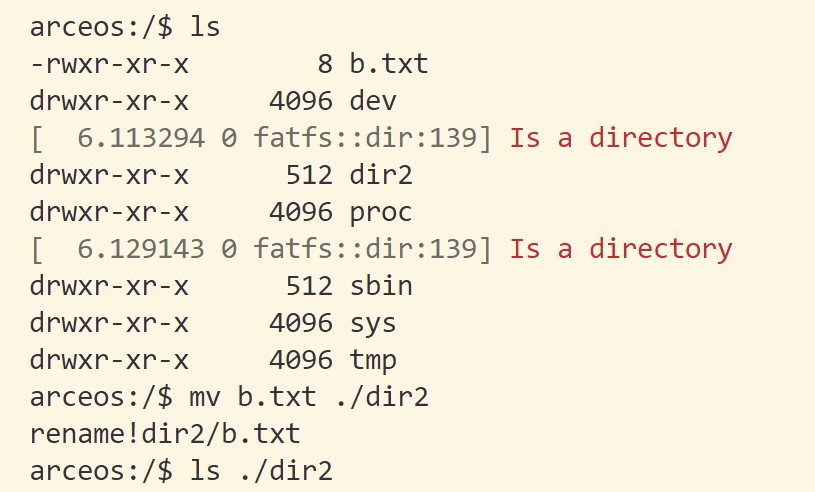
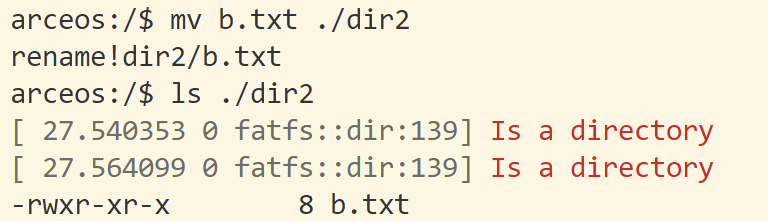
课后练习:bump内存分配算法 主要代码在alt_axalloc里,与axalloc里不同,它在初始化时内部只有一个分配器,并把所有物理内存都分配给它。这个分配器同时实现字节分配器和页分配器的trait,但分配内存时只使用字节分配器里的alloc,页分配器里的alloc_pages没用。
1 2 3 #[cfg_attr(all(target_os = "none" , not(test)), global_allocator)] static GLOBAL_ALLOCATOR: GlobalAllocator = GlobalAllocator::new();
要想正常实现动态内存分配,首先要用#[global_allocator]属实告诉编译器使用哪个分配器实例作为全局分配器。
1 2 3 4 unsafe impl GlobalAlloc for GlobalAllocator { unsafe fn alloc self , layout: Layout) -> *mut u8 {...} unsafe fn dealloc self , ptr: *mut u8 , layout: Layout) {...}
然后需要为自定义的分配器实现GlobalAlloc trait里的alloc和dealloc方法。查找调用关系:GlonalAlloc::alloc -> GlobalAllocator::alloc -> EarlyAllocator:alloc -> ByteAllocator::alloc,dealloc同理。因此主要修改的代码为modules/bump_allocator里的EarlyAllocator里的ByteAllocator trait的alloca和dealloc方法。
bump的实现参考Writing an OS in Rust : Allocator Designs 分配器设计与实现-CSDN博客
lab1:针对应用场景,优化内存分配器组件 分配器内存的初始化和申请 总共可用于分配的堆内存大小是多少?
1 2 3 4 5 6 7 8 9 10 11 12 13 ... for r in memory_regions() { if r.flags.contains(MemRegionFlags::FREE) && r.paddr == max_region_paddr { axalloc::global_init(phys_to_virt(r.paddr).as_usize(), r.size); break ; } } for r in memory_regions() { if r.flags.contains(MemRegionFlags::FREE) && r.paddr != max_region_paddr { axalloc::global_add_memory(phys_to_virt(r.paddr).as_usize(), r.size) .expect("add heap memory region failed" ); } }
由上述代码可得标记为free的内存区域都分配给内存分配器使用。
memory_regions -> platform_regions,当前平台为riscv64
1 2 3 4 5 pub (crate ) fn platform_regions impl Iterator <Item = MemRegion> { crate::mem::default_free_regions().chain(crate::mem::default_mmio_regions()) }
default_free_regions里标记为free,块起始地址为_ekernel,结束地址为PHYS_MEMORY_END。
1 pub const PHYS_MEMORY_END: usize = PHYS_MEMORY_BASE + PHYS_MEMORY_SIZE;
定义在config.rs里,查找可得物理内存大小为128m,根据128m查找可得由来为qemu启动时设置的物理内存参数128m。运行时添加LOG=debug参加也可以在输出信息里直观看到分配给分配器的内存,initialize global allocator at: [0xf
1 2 3 4 5 6 7 8 9 let old_size = balloc.total_bytes(); let expand_size = old_size .max(layout.size()) .next_power_of_two() .max(PAGE_SIZE); let heap_ptr = match self .alloc_pages(expand_size / PAGE_SIZE, PAGE_SIZE) { Ok (ptr) => ptr, Err (e) => panic! ("Bumb: {:?}." , e),}
初始分给字节分配器32KB,当alloc内存不够时,由页分配器再分配页倍数大小的内存。注意分配时要求的内存大小和字节分配器的total_bytes函数返回的值有关,若total_bytes实现不当返回值过大,则一次要求的内存会远远超过实际需要的内存,造成字节分配器分配内存失败,提前终止迭代(我实现的total_bytes返回的是可分配的内存大小,这样每次申请的内存就和需要的内存接近了)。
应用程序内存的申请和释放 通过在alloc和dealloc函数里log,分析堆上内存的分配和释放时机,主要和三个变量有关:pool、items和a。a类型是Vec<u8>,可以简单看作是一个内部地址连续的内存块。items和pool类型是Vec<Vec<u8>>,可以看成是存储Vec胖指针的集合。
在主循环里的每一轮先调用alloc_pass申请大量内存,连续申请$a_n\quad (n = 0, 1, 2, \ldots, 14)+\delta$大小的内存块,其中$\delta$表示轮数,$a_n$是首项为32,最大项为524288的以2为公比等比数列,用等比数列的求和公式可得一轮申请的内存块之和大约为1MB。每申请一个内存块便push进items里,items扩容是翻倍,初始申请$4\times32$B大小的内存,扩容的时候先申请$8\times32$B大小的内存,再释放之前申请的。因为一轮循环里总共申请15块内存,items最大容量为$16\times32=384$B。
alloc_pass结束后通过free_pass函数连续释放掉偶数项的内存块。然后将items append进pool里,每一轮循环结束pool就增加$7\times24=168$B大小,pool每次扩容时同样会释放掉之前占用的内存。pool的作用域是整个循环,pool本身及对应奇数项占用的内存在循环结束后才释放,随着循环次数的增加,占用内存越来越大,直到耗光128MB总内存。
我们可以粗略进行分析,如果忽视掉pool和items变量本身的大小(使用bumb算法,items变量最多占用$96+192+384=672$B,pool最多占用$168\times\sum_{n=1}^\delta k$ B)和每次循环递增的$\delta$,每一轮循环释放掉偶数项的总和约为$\frac{2}{3}$ MB,那么理论上最大循环次数约为$128\times3=384$。注意这是在保留奇数项内容正确性,不对奇数项所占内存进行覆写的情况下。
自定义内存分配器的设计 根据上面的分析可知,items能占用的最大空间是有限的,且在每轮循环结束后会全部释放,适合在固定大小的内存区域里使用bumb算法管理。偶数项所占用的内存空间随着$\delta$变化非常缓慢,且同样也会在每轮循环结束前全部释放,同样适合在固定固定大小的内存区域里使用bumb算法管理。同时,items和偶数项都会在全部释放完后再重新分配,所以items和偶数项可以在一块内存里用bumb算法管理。pool和奇数项占用空间是持续增加的,pool会释放,奇数项不会,但为了简单处理一样用bumb算法管理(pool占用内存在轮数较大时存在较大的优化空间)。
分配器初始可用内存为32KB,当分配不够时再向页分配器申请扩容。为了方便划分区域进行管理,在申请第0轮第0项大小的内存时,我们在alloc函数里返回nomemory错误,并在total_bytes函数返回items和偶数项之和的大小来申请足够的内存。在不覆写奇数项情况下,理论最大轮数大约为384,偶数项之和每一项增加15,所以items和偶数项之和为$672+699040+384\times15=704932$B大小,这样分配器初始就能申请向上取整2的n次方和4096的倍数1048576B大小的内存使用。
由初始地址开始,大小为704932B大小的内存区域用来进行items和偶数项的分配和释放。剩下的区域用来进行pool和奇数项的分配和释放,随着奇数项的增加再向页分配器申请新的扩容,直至最终内存耗尽,所有区域内部均使用bumb算法进行管理。注意,每一轮循环里items和偶数项都会在申请完毕后全部释放,奇数项在整个循环期间不释放,所以用bumb管理是合适的。但pool在循环内是会释放的,且随着轮数的增加,空闲内存大小不容忽视,未来可以用更高效的算法来管理pool的内存,还能进一步增加轮数。
课后练习: 实现最简单的Hypervisor,响应VM_EXIT常见情况 先从simple_hv/src/main.rs里的main函数开始运行,此时处于host域。用new_user_aspace创建地址空间,load_vm_image加载要在guest域里运行的内核文件。prepare_guest_context伪造guest上下文件,设置初始特权级为S,sepc值为VM_ENTRY(内核文件的入口地址)。
1 2 3 4 5 6 7 8 9 10 while !run_guest(&mut ctx) {} fn run_guest mut VmCpuRegisters) -> bool { unsafe { _run_guest(ctx); } vmexit_handler(ctx) }
while循环里将会启动guest并等待它退出。_run_guest在guest.S里,主要功能是保存host上下文和恢复guest上下文,具体细节下次课会讲,最后sret跳转到sepc里的地址,切换到了guest里的内核执行。触发中断后会跳转到_guest_exit里执行,执行完后会进入vmexit_handler函数里执行(执行完_guest_exit后会接着执行_restore_csrs,里面恢复了ra寄存器的值,并在最后使用ret返回到调用_run_guest的下一行)。
1 2 3 4 5 6 7 8 9 10 unsafe extern "C" fn _start core::arch::asm!( "csrr a1, mhartid" , "ld a0, 64(zero)" , "li a7, 8" , "ecall" , options(noreturn) ) }
内核程序如上所示,当执行csrr a1, mhartid时,VS态写入了M态的寄存器,触发非法指令异常。ld 10, 64(zero),写入了非法内存地址,触发页错误异常。ecall指令超出VS态执行权限,触发异常。
先触发非法指令异常,在异常函数处理中,我们先需要将sepc+=4(一条指令长度为4字节),以便下次_run_guest里的sret能正确跳转到下条指令执行。然后返回false,以便while循环不退出,继续执行run_guest函数。
总结 这个阶段学得不是很扎实,很多内容都只看了视频,没有完成课后练习,等后面还要进一步回锅。