RUST语言学习和Rcore实验感想
写在前面
这篇博客可能长度有点长(逃),因为之前没get到要求,以为blog是从二阶段才开始要写hhhh,所以从来没写过就是了hhh~~
这篇blog的主要内容是将我在学习RUST期间所做的笔记做一个整理(主要是来自于RUST语言圣经的节选)以便于自己后续回顾,以及将RUSTLINGS习题集中一些值得标注的语法问题做了记录。
:cry:二阶段得好好写了hhhh
RUST语言圣经笔记
数据类型
数据类型
- 数值类型: 有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数- Nan表示未被定义的结果
- debug模式检查整数溢出,release不会管
- 浮点数不支持判等(eq操作未实现)
- 字符串:字符串字面量和字符串切片
&str - 布尔类型:
true和false,1个字节 - 字符类型: 表示单个 Unicode 字符,存储为 4 个字节
- 单元类型: 即
(),其唯一的值也是()
一般来说不用显式声明,RUST编译器有变量推导
比较逆天的话就不行了……
1
2
3
4
5
6
7
8
9let guess = "42".parse().expect("Not a number!");//推导不了
//确定类型的三种方式
// 编译器会进行自动推导,给予twenty i32的类型
let twenty = 20;
// 类型标注
let twenty_one: i32 = 21;
// 通过类型后缀的方式进行类型标注:22是i32类型
let twenty_two = 22i32;- 数值类型: 有符号整数 (
序列
生成连续值,只允许用于数字和字符类型(编译器可在编译期确定类型和判空)
1
2
3
4
5
6
7for i in 1..=5 {
println!("{}",i);
}
for i in 'a'..='z' {
println!("{}",i);
}函数
1 | fn add(i: i32, j: i32) -> i32 { |
特殊返回类型
无返回值
- 函数没有返回值,那么返回一个
() - 通过
;结尾的语句返回一个()
- 函数没有返回值,那么返回一个
发散函数:永不返回
用
!作为函数的返回类型
所有权和借用
C和RUST的内存管理差别
1
2
3
4
5
6
7
8int* foo() {
int a; // 变量a的作用域开始
a = 100;
char *c = "xyz"; // 变量c的作用域开始
return &a;
} // 变量a和c的作用域结束
//a是常数,被放在栈里,函数返回时出栈,a被回收,&a是悬空指针
//c是字符串常量,在常量区,整个程序结束之后才会回收常量区所有权规则
Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16let x = 5;
let y = x;
//浅拷贝,两个变量都依然有效
let s1 = String::from("hello");
let s2 = s1;
//变量移动,默认是只copy指针,不会复制其实际内容
//s1失效,s2接管那片内存空间
let s1 = String::from("hello");
let s2 = s1.clone();
//你真想赋值的时候复制其内容,用clone()方法
let x: &str = "hello, world";
let y = x;
//浅拷贝,"hello, world"是字符串字面量Copy特征:一个旧的变量在被赋值给其他变量后仍然可用,也就是赋值的过程即是拷贝的过程。任何基本类型的组合可以
Copy,不需要分配内存或某种形式资源的类型是可以Copy的。- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是 - 不可变引用
&T,例如转移所有权中的最后一个例子,但是注意: 可变引用&mut T是不可以 Copy的
函数传值和返回——所有权的不断变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给
// 调用它的函数
let some_string = String::from("hello"); // some_string 进入作用域.
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);//传入的是引用而不是所有权
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()//拿到的是引用,因此函数结束的时候不会释放所有权
}
————————————————
//引用默认不可变(就是你不能动你借用的东西的值)
fn main() {
let mut s = String::from("hello");//可变引用(可以修改借用的东西)
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
————————————————
//在同一个作用域只可以存在一个可变引用(互斥锁懂我意思吧……)
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;//r1的作用域还没寄,你怎么也搞个可变
println!("{}, {}", r1, r2);
————————————————
//可变和不可变引用不能同时存在
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);引用的作用域
s从创建开始,一直持续到它最后一次使用的地方,这个跟变量的作用域有所不同,变量的作用域从创建持续到某一个花括号结束。1
2
3
4
5
6
7
8
9
10
11
12
13fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2);
// 新编译器中,r1,r2作用域在这里结束
let r3 = &mut s;
println!("{}", r3);
} // 老编译器中,r1、r2、r3作用域在这里结束
// 新编译器中,r3作用域在这里结束
//Non-Lexical Lifetimes(NLL)特性:用于寻找到某个引用在`}`之前就不再被使用的位置悬垂引用在Rust是不会存在的,因为当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
1
2
3
4
5
6
7
8
9
10fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s//悬垂引用,会报错
//解决办法是直接返回s,也就是交出其所有权
}
复合类型
字符串和切片
Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4)。
为啥
String可变,而字符串字面值str却不可以?就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行的过程中动态生成的。
String和&str的转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//从&str生成String
String::from("hello,world")
"hello,world".to_string()
//String到&str 取切片即可
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}字符串索引(Rust不支持)
1
2
3
4
5let s1 = String::from("hello");
let hello = String::from("中国人");
let h = s1[0];
let h = hello[0];
//不同字符的编码长度是不一样的,英文是1byte,中文是3byte,对特定单元的索引不一定有意义还有一个原因导致了 Rust 不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是 O(1),然而对于
String类型来说,无法保证这一点,因为 Rust 可能需要从 0 开始去遍历字符串来定位合法的字符。字符串的区间切片Rust是支持的,但是必须谨慎
1
2let hello = "中国人";
let s = &hello[0..2];常见字符串操作
追加和插入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//追加
fn main() {
let mut s = String::from("Hello ");//mut!
s.push_str("rust");//追加字符串
s.push('!');//追加单字符
}
//插入 insert需要插入位置和内容 位置越界会报错
fn main() {
let mut s = String::from("Hello rust!");//mut!
s.insert(5, ',');
s.insert_str(6, " I like");
}替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//返回一个新的字符串,而不是操作原来的字符串!!!
//replace 参数是:被替换内容,用来替换的内容
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
}
//replacen 和前面差不多,不过是替换n个匹配到的
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}
//方法是直接操作原来的字符串,不会返回新的字符串!!!
//replace_range 替换特定范围
fn main() {
let mut string_replace_range = String::from("I like rust!");//mut!!!
string_replace_range.replace_range(7..8, "R");
}删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36//直接操作原来的字符串 mut!!!
//pop 删除并返回最后一个字符 由于不确保存在,返回的是Option()类型 需要具体考察
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
}
//remove 删除指定位置的一个字符 注意给的索引要合法(表示字符的起始位置)
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}
//truncate 从当前位置直接删除到结尾 注意给的索引
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
}
//clear 清空
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//+或+= +右边的必须是切片引用类型
//返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}
//format!() 格式化输出
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}
元组
1 | //模式匹配解构元组 |
结构体
结构体语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58//创建
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
//初始化 每个字段都要初始化
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
//通过.来访问结构体内部字段
let mut user1 = User { //要改的话还是要mut
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
//当函数参数和结构体字段名称一样时,可以简写
fn build_user(email: String, username: String) -> User {
User {
email,
username,//缩略的初始化
active: true,
sign_in_count: 1,
}
}
//更新
let user2 = User {
email: String::from("another@example.com"),
..user1 //未显式声明的字段都会从user1中获取 不过..user1只可以写在末尾
};//也就是说你要赋值的写在前面
//更新过程可能会有某些字段发生了所有权的转移,不会影响其他字段的访问
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);元组结构体
为整个结构体提供名称,而字段不需要
1
2
3
4
5struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);单元结构体:没有任何字段和属性的结构体
枚举
任何数据类型都可以放到枚举中
1
2
3
4
5
6
7
8
9
10
11enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(char),//定义枚举成员时关联数据
Hearts(char),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds('A');
}枚举和结构体的对比
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//使用枚举来定义这些消息
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move{x:1,y:1};
let m3 = Message::ChangeColor(255,255,0);
}
//使用结构体来定义这些消息
struct QuitMessage; // 单元结构体
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // 元组结构体
struct ChangeColorMessage(i32, i32, i32); // 元组结构体
//由于每个结构体都有自己的类型,因此我们无法在需要同一类型的地方进行使用,例如某个函数它的功能是接受消息并进行发送,那么用枚举的方式,就可以接收不同的消息,但是用结构体,该函数无法接受 4 个不同的结构体作为参数。取代NULL的方式——Option()枚举
1
2
3
4
5
6
7
8
9
10
11
12
13
14//Option()枚举定义
enum Option<T> {
Some(T), //T可以是任何类型
None,
}
//示例
——————————————
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;
//当有个None值时,你需要告诉编译器T的类型,因为编译器无法通过None来推断本来应该是什么Option()枚举的好处
1
2
3
4let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;//报错!Option(i8)和i8并不是同一种类型当在 Rust 中拥有一个像
i8这样类型的值时,编译器确保它总是有一个有效的值,我们可以放心使用而无需做空值检查。只有当使用Option<i8>(或者任何用到的类型)的时候才需要担心可能没有值,而编译器会确保我们在使用值之前处理了为空的情况。换句话说,在对
Option<T>进行T的运算之前必须将其转换为T。通常这能帮助我们捕获到空值最常见的问题之一:期望某值不为空但实际上为空的情况。match表达式可以用于处理枚举
1
2
3
4
5
6
7
8
9
10fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}//如果接收到Some(i)类型,将其中的变量绑定到i上,计算i+1,再将其用Some()包裹
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
数组
创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//RUST的数组是定长的,被存储在栈上
//变长的动态数组被存储在堆上
//数组的长度也是类型的一部分
let a: [i32; 5] = [1, 2, 3, 4, 5];
//声明多个重复值
let a = [3; 5];
//非基础类型数组的创建
//这样子写会报错,本质还是因为string不能浅拷贝
let array = [String::from("rust is good!"); 8];
//这样子写可以,但是很难看
let array = [String::from("rust is good!"),String::from("rust is good!"),String::from("rust is good!")];
//遇到非基本类型数组 调用std::array::from_fn
let array: [String; 8] = std::array::from_fn(|_i| String::from("rust is good!"));支持索引访问,如果越界会崩溃
流程控制
1 | fn main() { |
| 使用方法 | 等价使用方式 | 所有权 |
|---|---|---|
for item in collection |
for item in IntoIterator::into_iter(collection) |
转移所有权 |
for item in &collection |
for item in collection.iter() |
不可变借用 |
for item in &mut collection |
for item in collection.iter_mut() |
可变借用 |
1 | // 第一种 |
第一种方式是循环索引,然后通过索引下标去访问集合,第二种方式是直接循环集合中的元素,优劣如下:
- 性能:第一种使用方式中
collection[index]的索引访问,会因为边界检查(Bounds Checking)导致运行时的性能损耗 —— Rust 会检查并确认index是否落在集合内,但是第二种直接迭代的方式就不会触发这种检查,因为编译器会在编译时就完成分析并证明这种访问是合法的 - 安全:第一种方式里对
collection的索引访问是非连续的,存在一定可能性在两次访问之间,collection发生了变化,导致脏数据产生。而第二种直接迭代的方式是连续访问,因此不存在这种风险( 由于所有权限制,在访问过程中,数据并不会发生变化)。
loop:简单的无限循环,需要搭配break跳出
1 | fn main() { |
模式匹配
match和if let
匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
},
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
//match匹配需要穷尽所有的可能,用_表示没有列出的其他可能性(如果没有穷尽可能性的话会报错)
//match的每一个分支都必须是一个表达式,且所有分支的表达式最终返回值的类型必须相同模式绑定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState), // 25美分硬币
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {//这里将枚举类别Coin中的UsState值绑定给state变量
println!("State quarter from {:?}!", state);
25
},
}
}if let匹配
当我们只关注某个特定的值的匹配情况时,可以使用if let匹配代替match
1
2
3
4
5
6
7
8
9
10let v = Some(3u8);
match v {
Some(3) => println!("three"),
_ => (),
}
//if let匹配
if let Some(3) = v {
println!("three");
}matches!()宏
将表达式和模式进行匹配,返回True或者False
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17enum MyEnum {
Foo,
Bar
}
fn main() {
let v = vec![MyEnum::Foo,MyEnum::Bar,MyEnum::Foo];
}
//对v进行过滤,只保留类型为MyEnum::Foo的元素
v.iter().filter(|x| matches!(x, MyEnum::Foo));
//更多例子
let foo = 'f';
assert!(matches!(foo, 'A'..='Z' | 'a'..='z'));
let bar = Some(4);
assert!(matches!(bar, Some(x) if x > 2));match和if let匹配导致的变量遮蔽
尽量不要使用同名变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(age) = age {
println!("匹配出来的age是{}",age);
}
println!("在匹配后,age是{:?}",age);
}
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
match age {
Some(age) => println!("匹配出来的age是{}",age),
_ => ()
}
println!("在匹配后,age是{:?}",age);
}
一些模式适用场景
while let 只要匹配就会一直循环下去
1
2
3
4
5
6
7
8
9
10
11
12// Vec是动态数组
let mut stack = Vec::new();
// 向数组尾部插入元素
stack.push(1);
stack.push(2);
stack.push(3);
// stack.pop从数组尾部弹出元素
while let Some(top) = stack.pop() {
println!("{}", top);
}let和if let
1
2
3
4
5
6let Some(x) = some_option_value;//报错,有可能是None
//let,match,for都需要完全匹配(不可驳匹配)
if let Some(x) = some_option_value {
println!("{}", x);
}//通过,只要有值的情况,其余情况忽略(可驳模式匹配)
全模式列表
用序列语法
..=匹配区间内的值(还是只能用于数字和字符)1
2
3
4
5
6let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}使用模式忽略值
1
2
3
4
5
6
7
8//忽略函数变量
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {}", y);
}
fn main() {
foo(3, 4);
}用
_忽略值和用_s的区别1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s);//会报错,因为s的所有权已经转移给_s了
——————————————————————————
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{:?}", s);//使用下划线本身是不会绑定值的使用
..忽略多个值需要保证没有歧义1
2
3
4
5
6
7
8
9fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {}", second)
},
}
}//报错,编译器无法理解second具体指哪个匹配守卫——为匹配提供额外条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {}", n),
//通过匹配守卫,使得在匹配中也可以正常的使用外部变量,而不用担心变量遮蔽的问题
_ => println!("Default case, x = {:?}", x),
}
println!("at the end: x = {:?}, y = {}", x, y);
}
——————————————————
//匹配守卫的优先级:会作用于所有的匹配项
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}@绑定——提供在限定范围条件下,在分支代码内部使用变量的能力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id_variable @ 3..=7 } => {
println!("Found an id in range: {}", id_variable)
},//@变量绑定,限定范围且绑定变量
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
},//限定了范围,但是这样子只会匹配,而id这个量用不了
Message::Hello { id } => {
println!("Found some other id: {}", id)
},//可以匹配并绑定到id上,但是这样子限制不了范围
}
————————————————
//绑定的同时对变量结构
struct Point {
x: i32,
y: i32,
}
fn main() {
// 绑定新变量 `p`,同时对 `Point` 进行解构
let p @ Point {x: px, y: py } = Point {x: 10, y: 23};
println!("x: {}, y: {}", px, py);
println!("{:?}", p);
let point = Point {x: 10, y: 5};
if let p @ Point {x: 10, y} = point {
println!("x is 10 and y is {} in {:?}", y, p);
} else {
println!("x was not 10 :(");
}
}
方法Method
定义和初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22struct Circle {
x: f64,
y: f64,
radius: f64,
}
impl Circle {
// new是Circle的关联函数,因为它的第一个参数不是self,且new并不是关键字
// 这种方法往往用于初始化当前结构体的实例
fn new(x: f64, y: f64, radius: f64) -> Circle {
Circle {
x: x,
y: y,
radius: radius,
}
}
// Circle的方法,&self表示借用当前的Circle结构体
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
} 这种定义在
impl中且没有self的函数被称之为关联函数: 因为它没有self,不能用f.read()的形式调用,因此它是一个函数而不是方法,它又在impl中,与结构体紧密关联,因此称为关联函数。 因为是函数,所以不能用
.的方式来调用,我们需要用::来调用,例如let sq = Rectangle::new(3, 3);。这个方法位于结构体的命名空间中:::语法用于关联函数和模块创建的命名空间。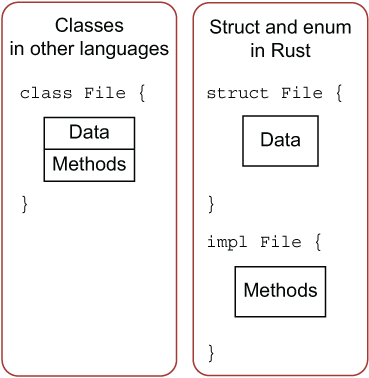
其他的语言往往将类型和方法一起定义,而Rust对这两者的定义是分开的。
self和被实例化类型的关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {//方法名称可以和结构体的名称相同
fn area(&self) -> u32 {
self.width * self.height
}
//self 表示 Rectangle 的所有权转移到该方法中,这种形式用的较少
//&self 表示该方法对 Rectangle 的不可变借用
//&mut self 表示可变借用
}
fn main() {
let rect1 = Rectangle { width: 30, height: 50 };
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}方法和字段同名的好处
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19pub struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
pub fn new(width: u32, height: u32) -> Self {
Rectangle { width, height }
}
pub fn width(&self) -> u32 {
return self.width;
}
}
fn main() {
let rect1 = Rectangle::new(30, 50);
println!("{}", rect1.width());
} 方法和字段同名有助于我们实现访问器,我们可以将
width和height设置为私有属性,而通过pub关键字将Rectangle结构体对应的new方法和width方法设置为公有方法,这样子用户可以通过rect1.width()方法访问到宽度的数据,却无法直接使用rect1.width来访问。Rust中用自动引用/解引用机制代替了C/C++的->运算符
在 C/C++ 语言中,有两个不同的运算符来调用方法:
.直接在对象上调用方法,而->在一个对象的指针上调用方法,这时需要先解引用指针。换句话说,如果object是一个指针,那么object->something()和(*object).something()是一样的。 Rust 并没有一个与
->等效的运算符;相反,Rust 有一个叫 自动引用和解引用的功能。方法调用是 Rust 中少数几个拥有这种行为的地方。 他是这样工作的:当使用
object.something()调用方法时,Rust 会自动为object添加&、&mut或*以便使object与方法签名匹配。也就是说,这些代码是等价的:1
2p1.distance(&p2);
(&p1).distance(&p2); 第一行看起来简洁的多。这种自动引用的行为之所以有效,是因为方法有一个明确的接收者————
self的类型。在给出接收者和方法名的前提下,Rust 可以明确地计算出方法是仅仅读取(&self),做出修改(&mut self)或者是获取所有权(self)。事实上,Rust 对方法接收者的隐式借用让所有权在实践中更友好。
泛型和特征
泛型
代替值的泛型,而不是针对类型的泛型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35//这段代码会报错,因为不同长度的数组在Rust中是不同的类型
fn display_array(arr: [i32; 3]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(arr);
let arr: [i32; 2] = [1, 2];
display_array(arr);
}
//用切片的方式打印任意长度的数组,同时用泛型指代不同的类型
fn display_array<T: std::fmt::Debug>(arr: &[T]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(&arr);
let arr: [i32; 2] = [1, 2];
display_array(&arr);
}
//切片是一种引用,但是有的场景不允许我们使用引用,此时通过const泛型指代不同的长度
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(arr);
let arr: [i32; 2] = [1, 2];
display_array(arr);
}泛型的性能
编译器完成单态化的过程,增加了编译的繁琐程度,也让编译后的文件更大
会对每一个具体用到的类型都生成一份代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//程序编写
let integer = Some(5);
let float = Some(5.0);
//编译后
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}
特征
一组可以被共享的行为,只要满足了特征,就可以做以下的行为。
定义特征
只管定义,而往往不会提供具体的实现
谁满足这个特征,谁来实现具体的方法
1
2
3
4
5
6
7
8
9pub trait Summary {
fn summarize(&self) -> String;//以;结尾 只提供定义
}
pub trait Summary {
fn summarize(&self) -> String { //也可以给一个默认实现
String::from("(Read more...)")
}//可以调用,也可以重载
} 默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。如此,特征可以提供很多有用的功能而只需要实现指定的一小部分内容。例如,我们可以定义
Summary特征,使其具有一个需要实现的summarize_author方法,然后定义一个summarize方法,此方法的默认实现调用summarize_author方法:1
2
3
4
5
6
7pub trait Summary {
fn summarize_author(&self) -> String;//让实现Summary特征的类型具体实现吧
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}实现特征
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25pub trait Summary {
fn summarize(&self) -> String;
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post {//为Post实现Summary特征
fn summarize(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}孤儿规则——特征定义和实现的位置关系
关于特征实现与定义的位置,有一条非常重要的原则:如果你想要为类型
A实现特征T,那么A或者T至少有一个是在当前作用域中定义的! 例如我们可以为上面的Post类型实现标准库中的Display特征,这是因为Post类型定义在当前的作用域中。同时,我们也可以在当前包中为String类型实现Summary特征,因为Summary定义在当前作用域中。 但是你无法在当前作用域中,为
String类型实现Display特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。使用特征作为函数的参数
1
2
3pub fn notify(item: &impl Summary) {//实现了特征Summary的item参数
println!("Breaking news! {}", item.summarize());//可以调用特征对应的方法
}特征约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//接收两个实现了Summary特征的参数,但是不能保证这两个参数的类型相同
pub fn notify(item1: &impl Summary, item2: &impl Summary) {}
//用泛型T指代
//T:Summary要求其实现了特征Summary
pub fn notify<T: Summary>(item1: &T, item2: &T) {}
//多重约束
//这里T被要求同时实现两个特征才行
pub fn notify<T: Summary + Display>(item: &T) {}
//Where约束,主要是用于简化函数的签名,将特征约束写在别处
fn some_function<T, U>(t: &T, u: &U) -> i32
where T: Display + Clone,
U: Clone + Debug
{}函数返回值中的impl Trait
1
2
3
4
5
6
7
8
9fn returns_summarizable() -> impl Summary {
//返回一个实现了Summary特征的类型,具体是什么类型不知道
Weibo {
username: String::from("sunface"),
content: String::from(
"m1 max太厉害了,电脑再也不会卡",
)
}
} 这种
impl Trait形式的返回值,在一种场景下非常非常有用,那就是返回的真实类型非常复杂,你不知道该怎么声明时(毕竟 Rust 要求你必须标出所有的类型),此时就可以用impl Trait的方式简单返回。derive派生特征
在本书中,形如
#[derive(Debug)]的代码已经出现了很多次,这种是一种特征派生语法,被derive标记的对象会自动实现对应的默认特征代码,继承相应的功能。 例如
Debug特征,它有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用println!("{:?}", s)的形式打印该结构体的对象。 再如
Copy特征,它也有一套自动实现的默认代码,当标记到一个类型上时,可以让这个类型自动实现Copy特征,进而可以调用copy方法,进行自我复制。 总之,
derive派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
特征对象
指向了所有实现了某特征的对象,二者之间存在映射关系,可以通过特征对象找到该对象具体的实现方法。
可以通过
&引用或者Box<T>智能指针的方式来创建特征对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39trait Draw {
fn draw(&self) -> String;
}
impl Draw for u8 {
fn draw(&self) -> String {
format!("u8: {}", *self)
}
}
impl Draw for f64 {
fn draw(&self) -> String {
format!("f64: {}", *self)
}
}
// 若 T 实现了 Draw 特征, 则调用该函数时传入的 Box<T> 可以被隐式转换成函数参数签名中的 Box<dyn Draw>
fn draw1(x: Box<dyn Draw>) {
// 由于实现了 Deref 特征,Box 智能指针会自动解引用为它所包裹的值,然后调用该值对应的类型上定义的 `draw` 方法
x.draw();
}
fn draw2(x: &dyn Draw) {
x.draw();
}
fn main() {
let x = 1.1f64;
// do_something(&x);
let y = 8u8;
// x 和 y 的类型 T 都实现了 `Draw` 特征,因为 Box<T> 可以在函数调用时隐式地被转换为特征对象 Box<dyn Draw>
// 基于 x 的值创建一个 Box<f64> 类型的智能指针,指针指向的数据被放置在了堆上
draw1(Box::new(x));
// 基于 y 的值创建一个 Box<u8> 类型的智能指针
draw1(Box::new(y));
draw2(&x);
draw2(&y);
}draw1函数的参数是Box<dyn Draw>形式的特征对象,该特征对象是通过Box::new(x)的方式创建的draw2函数的参数是&dyn Draw形式的特征对象,该特征对象是通过&x的方式创建的dyn关键字只用在特征对象的类型声明上,在创建时无需使用dyn
可以通过特征对象来代表具体的泛型。
使用泛型的实现和特征对象的对比
1
2
3
4
5
6
7
8
9
10
11
12pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where T: Draw {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
} 上面的
Screen的列表中,存储了类型为T的元素,然后在Screen中使用特征约束让T实现了Draw特征,进而可以调用draw方法。 但是这种写法限制了
Screen实例的Vec<T>中的每个元素必须是Button类型或者全是SelectBox类型。如果只需要同质(相同类型)集合,更倾向于采用泛型+特征约束这种写法,因其实现更清晰,且性能更好(特征对象,需要在运行时从vtable动态查找需要调用的方法)。特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是
Self - 方法没有任何泛型参数
对象安全对于特征对象是必须的,因为一旦有了特征对象,就不再需要知道实现该特征的具体类型是什么了。如果特征方法返回了具体的
Self类型,但是特征对象忘记了其真正的类型,那这个Self就非常尴尬,因为没人知道它是谁了。但是对于泛型类型参数来说,当使用特征时其会放入具体的类型参数:此具体类型变成了实现该特征的类型的一部分。而当使用特征对象时其具体类型被抹去了,故而无从得知放入泛型参数类型到底是什么。标准库中的
Clone特征就不符合对象安全的要求:1
2
3pub trait Clone {
fn clone(&self) -> Self;
}因为它的其中一个方法,返回了
Self类型,因此它是对象不安全的。- 方法的返回类型不能是
特征对象的动态分发
静态分发:编译器会为每一个泛型参数对应的具体类型生成一份代码
动态分发:直到运行时,才能确定需要调用什么方法。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。

- 特征对象大小不固定:这是因为,对于特征
Draw,类型Button可以实现特征Draw,类型SelectBox也可以实现特征Draw,因此特征没有固定大小 - 几乎总是使用特征对象的引用方式,如
&dyn Draw和Box<dyn Draw>- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例、类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
简而言之,当类型
Button实现了特征Draw时,类型Button的实例对象btn可以当作特征Draw的特征对象类型来使用,btn中保存了作为特征对象的数据指针(指向类型Button的实例数据)和行为指针(指向vtable)。一定要注意,此时的
btn是Draw的特征对象的实例,而不再是具体类型Button的实例,而且btn的vtable只包含了实现自特征Draw的那些方法(比如draw),因此btn只能调用实现于特征Draw的draw方法,而不能调用类型Button本身实现的方法和类型Button实现于其他特征的方法。也就是说,btn是哪个特征对象的实例,它的vtable中就包含了该特征的方法。- 特征对象大小不固定:这是因为,对于特征
特征进阶内容
关联类型
在特征定义的语句块中,声明一个自定义类型,这样就可以在特征中使用这个类型。
1
2
3
4
5pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
Rustlings习题整理
map()的用法
1 | fn vec_map(v: &Vec<i32>) -> Vec<i32> { |
字符串和切片操作
1 | fn trim_me(input: &str) -> String { |
判断字符串和字符串切片的类型
1 | fn string_slice(arg: &str) { |
| clone() | to_owned() | |
|---|---|---|
| T | T -> T | T -> T |
| &T | &T -> &T | &T -> T |
模块use
1 | mod delicious_snacks { |
比赛统计
1 | use std::collections::HashMap; |
quiz2
首先要观察代码判断其类型,随后用match表达式匹配枚举类型,做出相应的处理
1 | pub enum Command { |
从Option中取出值
1 | //如果你确定Option中是有值的,可以使用unwrap()方法直接取出来 |
Option的类型问题
1 | let range = 10; |
所有权的问题
1 | struct Point { |
? 表达式
1 | impl ParsePosNonzeroError { |
为动态数组Vector实现特征
1 | trait AppendBar { |
特征约束代替类型
1 | pub trait Licensed { |
#[should_panic]
1 | struct Rectangle { |
迭代器方法
1 | pub fn capitalize_first(input: &str) -> String { |
宏
1 | //宏的定义要在使用之前 |
Rcore实验感想
写在前面
由于实验要求不能够贴代码,因此本报告重点就是日记这种了……
会简单的讲一下过程
Lab3
看了一下自己写的东西……玛德我原本也贴了不少代码
行吧……那就放些记录性的东西
……
报错挺多的,反正就照着编译器一个一个来吧……
类型错误……

missing documentations for functions
不写注释也不行 笑

Lab4
重写sys_get_time和sys_task_info
先看看原本的sys_get_time是如何实现的?
对指针*ts所指向的内存空间赋值时间信息,在引入虚存之前应用空间和内核空间之间不存在隔离,二者都可以直接访问到*ts所在位置。在引入虚存之后,每个应用以及内核本身都有独立的地址空间,没办法访问了。
因此我们需要想办法,使得OS能够访问到应用所在的位置,需要完成二者地址的翻译。
……
和mmap那个题目一样,sys_get_time以及sys_task_info也是需要在当前任务下才行
为什么突然写回来了呢……(因为在线CI测了sys_get_time还有sys_task_info 发现自己写的根本就不对
我知道哪里不行了 我的实现没问题 搞得我还重写了一次
每次执行系统调用的时候忘记调用add_syscall_num
mmap
insert_frame_area函数是比较值得参考的一个函数
不仅仅是函数实现的功能类似,用法也很值得学习
……
随后就是漫长的调试……
这里注意到特殊的一行
[kernel] PageFault in application, bad addr = {:#x}, bad instruction = {:#x}, kernel killed it.
先找到这行输出是哪里来的,发现在Trap_handler方法里面
然后再考虑,发现其实我的程序连mmap0都没正常跑完
但是正确分配了页面,要不然就不会有start_va:0x10000000~end_va:0x10001000 map_perm:0x16输出
这里的0x16完全没问题(之前看成10进制了)
0001 0110 代表U,W,R被置位 而测试用例mmap0给的是3 也就是011 也是对应W,R

妈的 我知道怎么搞了 之所以会不断出现The Page you wanted has been alloced to others的报错信息是因为之前在sys_mmap方法中对MemorySet中mmap()的调用是这样子的
1 | // 获取内核实例 取得所有权完成分配(这样不对 你并没有找到实际你要分配的位置) 实际上你是给内核多次分配了 所以才这样子报错 |
事实上应该找到当前运行的任务,只有当前运行的任务是知道自己的地址空间信息的,具体在TCB里面有一项memory_set
这里也走了点弯路 一开始我的想法是在TaskControlBlock中实现一个get_current_tasks_area(类似于之前get_tasks_start_time一样拿到时间)拿到memory_set的所有权或者引用之后,在sys_mmap()里面再用得到的memory_set来调用(我个人感觉主要还是仿照了前面代码的思路,就非要拿到一个类似于KERNEL_SPACE的地址空间,事实上没必要)
……
实现了mmap之后munmap就比较简单了
这里写一个点 关于munmap的最后一个测试用例
下面给一个比较滑头的办法 检查一下是不是页对齐就行(start硬编码写死了 所以其实你怎么写都差不多
1 | // YOUR JOB: Implement munmap. |
按理说应该是实现一个检测解除映射范围和现有的映射区域是否完全一致的方法
明天再想吧……先看看能不能过在线CI
懂了 在线CI看不到报错 我就说为什么lab4的测例全过了assert断言还是不行

这里可以看到比较详细的信息
这里记录一下回退的点 本地执行CI之后需要删除一些未跟踪的文件
1 | git clean -f 删除未跟踪的文件(不包括目录) |

解决了 太sb了
Lab5
之前的测例实现过程
经典内容……
注意一个点 在Lab5里面把TaskManager拆分成了TaskManager和processor两个数据结构
不过他们对进程信息的获取还是通过TaskControlBlock
关于初始化信息补全
忘记记录了……之前的测例实现基本就是cv,注意放到正确的数据结构里面重新实现一次就行
遇到一个新问题


这个Write系统调用莫名其妙多出这么多次数
我决定在增加系统调用的方法中加一行调试,打印一下系统调用编号
1 | /// 添加系统调用 |

出现了奇怪的输出
每次键入一个字符 对应着read waitpid yield write系统调用都+1了
虽然输出流打断了我的输入流 但是功能应该还是正常的 只是我没有键入回车键 所以用户程序没有被正常执行起来
应该是前面的实现有问题(
在父进程通过fork()系统调用创建子进程的时候,子进程不应该继承父进程的系统调用次数和开始时间
系统调用次数应该直接初始化为0才对(重新算
1 | start_time:get_time_us() / 1000, |
ok 这里可以过了
现在又有新问题了 还是ch3_taskinfo的测例

好像还是过不了 但是断言错误的次数确实是减少了……
好像是用println!()打印调试信息的问题,如果去掉的话Write系统调用的次数就不会增加

还真是 回头看了一下console.rs里面对println!()的实现 很明显是基于Write的
不然平白无故你的OS怎么能打印东西的……把这事情给忘记了 笑
先一次性把时间信息都打印下来吧 后面就不看了

我切换分支到ch4重新跑一下这个用例 t1=43 t2=544 t3=544 info.time=501是没有问题的
睡了 明天再说
……睡觉的时候突然想到Lab5的run_tasks()方法应该是没有修改 所以没有把时间信息记录下来
没错 就是在此处补一个记录时间的功能就ok了
Spawn系统调用实现
一遍过 感觉还是比较简单的…… 主要就是fork() new() 还有exec()的仿写
注意对parent字段特殊处理
spawn出来的进程的父进程应该为当前运行的进程
Stride调度
首先是在TCB里面增加进程优先级的字段priority和步长调度的参考数据stride
其实是对初始化信息的补全
一开始我是看到的processor.rs的run_tasks()模块,里面有一个fetch_tasks()的过程,取得目前应该运行的任务。但是fetch_tasks()是局限在Task Manager内部,缺少Processor结构,也就是当下的任务状态拿不到(就是有一种可能性是当下正在运行的进程stride还是最小)
然后继续看源码
感觉这几个函数之间的关系有点懵
……
后面感觉还是得在add位置实现,也就是fetch还是从队头把进程取出来,但是在add增加进程的时候维护所有进程的stride顺序
Lab6
之前的测例
首先就是要通过之前的测例 sys_spawn和之前会有一些区别
主要就是获得程序数据的方式有差异
本实验测试点

差最后一个
???
byd什么勾八
怎么实验还不能复现的 本地跑差一个点 在线ci全过了是吧

Lab8
如果启用死锁检测功能的话,主要的检测就是在上锁相关的操作检测是否合法
这里有个困惑的点,就是一开始没搞懂资源到底是什么
其实就是各类的lock……能够得到锁 就代表得到了某个特定的资源
初始化是一门玄学……
需要自己设置好两个常量MAX_THREADS和MAX_RESOURES的数量,代表当前可以获得的资源
……
一些问题

就卡在这里了,也不知道怎么回事
gpt问了一下
……死锁了 我就说为什么寄了