4 ); } let name = str ::from_utf8(raw_name)?.to_owned(); cb(name, addr_cells, size_cells, props); while buf.read_be_u32(pos)? == OF_DT_BEGIN_NODE { pos = self .parse(pos, addr_cells, size_cells, cb)?; } if buf.read_be_u32(pos)? != OF_DT_END_NODE { return Err (DeviceTreeError::ParseError(pos)) } pos += 4 ; Ok (pos) } }
Ch4 内存管理2 Target:实现多级页表和内存分配器,重建地址映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 # Code framework . ├── axalloc │ └── src │ ├── bitmap.rs │ ├── buddy.rs │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axdtb │ └── src │ ├── lib.rs │ └── util.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── lang_items.rs │ │ ├── mem.rs │ │ ├── misc.rs │ │ ├── paging.rs │ │ └── time.rs │ └── riscv64.rs ├── axlog │ └── src │ └── lib.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ └── lib.rs ├── axstd │ └── src │ ├── lib.rs │ └── time.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── bitmap_allocator │ └── src │ └── lib.rs ├── buddy_allocator │ └── src │ ├── lib.rs │ ├── linked_list │ │ └── tests.rs │ └── linked_list.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs └── raw.rs
一、实现多级页表 扩展实现Ch2的页表机制,之前的 map 实现十分简单,只是映射了 1G,并且 va/pa 地址以及总长度 total_size 都是按 1G 对齐的。但是如果地址范围可能出现不对齐的情况,这是指开始/结束地址没有按照 best_size 对齐或者总长度就小于 best_size。例如我们期望按照 2M 的粒度进行映射(即 best_size 是 2M,如上图所示),但是起止地址都没有按照 2M 对齐,那就需要把映射范围分成三个部分:把中间按照 2M 对齐的部分截出来,按照 2M 的 best_size 进行映射;把前后两个剩余部分按照 4K 的粒度单独映射.
改进map方法,如果映射范围总长度小于 best_size,后面都直接按照 4K 页粒度映射。如果地址范围的头部存在不对齐的部分,先按 4K 页粒度映射。调用 map_aligned 方法按照 best_size 进行映射。如果还存在剩余部分尚未映射,那这部分也是未对齐的部分,按照 4K 页粒度映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 pub fn map &mut self , mut va: usize , mut pa: usize , mut total_size: usize , best_size: usize , flags: usize , ) -> PagingResult { let mut map_size = best_size; if total_size < best_size { map_size = PAGE_SIZE; } let offset = align_offset(va, map_size); if offset != 0 { assert! (map_size != PAGE_SIZE); let offset = map_size - offset; self .map_aligned(va, pa, offset, PAGE_SIZE, flags)?; va += offset; pa += offset; total_size -= offset; } let aligned_total_size = align_down(total_size, map_size); total_size -= aligned_total_size; self .map_aligned(va, pa, aligned_total_size, map_size, flags)?; if total_size != 0 { va += aligned_total_size; pa += aligned_total_size; self .map_aligned(va, pa, total_size, PAGE_SIZE, flags) } else { Ok (()) } } fn map_aligned &mut self , mut va: usize , mut pa: usize , mut total_size: usize , best_size: usize , flags: usize , ) -> PagingResult { assert! (is_aligned(va, best_size)); assert! (is_aligned(pa, best_size)); assert! (is_aligned(total_size, best_size)); let entry_size = self .entry_size(); let next_size = min(entry_size, total_size); while total_size >= next_size { let index = self .entry_index(va); if entry_size == best_size { self .table[index].set(pa, flags); } else { let mut pt = self .next_table_mut(index)?; pt.map(va, pa, next_size, best_size, flags)?; } total_size -= next_size; va += next_size; pa += next_size; } Ok (()) }
二、页内存分配器 这一分我们实现一个 bitmap 位分配器,下一步它将作为正式的页分配器的核心,管理内存页的分配与释放。位分配器基于bitmap数据结构,我们可以用每一位 bit 来代表一个内存块,通常 1 表示空闲可用,0 表示已分配;内存块的大小可以根据需要设定,粒度小到字节 byte,大到页面 page。我们对页内存进行层级化管理,形成若干级 bitmap,每一级 bitmap 包含 16 位 ,从上往下,第 1 级只有一个 bitmap,它每一位指向第 2 级的一个 bitmap,共 16 个;如此嵌套,直至最底层 leaf level,leaf level 对应 1M 位,所以包括 64K 个 bitmap(1M / 16 = 64K)。进一步来说,每一级的 bitmap 的 bit 位对应管理着不同数量的连续页空间,第 1 级 bitmap 的一个 bit 位代表 64K 个连续页(1M / 16 = 64K),而最底层 leaf level 上每个 bitmap 的每个 bit 位仅对应一个页。
当搜索空闲页面时,只需要从上向下逐级递归查找,如果发现一个位是 0 时,就说明它对应的连续页空间已经被完全 占用,不必再递归下一级,直接查看下一个位;否则说明其下对应的范围内还有空闲页,需要递归进去进一步查找和确认。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pub type BitAlloc1M pub type BitAlloc64K pub type BitAlloc4K pub type BitAlloc256 #[derive(Default)] pub struct BitAllocCascade16 bitset: u16 , sub: [T; 16 ], } #[derive(Default)] pub struct BitAlloc16 u16 );pub trait BitAlloc Default { const CAP: usize ; const DEFAULT: Self ; fn alloc mut self ) -> Option <usize >; fn alloc_contiguous mut self , size: usize , align_log2: usize ) -> Option <usize >; fn next self , key: usize ) -> Option <usize >; fn dealloc mut self , key: usize ); fn insert mut self , range: Range<usize >); fn remove mut self , range: Range<usize >); fn is_empty self ) -> bool ; fn test self , key: usize ) -> bool ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 impl BitmapPageAllocator { pub fn alloc_pages mut self , layout: Layout) -> AllocResult<NonNull<u8 >> { if layout.align() % PAGE_SIZE != 0 || !layout.align().is_power_of_two() { return Err (AllocError::InvalidParam); } let num_pages = (layout.size() + PAGE_SIZE - 1 ) / PAGE_SIZE; if num_pages == 0 { return Err (AllocError::InvalidParam); } let align_pow2 = layout.align() / PAGE_SIZE; let align_log2 = align_pow2.trailing_zeros() as usize ; let result = match num_pages { 1 => self .inner.alloc(), _ => self .inner.alloc_contiguous(num_pages, align_log2), }; result .map(|idx| idx * PAGE_SIZE + self .base) .map(|pos| NonNull::new(pos as *mut u8 ).unwrap()) .ok_or(AllocError::NoMemory) } pub fn dealloc_pages mut self , pos: usize , num_pages: usize ) { let idx = (pos - self .base) / PAGE_SIZE; self .inner.dealloc_range(idx, num_pages); } }
三、字节内存分配器 我们完成了从早期的页分配器到正式页分配器的切换后继续实现字节分配器,我们将基于经典的伙伴算法(buddy)实现这个内存分配器。关于伙伴算法,简单来说,一个内存块可以分成对等大小、地址连续的两个内存块,它们称为伙伴。当进行内存分配时,如果没有正好符合要求的空闲内存块,则需要对更大的空闲内存块逐级平分,直到划分出符合要求的最小内存块;内存释放时,尝试与它的伙伴进行合并,直至不能合并为止。这个算法兼顾了分配速度和碎片化问题。它的实现原理如下图所示:
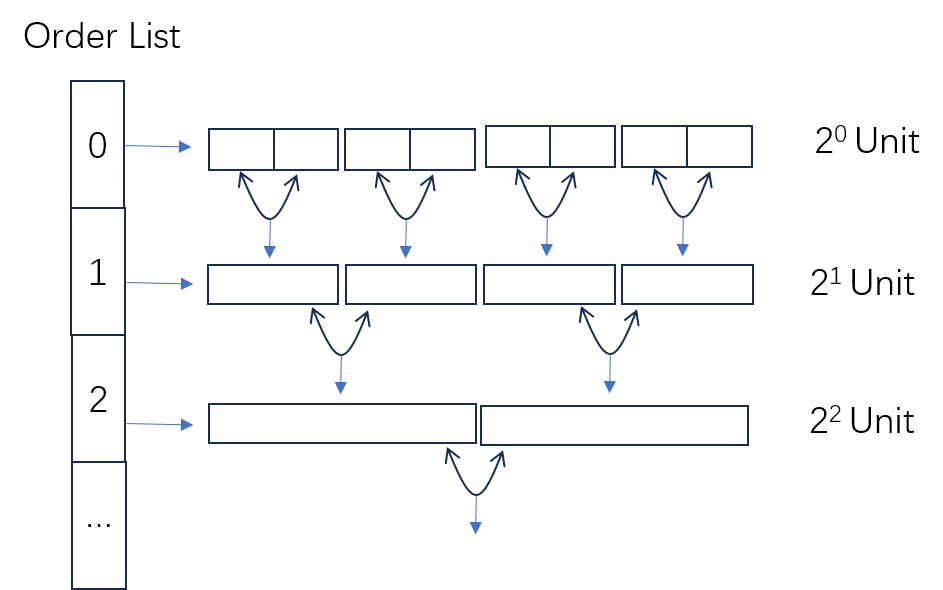
从图中可见,buddy 内存分配器的实现结构简单,就是通过数组 + 链表 来维护空闲的内存块。
数组索引称 Order,每个 Order 维护一组具有相同大小的空闲内存块,它们通过链表结构连接在一起。Order 与本级所维护的空闲块大小的对应关系:空闲块大小 = $ 2^{order} $ 字节。在分配时,每一级 Order 上的内存块都可以平分为一对伙伴内存块,挂到更低一级的 Order 链表上;反之在释放内存块时,查看它的伙伴内存块是否也是空闲,如果是则合并成上一级的大块,挂到上一级 Order 的链表中。
我们的链表使用侵入式链表 linked_list,其特点是:链表的节点直接嵌入到空闲内存块内部
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #[derive(Copy, Clone)] pub struct LinkedList head: *mut usize , } unsafe impl Send for LinkedList {}impl LinkedList { pub const fn new LinkedList { head: ptr::null_mut(), } } pub fn is_empty self ) -> bool { self .head.is_null() } pub unsafe fn push mut self , item: *mut usize ) { unsafe { *item = self .head as usize ; } self .head = item; } pub fn pop mut self ) -> Option <*mut usize > { match self .is_empty() { true => None , false => { let item = self .head; self .head = unsafe { *item as *mut usize }; Some (item) } } } pub fn iter self ) -> Iter { Iter { curr: self .head, list: PhantomData, } } pub fn iter_mut mut self ) -> IterMut { IterMut { prev: &mut self .head as *mut *mut usize as *mut usize , curr: self .head, list: PhantomData, } } } pub struct Iter 'a > { curr: *mut usize , list: PhantomData<&'a LinkedList>, } impl <'a > Iterator for Iter<'a > { type Item mut usize ; fn next mut self ) -> Option <Self::Item> { if self .curr.is_null() { None } else { let item = self .curr; let next = unsafe { *item as *mut usize }; self .curr = next; Some (item) } } } pub struct IterMut 'a > { list: PhantomData<&'a mut LinkedList>, prev: *mut usize , curr: *mut usize , } impl <'a > Iterator for IterMut<'a > { type Item fn next mut self ) -> Option <Self::Item> { if self .curr.is_null() { None } else { let res = ListNode { prev: self .prev, curr: self .curr, }; self .prev = self .curr; self .curr = unsafe { *self .curr as *mut usize }; Some (res) } } }
[!NOTE]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 #[derive(Debug)] pub enum AllocError NoMemory, InvalidLayout, } pub struct Heap const ORDER: usize > { free_list: [linked_list::LinkedList; ORDER], used: usize , allocated: usize , total: usize , } impl <const ORDER: usize > Heap<ORDER> { pub const fn new Self { Heap { free_list: [linked_list::LinkedList::new(); ORDER], used: 0 , allocated: 0 , total: 0 , } } pub const fn empty Self { Self::new() } } impl <const ORDER: usize > Heap<ORDER> { pub unsafe fn add_to_heap mut self , mut start: usize , mut end: usize ) { start = (start + size_of::<usize >() - 1 ) & (!size_of::<usize >() + 1 ); end &= !size_of::<usize >() + 1 ; assert! (start <= end); let mut total = 0 ; let mut current_start = start; while current_start + size_of::<usize >() <= end { let lowbit = current_start & (!current_start + 1 ); let size = min(lowbit, prev_power_of_two(end - current_start)); total += size; unsafe { self .free_list[size.trailing_zeros() as usize ].push(current_start as *mut usize ); } current_start += size; } self .total += total; } pub unsafe fn init mut self , start: usize , size: usize ) { unsafe { self .add_to_heap(start, start + size) }; } } pub (crate ) fn prev_power_of_two usize ) -> usize { 1 << (usize ::BITS as usize - num.leading_zeros() as usize - 1 ) } impl <const ORDER: usize > Heap<ORDER> { pub fn alloc mut self , layout: Layout) -> Result <NonNull<u8 >, AllocError> { let size = max( layout.size().next_power_of_two(), max(layout.align(), size_of::<usize >()), ); let class = size.trailing_zeros() as usize ; for i in class..self .free_list.len() { if !self .free_list[i].is_empty() { for j in (class + 1 ..i + 1 ).rev() { if let Some (block) = self .free_list[j].pop() { unsafe { self .free_list[j - 1 ] .push((block as usize + (1 << (j - 1 ))) as *mut usize ); self .free_list[j - 1 ].push(block); } } else { return Err (AllocError::NoMemory); } } let result = NonNull::new( self .free_list[class] .pop() .expect("current block should have free space now" ) as *mut u8 , ); if let Some (result) = result { self .used += layout.size(); self .allocated += size; return Ok (result); } else { return Err (AllocError::NoMemory); } } } Err (AllocError::NoMemory) } pub fn dealloc mut self , ptr: NonNull<u8 >, layout: Layout) { let size = max( layout.size().next_power_of_two(), max(layout.align(), size_of::<usize >()), ); let class = size.trailing_zeros() as usize ; unsafe { self .free_list[class].push(ptr.as_ptr() as *mut usize ); let mut current_ptr = ptr.as_ptr() as usize ; let mut current_class = class; while current_class < self .free_list.len() { let buddy = current_ptr ^ (1 << current_class); let mut flag = false ; for block in self .free_list[current_class].iter_mut() { if block.value() as usize == buddy { block.pop(); flag = true ; break ; } } if flag { self .free_list[current_class].pop(); current_ptr = min(current_ptr, buddy); current_class += 1 ; self .free_list[current_class].push(current_ptr as *mut usize ); } else { break ; } } } self .used -= layout.size(); self .allocated -= size; } pub fn stats_total_bytes self ) -> usize { self .total } } impl <const ORDER: usize > Default for Heap<ORDER> { fn default Self { Self::new() } }
Ch5 线程管理 Target: 支持多任务管理与调度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 # Code framework . ├── axalloc │ └── src │ ├── bitmap.rs │ ├── buddy.rs │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axdtb │ └── src │ ├── lib.rs │ └── util.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── context.rs │ │ ├── cpu.rs │ │ ├── lang_items.rs │ │ ├── mem.rs │ │ ├── misc.rs │ │ ├── paging.rs │ │ └── time.rs │ └── riscv64.rs ├── axlog │ └── src │ └── lib.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ └── lib.rs ├── axstd │ └── src │ ├── io.rs │ ├── lib.rs │ ├── thread.rs │ └── time.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── axtask │ └── src │ ├── lib.rs │ ├── run_queue.rs │ ├── task.rs │ └── wait_queue.rs ├── bitmap_allocator │ └── src │ └── lib.rs ├── buddy_allocator │ └── src │ ├── lib.rs │ ├── linked_list │ │ └── tests.rs │ └── linked_list.rs ├── kernel_guard │ └── src │ └── lib.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs └── raw.rs
一、初始任务 我们需要让内核支持任务与调度,任务是被调度的对象,它具有独立的工作逻辑。调度是资源不足时,协调每个请求对资源使用的方法。在 ArceOS 的语境下,任务等价于线程。也就是说,每个任务拥有独立的执行流 和独立的栈 ,但是它们没有独立的地址空间,而是共享唯一的内核地址空间。
我们首先需要建立一个MainTask,后续我们将要创建的那些任务都是 MainTask 的分支和子任务,需要受到它的管理。因为arceos作为unikernel每次只会运行一个app,可以把MainTask看作应用的初始进程,维护未运行线程时的上下文,之后用spawn创建的任务为app的线程,如果线程退出,就再调度运行MainTask
另外,还有一个特殊的空闲系统任务 Idle,当没有任何其它任务可以调度时,Idle 将临时充当 CPU 当前任务:
1 2 3 4 5 pub fn run_idle loop { yield_now(); } }
维度
MainTask (主任务)
Idle (空闲任务)
角色 系统主逻辑入口
CPU 空闲兜底任务
调度优先级 正常优先级
最低优先级(仅在无任务时运行)
退出行为 退出时可能终止系统
永不退出
阻塞能力 可被阻塞
不可阻塞
实现目标 执行业务逻辑
避免 CPU 空转,维持调度循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 pub fn init_scheduler info!("Initialize scheduling..." ); run_queue::init(); } pub (crate ) fn init const IDLE_TASK_STACK_SIZE: usize = 4096 ; let idle_task = Task::new(|| run_idle(), "idle" .into(), IDLE_TASK_STACK_SIZE); IDLE_TASK.init(idle_task.clone()); let main_task = Task::new_init("main" .into()); main_task.set_state(TaskState::Running); unsafe { CurrentTask::init_current(main_task) } } impl Task { fn new_common String ) -> Self { Self { id, name, is_idle: false , is_init: false , entry: None , state: AtomicU8::new(TaskState::Ready as u8 ), in_wait_queue: AtomicBool::new(false ), exit_code: AtomicI32::new(0 ), wait_for_exit: WaitQueue::new(), kstack: None , ctx: UnsafeCell::new(TaskContext::new()), } } pub (crate ) fn new String , stack_size: usize ) -> AxTaskRef where F: FnOnce () + 'static , { let mut t = Self::new_common(TaskId::new(), name); debug!("new task: {}" , t.name()); let kstack = TaskStack::alloc(align_up(stack_size, PAGE_SIZE)); t.entry = Some (Box ::into_raw(Box ::new(entry))); t.ctx.get_mut().init(task_entry as usize , kstack.top()); t.kstack = Some (kstack); if t.name == "idle" { t.is_idle = true ; } Arc::new(t) } pub (crate ) fn new_init String ) -> AxTaskRef { let mut t = Self::new_common(TaskId::new(), name); t.is_init = true ; if t.name == "idle" { t.is_idle = true ; } Arc::new(t) } }
二、创建任务 前面我们已经让内核的主线程成为第一个任务 MainTask;本节将在 MainTask 的基础上,使用spawn创建一个应用级的任务,这个任务可以理解为app的一个线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #[derive(Debug)] pub struct Builder name: Option <String >, stack_size: Option <usize >, } impl Builder { pub fn spawn self , f: F) -> io::Result <JoinHandle<T>> where F: FnOnce () -> T + 'static , F: 'static , T: 'static , { unsafe { self .spawn_unchecked(f) } } unsafe fn spawn_unchecked self , f: F) -> Result <JoinHandle<T>> where F: FnOnce () -> T + 'static , F: 'static , T: 'static , { let name = self .name.unwrap_or_default(); let stack_size = self .stack_size.unwrap_or(axconfig::TASK_STACK_SIZE); let my_packet = Arc::new(Packet { result: UnsafeCell::new(None ), }); let their_packet = my_packet.clone(); let main = move || { let ret = f(); unsafe { *their_packet.result.get() = Some (ret) }; drop (their_packet); }; let inner = axtask::spawn_raw(main, name, stack_size); let task = AxTaskHandle { id: inner.id().as_u64(), inner, }; Ok (JoinHandle { thread: Thread::from_id(task.id), native: task, packet: my_packet, }) } } pub fn spawn where F: FnOnce () -> T + 'static , T: 'static , { Builder::new().spawn(f).expect("failed to spawn thread" ) }
用户调用join将MainTask切换到spawn创建的线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 pub struct JoinHandle native: AxTaskHandle, thread: Thread, packet: Arc<Packet<T>>, } unsafe impl <T> Send for JoinHandle<T> {}unsafe impl <T> Sync for JoinHandle<T> {}impl <T> JoinHandle<T> { pub fn thread self ) -> &Thread { &self .thread } pub fn join mut self ) -> Result <T> { Self::wait_for_exit(self .native).ok_or_else(|| IoError::BadState)?; Arc::get_mut(&mut self .packet) .unwrap() .result .get_mut() .take() .ok_or_else(|| IoError::BadState) } fn wait_for_exit Option <i32 > { task.inner.join() } }
MainTask 对 AppTask 调用 join,建立等待关系,然后把自己状态设置为 Blocked,从运行队列 run_queue 转移到等待队列 wait_queue,然后触发重新调度让出执行权。直到 AppTask 退出时,MainTask 作为等待者被重新唤醒,继续执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 pub fn wait_until self , condition: F)where F: Fn () -> bool , { loop { let mut rq = RUN_QUEUE.lock(); if condition() { break ; } rq.block_current(|task| { task.set_in_wait_queue(true ); self .queue.lock().push_back(task); }); } self .cancel_events(current()); }
三、任务切换 app调用join后MainTask将自己加入wait_queue后使用resched调度app线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 impl AxRunQueue { fn resched mut self , preempt: bool ) { let prev = current(); if prev.is_running() { prev.set_state(TaskState::Ready); if !prev.is_idle() { self .put_prev_task(prev.clone(), preempt); } } let next = self .pick_next_task().unwrap(); self .switch_to(prev, next); } fn switch_to mut self , prev_task: CurrentTask, next_task: AxTaskRef) { next_task.set_state(TaskState::Running); if prev_task.ptr_eq(&next_task) { return ; } unsafe { let prev_ctx_ptr = prev_task.ctx_mut_ptr(); let next_ctx_ptr = next_task.ctx_mut_ptr(); CurrentTask::set_current(prev_task, next_task); (*prev_ctx_ptr).switch_to(&*next_ctx_ptr); } } } #[repr(C)] #[derive(Debug, Default)] pub struct TaskContext pub ra: usize , pub sp: usize , pub s0: usize , pub s1: usize , pub s2: usize , pub s3: usize , pub s4: usize , pub s5: usize , pub s6: usize , pub s7: usize , pub s8: usize , pub s9: usize , pub s10: usize , pub s11: usize , } impl TaskContext { pub fn switch_to mut self , next_ctx: &Self ) { unsafe { context_switch(self , next_ctx) } } } #[naked] unsafe extern "C" fn context_switch mut TaskContext, _next_task: &TaskContext) { unsafe { naked_asm!( " // save old context (callee-saved registers) sd ra, 0*8(a0) sd sp, 1*8(a0) sd s0, 2*8(a0) sd s1, 3*8(a0) sd s2, 4*8(a0) sd s3, 5*8(a0) sd s4, 6*8(a0) sd s5, 7*8(a0) sd s6, 8*8(a0) sd s7, 9*8(a0) sd s8, 10*8(a0) sd s9, 11*8(a0) sd s10, 12*8(a0) sd s11, 13*8(a0) // restore new context ld s11, 13*8(a1) ld s10, 12*8(a1) ld s9, 11*8(a1) ld s8, 10*8(a1) ld s7, 9*8(a1) ld s6, 8*8(a1) ld s5, 7*8(a1) ld s4, 6*8(a1) ld s3, 5*8(a1) ld s2, 4*8(a1) ld s1, 3*8(a1) ld s0, 2*8(a1) ld sp, 1*8(a1) ld ra, 0*8(a1) ret" , ) } }
Ch6 异常和中断 Target:支持异常处理和中断处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 # Code Framework . ├── axalloc │ └── src │ ├── bitmap.rs │ ├── buddy.rs │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axdtb │ └── src │ ├── lib.rs │ └── util.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── context.rs │ │ ├── cpu.rs │ │ ├── irq.rs │ │ ├── lang_items.rs │ │ ├── mem.rs │ │ ├── misc.rs │ │ ├── paging.rs │ │ ├── time.rs │ │ ├── trap.rs │ │ └── trap.S │ └── riscv64.rs ├── axlog │ └── src │ └── lib.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ ├── lib.rs │ └── trap.rs ├── axstd │ └── src │ ├── io.rs │ ├── lib.rs │ ├── thread.rs │ └── time.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── axtask │ └── src │ ├── lib.rs │ ├── run_queue.rs │ ├── task.rs │ └── wait_queue.rs ├── bitmap_allocator │ └── src │ └── lib.rs ├── buddy_allocator │ └── src │ ├── lib.rs │ ├── linked_list │ │ └── tests.rs │ └── linked_list.rs ├── handler_table │ └── src │ └── lib.rs ├── kernel_guard │ └── src │ └── lib.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs ├── noirq.rs └── raw.rs
一、异常处理 按照 RiscV 规范,异常和中断被触发时,当前的执行流程被打断,跳转到异常向量表中相应的例程进行处理。其中,stvec 寄存器指向的是向量表的基地址,scause 寄存器记录的异常编号则作为例程入口的偏移,二者相加得到异常处理例程的最终地址。
我们将准备一个符合规范的异常向量表,在异常中断处理前后分别需要保存和恢复原始的上下文,我们称之为异常上下文.与常见的宏内核陷阱处理不同,这段代码没有将栈指针切换到专用的监督者栈,而是继续使用原始栈保存上下文,这是因为arceos的宏内核设计,没有进行用户态和内核态的区分
trap处理流程:
1 2 3 4 5 6 sequenceDiagram CPU->>Trap入口: 触发中断 Trap入口->>Trap分发器: 保存上下文 Trap分发器->>IRQ处理表: 查找处理函数 IRQ处理表->>设备驱动: 调用注册的handler 设备驱动->>Trap返回: 处理完成
1 2 3 4 5 6 7 8 9 10 11 12 // axhal/src/riscv/trap.S .section .text .balign 4 .global trap_vector_base trap_vector_base: csrrw sp, sscratch, sp // switch sscratch and sp csrr sp, sscratch // put supervisor sp back SAVE_REGS mv a0, sp call riscv_trap_handler RESTORE_REGS sret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 unsafe extern "C" fn rust_entry usize , _dtb: usize ) { unsafe extern "C" { fn trap_vector_base fn rust_main usize , dtb: usize ); } unsafe { trap::set_trap_vector_base(trap_vector_base as usize ); rust_main(_hartid, _dtb); } } #[unsafe(no_mangle)] fn riscv_trap_handler mut TrapFrame) { let scause = scause::read(); match scause.cause() { Trap::Exception(3 ) => handle_breakpoint(&mut tf.sepc), Trap::Interrupt(_) => handle_irq_extern(scause.bits()), _ => { panic! ( "Unhandled trap {:?} @ {:#x}:\n{:#x?}" , scause.cause(), tf.sepc, tf ); } } } fn handle_breakpoint mut usize ) { debug!("Exception(Breakpoint) @ {:#x} " , sepc); *sepc += 2 } #[def_interface] pub trait TrapHandler fn handle_irq usize ); } #[allow(dead_code)] pub (crate ) fn handle_irq_extern usize ) { call_interface!(TrapHandler::handle_irq, irq_num); }
二、启用自旋锁 在真正开启和处理中断之前,我们首先需要实现真正的自旋锁。
现在一旦启用中断,就会引起两种新的可能性:
当正常执行程序时,会随时被外部的中断而打断运行,然后就会去执行响应中断的例程。中断是随机不可预测的,这样有可能会把原本处于临界区中的一组操作打断,破坏它们的原子性、事务性。
虽然已经支持多任务并发,但这种并发是协作式的,即只有一个任务主动让出执行权时,另一个任务才能执行。因此,调度时机是可以协调的,完全可以避免打破临界区。但是下一步我们将基于时钟中断支持抢占式的并发,即任务调度可能随时发生,或许当前任务正好处于临界区中。
为了杜绝上述两种可能性,我们需要重构新的自旋锁。根据上面的分析,其实我们只要在锁期间,关闭中断即可。为了支持自旋锁的实现,我们引入新的组件kernel_guard分别应对以下情况:四种核心保护类型:
类型
功能描述
适用场景
NoOp空操作保护
无同步要求的代码路径
IrqSave中断禁用 + 状态保存
单核中断敏感操作
NoPreempt抢占禁用
防止任务切换的临界区
NoPreemptIrqSave中断禁用 + 抢占禁用(组合保护)
多核/复杂同步场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 #![no_std] #[crate_interface::def_interface] pub trait KernelGuardIf fn enable_preempt fn disable_preempt } pub trait BaseGuard type State Clone + Copy ; fn acquire fn release } pub struct NoOp pub struct IrqSave usize );pub struct NoPreempt pub struct NoPreemptIrqSave usize );impl BaseGuard for NoOp { type State fn acquire fn release } impl NoOp { pub const fn new Self { Self } } impl Drop for NoOp { fn drop mut self ) {} } impl BaseGuard for IrqSave { type State usize ; #[inline] fn acquire arch::local_irq_save_and_disable() } #[inline] fn release arch::local_irq_restore(state); } } impl BaseGuard for NoPreempt { type State fn acquire } fn release } } impl BaseGuard for NoPreemptIrqSave { type State usize ; fn acquire arch::local_irq_save_and_disable() } fn release arch::local_irq_restore(state); } } #[cfg(target_arch = "riscv64" )] mod arch { use core::arch::asm; const SIE_BIT: usize = 1 << 1 ; #[inline] pub fn local_irq_save_and_disable usize { let flags: usize ; unsafe { asm!("csrrc {}, sstatus, {}" , out(reg) flags, const SIE_BIT) }; flags & SIE_BIT } #[inline] pub fn local_irq_restore usize ) { unsafe { asm!("csrrs x0, sstatus, {}" , in (reg) flags) }; } } #[cfg(not(target_arch = "riscv64" ))] mod arch { pub fn local_irq_save_and_disable usize { unimplemented! () } pub fn local_irq_restore usize ) { unimplemented! (); } }
借助kernel_guard实现自旋锁,lock()后返回guard,通过guard访问data:
生命周期绑定 :将锁的有效期与守卫对象的生命周期绑定安全访问代理 :通过 Deref/DerefMut 提供对受保护数据的透明访问资源自动释放 :在 Drop 时恢复中断和抢占状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 impl <T> SpinNoIrq<T> { #[inline(always)] pub fn lock self ) -> SpinNoIrqGuard<T> { let irq_state = NoPreemptIrqSave::acquire(); SpinNoIrqGuard { irq_state, data: unsafe { &mut *self .data.get() }, } } } impl <T> Deref for SpinNoIrqGuard<T> { type Target #[inline(always)] fn deref self ) -> &T { unsafe { &*self .data } } } impl <T> DerefMut for SpinNoIrqGuard<T> { #[inline(always)] fn deref_mut mut self ) -> &mut T { unsafe { &mut *self .data } } } impl <T> Drop for SpinNoIrqGuard<T> { #[inline(always)] fn drop mut self ) { NoPreemptIrqSave::release(self .irq_state); } }
三、启用时钟中断 我们首先启用最简单的时钟中断,在axruntime调用init_interrupt前首先为启用中断做准备,进行平台初始化(将timer设为0,启用中断后马上发生首次时钟中断),然后调用init_interrupt具体是需要提供一个能够处理中断的函数给register_handler,handler将全局TIMER_HANDLER初始化为该函数。中断发生后,trap_handler调用借助crate_interface实现的函数(这里没有理解为什么使用crate_interface,没有发现循环依赖,直接调用函数也可以实现),这个函数调用dispatch_irq,然后再调用init_interrupt提供的函数,并设置下次时钟中断的时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 #[cfg(all(target_os = "none" , not(test)))] fn init_interrupt use axhal::irq::TIMER_IRQ_NUM; const PERIODIC_INTERVAL_NANOS: u64 = axhal::time::NANOS_PER_SEC / axconfig::TICKS_PER_SEC as u64 ; static mut NEXT_DEADLINE: u64 = 0 ; fn update_timer let now_ns = axhal::time::current_time_nanos(); let mut deadline = unsafe { NEXT_DEADLINE }; if now_ns >= deadline { deadline = now_ns + PERIODIC_INTERVAL_NANOS; } unsafe { NEXT_DEADLINE = deadline + PERIODIC_INTERVAL_NANOS }; trace!("now {} deadline {}" , now_ns, deadline); axhal::time::set_oneshot_timer(deadline); } axhal::irq::register_handler(TIMER_IRQ_NUM, || { update_timer(); debug!("On timer tick!" ); }); axhal::irq::enable_irqs(); } pub fn register_handler usize , handler: IrqHandler) -> bool { match scause { S_TIMER => { if !TIMER_HANDLER.is_init() { TIMER_HANDLER.init(handler); true } else { false } } S_EXT => crate::irq::register_handler_common(scause & !INTC_IRQ_BASE, handler), _ => panic! ("invalid trap cause: {:#x}" , scause), } } #[unsafe(no_mangle)] fn riscv_trap_handler mut TrapFrame) { let scause = scause::read(); match scause.cause() { Trap::Exception(3 ) => handle_breakpoint(&mut tf.sepc), Trap::Interrupt(_) => handle_irq_extern(scause.bits()), _ => { panic! ( "Unhandled trap {:?} @ {:#x}:\n{:#x?}" , scause.cause(), tf.sepc, tf ); } } } #[def_interface] pub trait TrapHandler fn handle_irq usize ); } #[allow(dead_code)] pub (crate ) fn handle_irq_extern usize ) { call_interface!(TrapHandler::handle_irq, irq_num); } #[cfg(all(target_os = "none" , not(test)))] struct TrapHandlerImpl #[cfg(all(target_os = "none" , not(test)))] #[crate_interface::impl_interface] impl axhal::trap::TrapHandler for TrapHandlerImpl { fn handle_irq usize ) { axhal::irq::dispatch_irq(irq_num); } } pub fn dispatch_irq usize ) { match scause { S_TIMER => { log::trace!("IRQ: timer" ); TIMER_HANDLER.get()(); } S_EXT => { crate::irq::dispatch_irq_common(0 ); } _ => panic! ("invalid trap cause: {:#x}" , scause), } }
Ch7 抢占式调度 Target: 支持抢占调度和mutex锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 # Code Framework . ├── axalloc │ └── src │ ├── bitmap.rs │ ├── buddy.rs │ ├── early │ │ └── tests.rs │ ├── early.rs │ └── lib.rs ├── axconfig │ └── src │ └── lib.rs ├── axdtb │ └── src │ ├── lib.rs │ └── util.rs ├── axhal │ ├── linker.lds │ └── src │ ├── lib.rs │ ├── riscv64 │ │ ├── boot.rs │ │ ├── console.rs │ │ ├── context.rs │ │ ├── cpu.rs │ │ ├── irq.rs │ │ ├── lang_items.rs │ │ ├── mem.rs │ │ ├── misc.rs │ │ ├── paging.rs │ │ ├── time.rs │ │ ├── trap.rs │ │ └── trap.S │ └── riscv64.rs ├── axlog │ └── src │ └── lib.rs ├── axorigin │ └── src │ └── main.rs ├── axruntime │ └── src │ ├── lib.rs │ └── trap.rs ├── axstd │ └── src │ ├── io.rs │ ├── lib.rs │ ├── sync │ │ ├── mod.rs │ │ └── mutex.rs │ ├── thread.rs │ └── time.rs ├── axsync │ └── src │ ├── bootcell.rs │ └── lib.rs ├── axtask │ └── src │ ├── lib.rs │ ├── run_queue.rs │ ├── task.rs │ └── wait_queue.rs ├── bitmap_allocator │ └── src │ └── lib.rs ├── buddy_allocator │ └── src │ ├── lib.rs │ ├── linked_list │ │ └── tests.rs │ └── linked_list.rs ├── handler_table │ └── src │ └── lib.rs ├── kernel_guard │ └── src │ └── lib.rs ├── page_table │ └── src │ └── lib.rs └── spinlock └── src ├── lib.rs ├── noirq.rs └── raw.rs
一、抢占式调度 ArceOS 中,任务抢占采取的具体策略包括内部条件和外部条件,二者同时具备时,才能触发抢占。内部条件指的是,在任务内部维护的某种状态达到条件,例如本次运行的时间片配额耗尽;外部条件指的是,内核可以在某些阶段,暂时关闭抢占,比如,下步我们的自旋锁就需要在加锁期间关闭抢占,以保证锁范围的原子性。由此可见,这个抢占是兼顾了任务自身状况的,一个正在运行的任务即使是低优先级,在达到内部条件之前,也不会被其它任务抢占。抢占是边沿触发。在内部条件符合的前提下,外部状态从禁止抢占到启用抢占的那个变迁点,会触发一次抢占式重调度 resched。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 axhal::irq::register_handler(TIMER_IRQ_NUM, || { update_timer(); debug!("On timer tick!" ); axtask::on_timer_tick(); }); impl AxRunQueue { pub fn scheduler_timer_tick mut self ) { let curr = current(); if !curr.is_idle() && curr.task_tick() { curr.set_preempt_pending(true ); } } } impl task { pub fn task_tick self ) -> bool { let old_slice = self .time_slice.fetch_sub(1 , Ordering::Release); old_slice <= 1 } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 impl BaseGuard for NoPreempt { type State fn acquire crate_interface::call_interface!(KernelGuardIf::disable_preempt); } fn release crate_interface::call_interface!(KernelGuardIf::enable_preempt); } } impl BaseGuard for NoPreemptIrqSave { type State usize ; fn acquire crate_interface::call_interface!(KernelGuardIf::disable_preempt); arch::local_irq_save_and_disable() } fn release arch::local_irq_restore(state); crate_interface::call_interface!(KernelGuardIf::enable_preempt); } } impl task { #[inline] pub (crate ) fn disable_preempt self ) { self .preempt_disable_count.fetch_add(1 , Ordering::Relaxed); } #[inline] pub (crate ) fn enable_preempt self , resched: bool ) { if self .preempt_disable_count.fetch_sub(1 , Ordering::Relaxed) == 1 && resched { Self::current_check_preempt_pending(); } } fn current_check_preempt_pending let curr = current(); if curr.need_resched.load(Ordering::Acquire) && curr.can_preempt(0 ) { let mut rq = RUN_QUEUE.lock(); if curr.need_resched.load(Ordering::Acquire) { rq.preempt_resched(); } } } }
二、Mutex锁 我们在这里实现Mutex锁为app提供同步原语支持线程共享资源,Mutex锁的实现借助wait_queue,在锁被占用的时候将task置入wait_queue直到锁的持有者来唤醒
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 pub struct Mutex Sized > { wq: AxWaitQueueHandle, owner_id: AtomicU64, data: UnsafeCell<T>, } impl <T: ?Sized > Mutex<T> { pub fn lock self ) -> MutexGuard<T> { let current_id = super::ax_current_task_id(); loop { match self .owner_id.compare_exchange_weak( 0 , current_id, Ordering::Acquire, Ordering::Relaxed, ) { Ok (_) => break , Err (owner_id) => { assert_ne! ( owner_id, current_id, "Thread({}) tried to acquire mutex it already owns." , current_id, ); super::ax_wait_queue_wait(&self .wq, || !self .is_locked(), None ); } } } MutexGuard { lock: self , data: unsafe { &mut *self .data.get() }, } } pub unsafe fn force_unlock self ) { let owner_id = self .owner_id.swap(0 , Ordering::Release); let current_id = super::ax_current_task_id(); assert_eq! ( owner_id, current_id, "Thread({}) tried to release mutex it doesn't own" , current_id, ); super::ax_wait_queue_wake(&self .wq, 1 ); } }
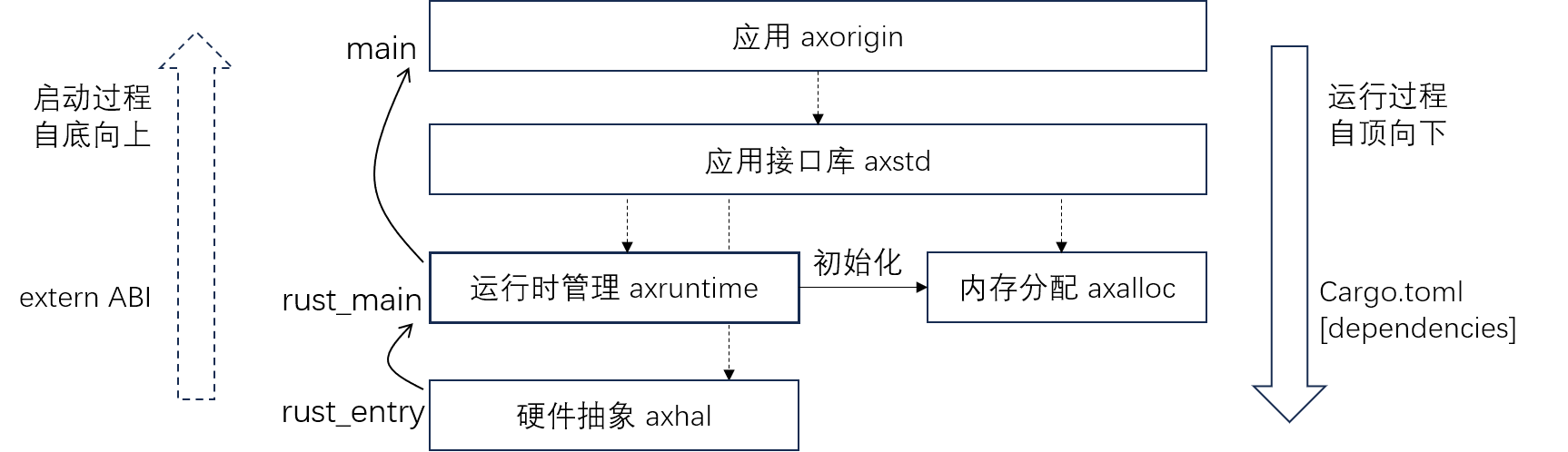
Main Record 主线arceos与tutorial思想相同,但是模块的代码有较大差别,主线arceos借助rust的包管理机制将一些模块支持组件加入到dependence中,可以像学习tutorial一样追踪arceos的启动过程,从runtime的各个初始化操作中追踪各个模块的初始化与具体功能,再过渡到各个模块间的协同配合与api封装为ulib和app提供支持。学习arceos很重要的是建立整体框架,让ai生成框架图可以更好的理解模块内部工作机制和模块间的协调合作;在理解module的框架后,复用arceos提供的api来进行更灵活快速的开发而不需要拘泥与每个模块提供的底层api细节
PS:abstract graph全部由ai生成,给出对应module的设计理念和运行逻辑提示词并让cursor理解代码框架,可以生成逻辑清晰的框架图
axconfig 通过组件axconfig-gen解析.axconfig.toml生成默认config参数
axruntime abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 graph TD A[主入口 rust_main] --> B[打印启动LOGO] B --> C[初始化日志系统] C --> E[内存管理初始化] E --> F{是否启用驱动?} F -->|fs/net/display| G[初始化驱动子系统] G --> H[初始化文件系统] G --> I[初始化网络协议栈] G --> J[初始化显示系统] F -->|无驱动需求| K[跳过驱动初始化] H & I & J & K --> L[多核启动管理] L --> M[启动从核] M --> N[等待从核就绪] N --> O[中断控制器配置] O --> P[调用全局构造器] P --> Q[进入应用main函数] subgraph 多核管理 L --> R[主核流程] M --> S[从核入口 rust_main_secondary] S --> T[从核内存初始化] T --> U[从核设备初始化] U --> V[从核调度器] V --> W[等待主核同步] W --> X[进入空闲任务] end style A fill:#cff,stroke:#333 style G fill:#cdf,stroke:#369 style L fill:#ff9,stroke:#f90 style S fill:#9f9,stroke:#090
运行时管理。在内核完成基本的 boot 之后,会将执行流交给运行 时层,初始化内核的各种功能模块,如驱动注册、任务调度队列初始化等,从而构造一个完整的内核运行时。
axlog::init()初始化日志
init_allocator遍历memory_regions初始化global_allocator(global_init)
init_memory_management初始化内核虚拟地址空间管理与细粒度内核页表
platform_initarch相关,指定 CPU 可以响应哪些类型的中断
init_scheduler初始化任务调度(初始化run_queue和timer)
init_drivers检测并初始化所有设备驱动
init_filesystems基于init_drivers发现的块设备初始化文件系统
init_interrupt初始化中断,关于中断: 中断处理调用链
init_tls在非多任务情况下(unikernel)引入线程局部存储,tls机制允许每个线程拥有自己独立的数据副本
axhal 硬件抽象层,提供了对硬件平台的抽象和适配,负责 boot 内核、时钟、 异常等硬件平台的细节处理,并为上层提供统一的硬件功能接口。
abstract graph 硬件抽象层 分层架构图
总架构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 %% 总架构图 graph TD A[axhal硬件抽象层] --> B[平台抽象层 Platform] A --> C[架构实现层 Arch] A --> D[核心HAL层 Core HAL] B --> E[Boot] B --> F[Console] B --> G[IRQ] B --> H[Memory] B --> I[Time] C --> J[aarch64] C --> K[x86_64] C --> L[riscv] C --> M[loongarch64] D --> N[Trap处理] D --> O[上下文管理] D --> P[页表管理] D --> Q[物理内存] D --> R[时钟管理] D --> S[中断控制] style A fill:#e6f3ff,stroke:#004c99 style B fill:#ffe6e6,stroke:#990000 style C fill:#e6ffe6,stroke:#009900 style D fill:#fff2cc,stroke:#d6b656
核心hal:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 %% 核心HAL层分图 graph TD D1[Trap处理] --> D11[异常分发] D1 --> D12[IRQ处理表] D1 --> D13[系统调用路由] D2[上下文管理] --> D21[任务上下文] D2 --> D22[用户空间上下文] D2 --> D23[FPU状态保存] D3[页表管理] --> D31[页表根设置] D3 --> D32[TLB刷新] D3 --> D33[地址转换] D4[物理内存] --> D41[内存区域迭代器] D4 --> D42[物理/虚拟转换] D5[时钟管理] --> D51[当前时钟ticks] D5 --> D52[定时器设置] D5 --> D53[忙等待实现] D6[中断控制] --> D61[中断使能] D6 --> D62[处理函数注册] D11 -->|调用| D12 D31 -->|影响| D32 D51 -->|转换| D52
Framework 1 2 3 4 5 6 7 8 9 10 11 axhal ├── arch # -> 体系结构相关 ├── cpu.rs # ├── irq.rs # ├── lib.rs # ├── mem.rs # ├── paging.rs # ├── platform # -> 平台相关 ├── time.rs # ├── tls.rs # └── trap.rs #
Platform:
boot.rsentry point of the kernel,初始化启动栈和启动页表consolo.rs借助sbi提供的功能实现控制台输入输出irq.rs注册中断处理函数接口,设置platform and arch相关中断号mem.rs提供platform_regions,被chain调用并调用chain,得到memory_regions
Hal:
trap.rs体系结构相关的trap处理函数,handler由中断向量表设置context.rs上下文相关操作,用于调度macros.rs定义汇编辅助宏,简化汇编代码的编写
Non-hal and non-platform:
trap.rs借助linkme使用def_trap_handler向全局数组定义trap处理函数,包括IRQ/PAGE_FAULT/SYSCALL,用户可以通过register_trap_handler注册对应的处理函数irq.rs根据中断号设置中断处理表并接受中断号调用处理paging.rs设置根页表,提供物理内存操作mem.rs定义memory_regions,提供地址转换apitime.rs提供了系统时钟和计时相关的功能,实现忙等待机制
系统调用流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 sequenceDiagram participant User participant Kernel participant axhal User->>Kernel: 系统调用指令 Kernel->>axhal: 保存用户上下文 axhal->>axhal: 权限级别切换 axhal->>Kernel: 创建TrapFrame Kernel->>处理程序: 分发系统调用 处理程序-->>Kernel: 返回结果 Kernel->>axhal: 恢复上下文 axhal->>User: 返回用户空间
support crates
linkme
handler_table
pagetable_multiarch
axns Namespace 机制实现,控制资源的隔离和共享
abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 graph TD A[AxNamespace] --> B[全局命名空间] A --> C[线程本地命名空间] B --> D[[axns_resource内存段]] B --> E("alloc: false") B --> F("AxNamespace::global()") C --> G[动态分配内存] C --> H("alloc: true") C --> I("new_thread_local()") C --> J["copy_nonoverlapping(全局资源)"] K[ResArc<T>] --> L[Arc<T>包装] K --> M["init_new()/init_shared()"] N[def_resource!宏] --> O["static资源定义"] O --> D P[线程1] -->|访问| C P -->|修改| Q[独立资源副本] R[线程2] -->|访问| B R -->|修改| S[全局共享资源] style B fill:#e6f3ff,stroke:#004c99 style C fill:#e6ffe6,stroke:#009900 style K fill:#ffe6e6,stroke:#990000 style N fill:#fff2cc,stroke:#d6b656 subgraph 核心数据结构 A K end subgraph 资源存储 D G end subgraph 线程隔离 P R Q S end
Data Structure 1 2 3 4 5 6 7 pub struct AxNamespace base: usize , alloc: bool , }
axalloc 实例化内存分配器,负责物理页的分配和回收,支持 Buddy 分配算 法、Slab 分配算法等
abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 graph TD A[GlobalAllocator] -->|包含| B["SpinNoIrq<DefaultByteAllocator> (字节分配器)"] A -->|包含| C["SpinNoIrq<BitmapPageAllocator> (页分配器)"] B --> D{feature选择} D -->|slab| E[SlabByteAllocator] D -->|buddy| F[BuddyByteAllocator] D -->|tlsf| G[TlsfByteAllocator] C --> H[[BitmapPageAllocator]] H --> I[allocator::Bitmap] H --> J[PAGE_SIZE=4K] A -->|实现| K[core::alloc::GlobalAlloc] K --> L[alloc/dealloc] M[GlobalPage] -->|使用| N[alloc_pages] M -->|使用| O[dealloc_pages] N & O --> C style A fill:#f0f8ff,stroke:#4682b4 style D fill:#fffacd,stroke:#daa520 style H fill:#e6e6fa,stroke:#9370db style K fill:#f5f5dc,stroke:#deb887 subgraph 分配器实现层 B C end subgraph 算法选择层 D E F G end subgraph 标准库接口 K L end subgraph 物理页管理 H I J end
Data Structure 1 2 3 4 5 6 7 8 pub struct GlobalAllocator balloc: SpinNoIrq<DefaultByteAllocator>, palloc: SpinNoIrq<BitmapPageAllocator<PAGE_SIZE>>, }
使用Bitmap作为数据结构实现页内存分配器 ,使用feature选择使用slab,buddy,tlfs作为字节内存分配器,通过impl GlobalAlloc实现alloc和dealloc支持GlobalAllocator
axmm abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 graph TD A[AddrSpace] --> B[va_range: VirtAddrRange] A --> C[areas: MemorySet] A --> D[pt: PageTable] C --> E[MemoryArea] E --> F[Backend] F --> G[Linear] F --> H[Alloc] G -->|固定偏移| I[物理地址计算] H -->|动态分配| J[axalloc全局分配器] A --> K[页表操作] K --> L[page_table_multiarch] M[memory_addr] -->|地址转换| A N[memory_set] -->|区域管理| C style A fill:#e6f3ff,stroke:#004c99 style F fill:#ffe6e6,stroke:#990000 style G fill:#e6ffe6,stroke:#009900 style H fill:#e6ffe6,stroke:#009900 style L fill:#fff2cc,stroke:#d6b656 subgraph axmm模块 A B C D E F G H end subgraph 依赖crates L M N end
Data structure 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 pub struct AddrSpace va_range: VirtAddrRange, areas: MemorySet<Backend>, pt: PageTable, } #[derive(Clone)] pub enum Backend Linear { pa_va_offset: usize , }, Alloc { populate: bool , }, } impl MappingBackend for Backend { type Addr type Flags type PageTable ... }
axmm使用AddrSpace管理地址空间,va_range记录虚拟地址范围,areas通过BtreeMap管理虚拟地址范围内的已映射空间,每个area backend可以使用linear和alloc两种方式进行管理
support crates
memory_addr
memory_set
page_table_multiarch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 pub struct AddrRange pub start: A, pub end: A, } pub type VirtAddrRange pub type PhysAddrRange impl <T> MemoryAddr for T where T: Copy + From <usize > + Into <usize > + Ord {}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pub struct MemorySet areas: BTreeMap<B::Addr, MemoryArea<B>>, } pub struct MemoryArea va_range: AddrRange<B::Addr>, flags: B::Flags, backend: B, }
1 2 3 4 5 6 7 8 9 10 pub struct PageTable64 root_paddr: PhysAddr, _phantom: PhantomData<(M, PTE, H)>, }
axtask 任务管理模块,定义内核的调度单元结构,并且实现了任务调度的相关功能,如任务创建、任务切换、任务唤醒等。它是内核的核心模块,负责 管理和调度所有的任务
abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 graph TD %% 核心结构 AxTask["AxTask (Wrapper)"] TaskInner["TaskInner (核心任务结构)"] AxTaskRef["AxTaskRef (Arc<AxTask>)"] TaskExt["AxTaskExt (任务扩展数据)"] %% 队列和调度器 RunQueue["AxRunQueue (运行队列)"] WaitQueue["WaitQueue (等待队列)"] Scheduler["Scheduler (调度器)"] %% 调度器实现 FIFO["FIFO调度器 (不可抢占)"] RR["RR调度器 (可抢占)"] CFS["CFS调度器 (可抢占)"] %% 定时器相关 TimerList["timer_list (最小堆事件管理)"] Timers["timers模块 (定时器管理)"] %% 关系连接 TaskInner -->|包含| TaskExt AxTask -->|封装| TaskInner AxTaskRef -->|Arc包装| AxTask RunQueue -->|管理| AxTaskRef RunQueue -->|使用| Scheduler Scheduler -->|根据feature选择| FIFO Scheduler -->|根据feature选择| RR Scheduler -->|根据feature选择| CFS WaitQueue -->|存储阻塞| AxTaskRef WaitQueue -->|唤醒时通过| RunQueue Timers -->|使用| TimerList Timers -->|设置任务timer_ticket_id| TaskInner TaskInner -->|timer_ticket_id标识定时事件| Timers %% 功能流程 InitScheduler[/"init_scheduler()"/] InitScheduler -->|创建| RunQueue RunQueue -->|初始化| IdleTask[/"idle task"/] RunQueue -->|初始化| MainTask[/"main task"/] %% 任务状态转换 TaskState{{"任务状态"}} TaskState -->|Running| Running["运行中"] TaskState -->|Ready| Ready["就绪"] TaskState -->|Blocked| Blocked["阻塞"] TaskState -->|Exited| Exited["已退出"] %% 定时器和中断处理 InterruptHandler["中断处理"] InterruptHandler -->|时钟中断| Timers Timers -->|超时唤醒| AxTaskRef %% SMP支持 SMP["SMP支持"] SMP -->|多核调度| RunQueue RunQueue -->|任务迁移| MigrateTask["任务迁移"] %% 抢占支持 Preemption["抢占机制"] RR -->|时间片耗尽| Preemption CFS -->|更高优先级任务| Preemption Preemption -->|设置need_resched| TaskInner %% 任务等待和唤醒 WaitTimeout["wait_timeout()"] WaitTimeout -->|设置超时| Timers WaitTimeout -->|阻塞任务| WaitQueue Notify["notify_one/all()"] Notify -->|唤醒任务| WaitQueue WaitQueue -->|取消定时器| Timers
Data structure 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 pub struct TaskInner id: TaskId, name: UnsafeCell<String >, is_idle: bool , is_init: bool , entry: Option <*mut dyn FnOnce ()>, state: AtomicU8, cpumask: SpinNoIrq<AxCpuMask>, in_wait_queue: AtomicBool, #[cfg(feature = "smp" )] on_cpu: AtomicBool, #[cfg(feature = "irq" )] timer_ticket_id: AtomicU64, #[cfg(feature = "preempt" )] need_resched: AtomicBool, #[cfg(feature = "preempt" )] preempt_disable_count: AtomicUsize, exit_code: AtomicI32, wait_for_exit: WaitQueue, kstack: Option <TaskStack>, ctx: UnsafeCell<TaskContext>, task_ext: AxTaskExt, #[cfg(feature = "tls" )] tls: TlsArea, } percpu_static! { RUN_QUEUE: LazyInit<AxRunQueue> = LazyInit::new(), EXITED_TASKS: VecDeque<AxTaskRef> = VecDeque::new(), WAIT_FOR_EXIT: WaitQueue = WaitQueue::new(), IDLE_TASK: LazyInit<AxTaskRef> = LazyInit::new(), #[cfg(feature = "smp" )] PREV_TASK: Weak<crate::AxTask> = Weak::new(), } pub (crate ) struct AxRunQueue cpu_id: usize , scheduler: SpinRaw<Scheduler>, } pub struct WaitQueue queue: SpinNoIrq<VecDeque<AxTaskRef>>, } pub (crate ) type WaitQueueGuard 'a > = SpinNoIrqGuard<'a , VecDeque<AxTaskRef>>
初始化时init_scheduler首先初始化运行队列,运行队列初始化一个idle task和一个main task,他们一个作为空闲系统任务,一个作为系统主逻辑入口,工作流程
根据feature对每个task使用对应调度方法封装为节点axtask,使用对应scheduler进行调度fifo为不可抢占,rr和cfs为可抢占
中断:main arceos的中断与tutorial类似但是框架组织有所差别使其能够支持smp,tutorial将time_slice直接嵌入在taskinner中,main arceos将其封装为timer_list dependence crate和timer mod,其中timer_list使用最小堆管理事件,timer mod对其功能进行封装,使用timer_ticket_id标示定时器
抢占:根据不同的scheduler进行抢占设置
support crates
axdriver 驱动管理模块,负责接入不同来源的设备,并为用户提供统一的驱 动功能调用接口,如块设备、网络设备和显示设备
abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 graph TD A[应用层] -->|调用| B[init_drivers] B --> C[AllDevices::probe] C --> D[全局设备探测] C --> E[总线设备探测] D -->|for_each_drivers!宏| F[DriverProbe::probe_global] E -->|PCI/MMIO| G[bus模块探测] subgraph axdriver核心结构 B --> H[AllDevices] H --> I[AxDeviceContainer<AxNetDevice>] H --> J[AxDeviceContainer<AxBlockDevice>] H --> K[AxDeviceContainer<AxDisplayDevice>] end subgraph 设备容器实现 I -->|dyn启用| L[Vec<Box<dyn NetDriverOps>>] I -->|静态类型| M[Option<具体网卡类型>] J -->|dyn启用| N[Vec<Box<dyn BlockDriverOps>>] J -->|静态类型| O[Option<具体块设备类型>] end subgraph 驱动注册 F --> P[register_net_driver!] F --> Q[register_block_driver!] P --> R[VirtioNet/Ixgbe/FXmac] Q --> S[VirtioBlk/RamDisk] end G -->|PCI总线扫描| T[pci.rs] G -->|MMIO设备树解析| U[mmio.rs] T --> V[配置PCI BAR空间] U --> W[映射MMIO区域] style B fill:#e6f3ff,stroke:#004c99 style H fill:#e6f3ff,stroke:#004c99 style I fill:#e6f3ff,stroke:#004c99 style T fill:#ffe6e6,stroke:#990000 style U fill:#ffe6e6,stroke:#990000
Data structure 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #[derive(Default)] pub struct AllDevices #[cfg(feature = "net" )] pub net: AxDeviceContainer<AxNetDevice>, #[cfg(feature = "block" )] pub block: AxDeviceContainer<AxBlockDevice>, #[cfg(feature = "display" )] pub display: AxDeviceContainer<AxDisplayDevice>, } pub struct AxDeviceContainer Option <D>) pub struct AxDeviceContainer Vec <D>)
AxDeviceContainer包含特定类别的设备驱动结构体。如果启用了 dyn 功能,则内部类型为 [Vec<D>]。否则内部类型为 [Option<D>],并且最多可包含一个设备;static静态分发的类型定义通过register_drivers宏实现,dyn动态分发的类型定义通过Box封装trait对象
初始化时先使用for each drivers和probe_global初始化全局设备驱动,再通过self.probe_bus_devices()初始化总线设备
[!CAUTION]
静态分发 (static.rs)
动态分发 (dyn.rs)
特征
全局设备
总线设备
硬件连接方式
板载集成
通过PCI/PCIe/USB等总线连接
地址发现机制
固定地址或配置文件指定
通过总线枚举发现
典型设备示例
RAM磁盘、GPIO控制器
网卡、显卡、USB控制器
热插拔支持
不支持
支持(依赖总线类型)
代码复杂度
较低(直接初始化)
较高(需要处理总线协议)
特征
MMIO
PCI
发现机制
预定义内存区域扫描
总线枚举+配置空间读取
地址分配
固定物理地址
动态分配BAR空间
配置方式
直接内存读写
通过配置空间寄存器
典型应用场景
嵌入式系统/VirtIO虚拟设备
物理服务器/标准PC硬件
设备识别
魔数检查(如0x74726976=”virt”)
厂商ID+设备ID检查
中断配置
通常固定中断号
MSI/MSI-X动态中断分配
support crates
axfs 文件系统模块,负责接入不同来源的文件系统,并为用户提供统一的 文件系统功能调用接口,如文件读写、目录操作等。
abstract graph 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 graph TD A[应用层] -->|系统调用| B(api模块) B -->|封装操作| C(fops模块) C -->|路径解析| D(root模块) D -->|主文件系统| E1(fatfs/lwext4) D -->|挂载管理| E2(devfs) D -->|挂载管理| E3(ramfs) D -->|挂载管理| E4(procfs) E1 -->|块设备操作| F(dev模块) E2 -->|虚拟设备| F E3 -->|内存管理| F C -->|权限检查| G[Capability系统] D -->|VFS接口| H[VFS抽象层] H -->|具体实现| E1 H -->|具体实现| E2 H -->|具体实现| E3 F -->|硬件交互| I[块设备驱动] classDef box fill:#e6f3ff,stroke:#004c99; class A,B,C,D,E1,E2,E3,E4,F,G,H,I box;
Data structure 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 struct MountPoint path: &'static str , fs: Arc<dyn VfsOps>, } struct RootDirectory main_fs: Arc<dyn VfsOps>, mounts: RwLock<Vec <MountPoint>>, } static ROOT_DIR: LazyInit<Arc<RootDirectory>> = LazyInit::new()pub struct Disk block_id: u64 , offset: usize , dev: AxBlockDevice, } pub struct File node: WithCap<VfsNodeRef>, is_append: bool , offset: u64 , } pub struct Directory node: WithCap<VfsNodeRef>, entry_idx: usize , }
axfs基于axdriver初始化得到的块设备进行初始化,根据指定的feature初始化ROOT_DIR,再基于已经实现的devfs
具体的文件系统实现基于已经实现的axfs_vfs crates,其提供了对文件操作VfsOps和VfsNodeOps的上层抽象,再通过复用已有的文件系统,并对其封装vfs操作,使其适配arceos
具体核心操作抽象层,具体实现在fops.rs中,其定义了struct file 和 struct directory向上提供标准API,向下对接具体文件系统实现是文件系统的核心枢纽
support crates
axfs_vfs
axfs_devfs
axfs_ramfs
fatfs
lwext4_rust
axnet 网络兼容模块,通过调用网络设备的功能,来实现网络协议栈对内核 的兼容,并为上层提供统一的网络功能调用接口。
axdma 提供符合DMA硬件要求的物理连续、缓存一致的内存区域。DMA控制器需直接访问物理连续的内存块,确保无需CPU分页即可传输数据。同时处理CPU虚拟地址、物理地址与设备总线地址之间的映射关系。为ixgbe等驱动的实现提供支持
axsync 同步原语模块,它基于 axtask 模块,提供了对内核的同步原语的支 持,如信号量、互斥锁、读写锁等
support crates
axlog 日志组件
Appendix A: Makefile Appendix B: Linker.lds.S
段名
内容
起始符号
结束符号
对齐
.text
代码(指令)
_stext_etext4KB
.rodata
只读数据
_srodata_erodata4KB
.init_array
初始化函数数组
__init_array_start__init_array_end16B
.data
已初始化数据
_sdata_edata4KB
.tdata/.tbss
线程本地存储
_stdata/_stbss_etdata/_etbss16B
.percpu
每 CPU 数据
_percpu_start_percpu_end64B
.bss
未初始化数据 + 启动栈
_sbss_ebss4KB